本稿は、Kubernetesのアドベントカレンダーその2 の23日目の記事です。
概要
Kubernetesの導入検討をする上で、有識者の同僚からpopeye存在を教えてもらったので遊んでみました。
popeyeとは
Kubernetesのクラスタとその上で動く各種リソースの設定のスキャニングツールです。
親しいツールとしてdigitalocean/clusterlint とかもあります。
ロゴが懐かしい。

インストール
ローカル実行の場合
Mac OSXの場合homebrewでもインストールできますが、今回はgo installで入れます。
(公式のInstallationママ)
git clone https://github.com/derailed/popeye
cd popeye
go install
Podとして実行する場合
ローカルや操作用サーバからコマンドで実行する他、Podとして実行することも可能です。
実行用のサンプルYAMLがpopeye/k8s/popeye/にあります。
※実行するとpopeye用にNamespace、各種情報を取得するためのサビアカ&ロール、定期実行用のCronJobが登録されるので注意。
# (popeyeディレクトリ内で)
kubectl apply -f k8s/popeye/ns.yml && kubectl apply -f k8s/popeye
CronJob、サビアカ・ロール用のサンプルYAMLの中身は下記。
用途にもよりますが、日中に複数回リリースをするようなことがないケースは日時や逐次実行でも良いかなという感じ。
デプロイ後に自動で走らせてレポートするなどでも良さそうですね。
- cronjob.yml
---
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: popeye
namespace: popeye
spec:
schedule: "* */1 * * *"
concurrencyPolicy: Forbid
jobTemplate:
spec:
template:
spec:
serviceAccountName: popeye
restartPolicy: OnFailure
containers:
- name: popeye
image: quay.io/derailed/popeye:v0.3.6
imagePullPolicy: IfNotPresent
command: ["/bin/popeye"]
args:
- -f
- /etc/config/popeye/spinach.yml
- -o
- yaml
resources:
limits:
cpu: 500m
memory: 100Mi
volumeMounts:
- name: spinach
mountPath: /etc/config/popeye
volumes:
- name: spinach
configMap:
name: popeye
items:
- key: spinach
path: spinach.yml
- rbac.yml
---
# ServiceAccount definition for the CLI.
apiVersion: v1
kind: ServiceAccount
metadata:
name: popeye
namespace: popeye
---
# Popeye needs get/list access on the following Kubernetes resources.
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: popeye
rules:
- apiGroups: [""]
resources:
- configmaps
- deployments
- endpoints
- horizontalpodautoscalers
- namespaces
- nodes
- persistentvolumes
- persistentvolumeclaims
- pods
- secrets
- serviceaccounts
- services
- statefulsets
verbs: ["get", "list"]
- apiGroups: ["rbac.authorization.k8s.io"]
resources:
- clusterroles
- clusterrolebindings
- roles
- rolebindings
verbs: ["get", "list"]
- apiGroups: ["metrics.k8s.io"]
resources:
- pods
- nodes
verbs: ["get", "list"]
---
# ClusterRoleBinding to ties Popeye with the cluster
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: popeye
subjects:
- kind: ServiceAccount
name: popeye
namespace: popeye
roleRef:
kind: ClusterRole
name: popeye
apiGroup: rbac.authorization.k8s.io
実行してみる
事前準備(kubernetes、pod)
今回は適当にGKEで立てて、アプリケーションは自前のRe;dashを利用しました。
(この辺の構築手順は省略)
popeyeの実行
- コマンド
popeye
リソースごとNodeなら no 、Namespaceなら ns など略称が用意されており、特定のリソースにのみスキャンすることも可能。略称全量はREADME.md参照のこと。
popeye -s ns
実行結果
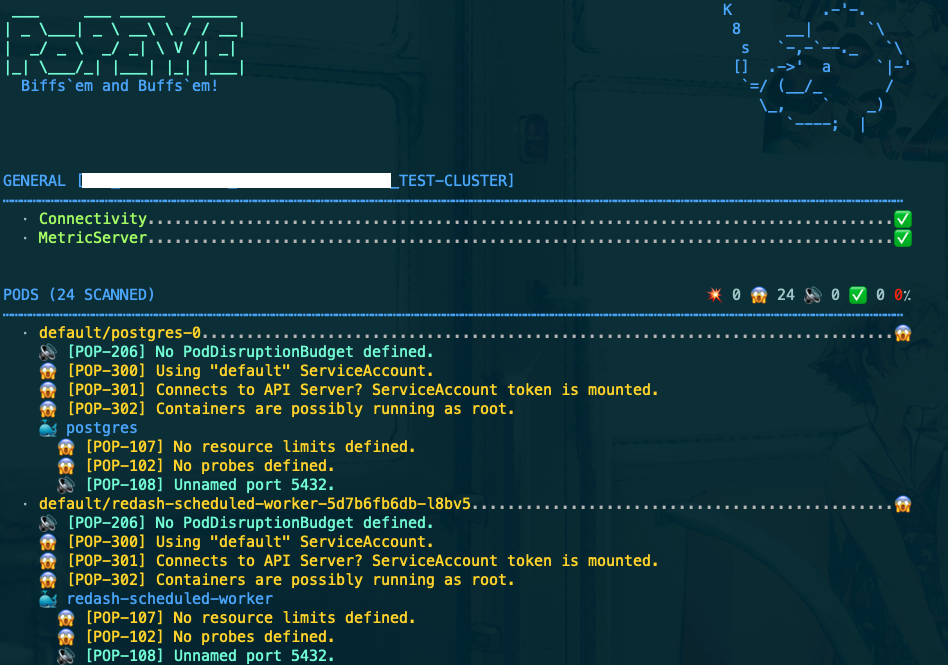
実行すると上図のように診断結果が表示されます。emojiや文字色で直感的にマズい部分とそうでない部分が一瞥できたり、各Podごと構造化されて表示されるが嬉しいですね。
指摘されているのは defaultサービスアカウントを使っている 、 リソースリミットが指定されていない
といったよくあるやつ。
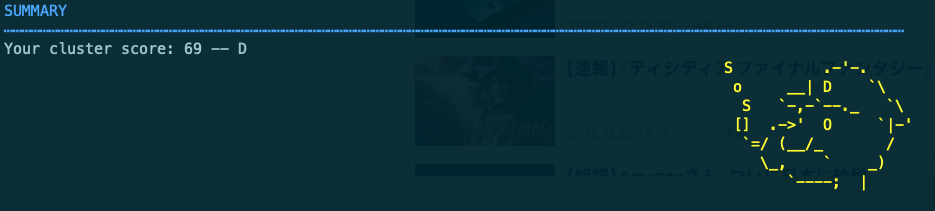
最下部には下記図のように全体評価も表示されます。評価はA〜Fの6段階なので思ったより悪くない(悪い)。
Logoの方にもグレードが載ってる他、グレードによって色が変わっていたり、何気なくパイプの煙がk8sからSOSと変わっていたり、目を見開いていたりと不安になってきて良いです。
ちなみにSOSとなるボーダーラインは70点。
指摘とコードの対応、全体評価に寄与する重要度は popeye/internal/issues/codes.go に定義されており、ContainerやPod、Securityなどのジャンルによって一桁目(1000番台は二桁目まで)が決まるようになっているようです。
popeyeを利用する前段として、この各項目に目を通してベストプラクティスを学んでおく必要がありそうですね。
# Container
100:
message: Untagged docker image in use
severity: 3
101:
message: Image tagged "latest" in use
severity: 2
102:
message: No probes defined
severity: 2
103:
message: No liveness probe
severity: 2
104:
message: No readiness probe
severity: 2
105:
message: "%s probe uses a port#, prefer a named port"
severity: 1
106:
message: No resources defined
severity: 2
107:
message: No resource limits defined
severity: 2
108:
message: "Unnamed port %d"
severity: 1
109:
message: CPU Current/Request (%s/%s) reached user %d%% threshold (%d%%)
severity: 2
110:
message: Memory Current/Request (%s/%s) reached user %d%% threshold (%d%%)
severity: 2
111:
message: CPU Current/Limit (%s/%s) reached user %d%% threshold (%d%%)
severity: 3
112:
message: Memory Current/Limit (%s/%s) reached user %d%% threshold (%d%%)
severity: 3
# -------------------------------------------------------------------------
# Pod
200:
message: Pod is terminating [%d/%d]
severity: 2
201:
message: Pod is terminating [%d/%d] %s
severity: 2
202:
message: Pod is waiting [%d/%d]
severity: 3
203:
message: Pod is waiting [%d/%d] %s
severity: 3
204:
message: Pod is not ready [%d/%d]
severity: 3
205:
message: Pod was restarted (%d) %s
severity: 2
206:
message: No PodDisruptionBudget defined
severity: 1
207:
message: Pod is in an unhappy phase (%s)
severity: 3
# -------------------------------------------------------------------------
# Security
300:
message: Using "default" ServiceAccount
severity: 2
301:
message: Connects to API Server? ServiceAccount token is mounted
severity: 2
302:
message: Containers are possibly running as root
severity: 2
303:
message: Do you mean it? ServiceAccount is automounting APIServer credentials
severity: 2
304:
message: References a secret "%s" which does not exist
severity: 3
305:
message: References a docker-image "%s" pull secret which does not exist
severity: 3
# -------------------------------------------------------------------------
# General
400:
message: Used? Unable to locate resource reference
severity: 1
401:
message: Key "%s" used? Unable to locate key reference
severity: 1
402:
message: No metric-server detected %v
severity: 1
403:
message: Deprecated %s API group "%s". Use "%s" instead
severity: 2
404:
message: Deprecation check failed. %v
severity: 1
405:
message: Is this a jurassic cluster? Might want to upgrade K8s a bit
severity: 2
406:
message: K8s version OK
severity: 0
# -------------------------------------------------------------------------
# Deployment + StatefulSet
500:
message: Zero scale detected
severity: 2
501:
message: "Used? No available replicas found"
severity: 2
502:
message: "ReplicaSet collisions detected (%d)"
severity: 3
503:
message: "At current load, CPU under allocated. Current:%s vs Requested:%s (%s)"
severity: 2
504:
message: "At current load, CPU over allocated. Current:%s vs Requested:%s (%s)"
severity: 2
505:
message: "At current load, Memory under allocated. Current:%s vs Requested:%s (%s)"
severity: 2
506:
message: "At current load, Memory over allocated. Current:%s vs Requested:%s (%s)"
severity: 2
# HPA
600:
message: HPA %s references a Deployment %s which does not exist
severity: 3
601:
message: HPA %s references a StatefulSet %s which does not exist
severity: 3
602:
message: Replicas (%d/%d) at burst will match/exceed cluster CPU(%s) capacity by %s
severity: 2
603:
message: Replicas (%d/%d) at burst will match/exceed cluster memory(%s) capacity by %s
severity: 2
604:
message: If ALL HPAs triggered, %s will match/exceed cluster CPU(%s) capacity by %s
severity: 2
605:
message: If ALL HPAs triggered, %s will match/exceed cluster memory(%s) capacity by %s
severity: 2
# -------------------------------------------------------------------------
# Node
700:
message: Found taint "%s" but no pod can tolerate
severity: 2
701:
message: Node is in an unknown condition
severity: 3
** 702:
message: Node is not in ready state
severity: 3
703:
message: Out of disk space
severity: 3
704:
message: Insuficient memory
severity: 2
705:
message: Insuficient disk space
severity: 2
706:
message: Insuficient PIDS on Node
severity: 3
707:
message: No network configured on node
severity: 3
708:
message: No node metrics available
severity: 1
709:
message: CPU threshold (%d%%) reached %d%%
severity: 2
710:
message: Memory threshold (%d%%) reached %d%%
severity: 2
# -------------------------------------------------------------------------
# Namespace
800:
message: Namespace is inactive
severity: 3
# PodDisruptionBudget
900:
message: Used? No pods match selector
severity: 2
901:
message: MinAvailable (%d) is greater than the number of pods(%d) currently running
severity: 2
1000:
message: Available
severity: 1
1001:
message: Pending volume detected
severity: 3
1002:
message: Lost volume detected
severity: 3
1003:
message: Pending claim detected
severity: 3
1004:
message: Lost claim detected
severity: 3
# -------------------------------------------------------------------------
# Service
1100:
message: No pods match service selector
severity: 3
1101:
message: Skip ports check. No explicit ports detected on pod %s
severity: 1
1102:
message: "Use of target port #%s for service port %s. Prefer named port"
severity: 1
1103:
message: Type Loadbalancer detected. Could be expensive
severity: 1
1104:
message: Do you mean it? Type NodePort detected
severity: 1
1105:
message: No associated endpoints
severity: 3
# -------------------------------------------------------------------------
# NetworkPolicies
1200:
message: No pods match %s pod selector
severity: 2
1201:
message: No namespaces match %s namespace selector
severity: 2
所感
サクッとインストールして使えるし、継続実行の仕組みもベースが提供されているので、とりあえずデプロイ前に通しておくツールとしていい感じだなぁと。
ただ、前述もしましたが、clusterlintなどと同様にcodes.goを読んでベストプラクティスを理解した上で、表示された指摘が自分たちの環境としてMUSTなのかWANTなのかはある程度決めて使うべきかなと思いました。
余談
コマンドそのものが失敗した場合にもロゴが出てきます。かわいい。
(DOH はシンプソンズのホーマーとかを思い出しますね。)