概要
Unity 3D で Ray や OnTriggerEnter を使って視線・視界に入った!という状況を実現している場合に限り、障害物があった場合の処理を軽減する考え方の1つを紹介する
設計的な話が中心でコード的な内容は薄めなので、各人のコードに沿った形でイメージしてほしい
結論
視界に入ったかどうかを判断する点(頂点)を GameObject ごとに設定する
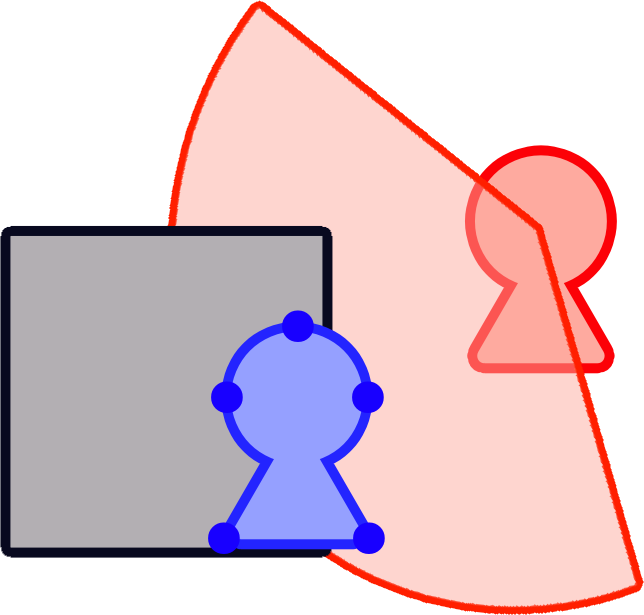
※青い人型を自キャラ、赤い人型を敵キャラ、灰色の四角形を障害物、赤い扇形を敵キャラの視界として話を進める
コードだと以下のスクリプトを GameObject ごとに AddComponent するイメージ
public class Body : MonoBehaviour
{
[SerializeField] List<Vector3> edgeVertexes;
public List<Vector3> EdgeVertexes => edgeVertexes;
}
背景
なぜ GameObject ごとに頂点を設定するような面倒な手順を踏むのか?
それは視界・視線の処理の仕様による
以下のように障害物に完全に隠れている状態は発見されず、半分以上見えている状態は発見されるのは言わずもがなだと思う


問題は以下のようにチラ見えしている場合である
(敵キャラが奥側、自キャラが手前側にいるとする)
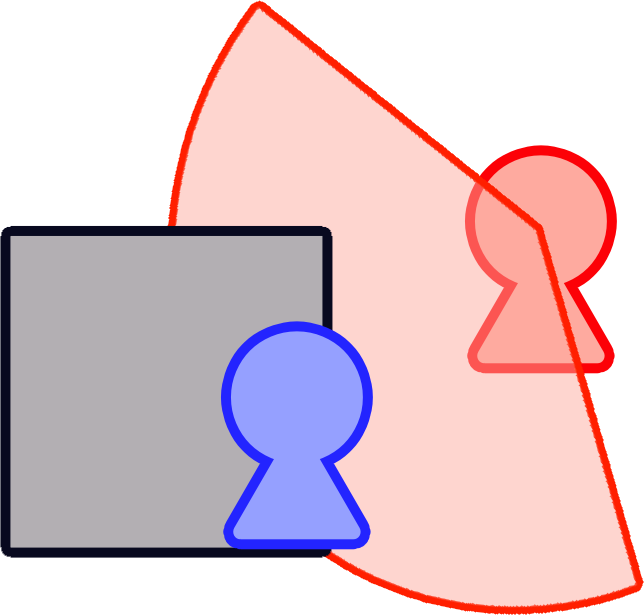
チラ見えしている場合でも自キャラの視線や自キャラの基準となる座標が隠れている場合に 見つかっていない判定にする仕様であれば この記事は役に立たないので普通に Ray を使って判定すればよい
// 敵の視界
public class EnemySight : MonoBehaviour
{
// 視線の原点を示す座標
[SerializeField] private Vector3 eyeCoordinate;
// 視界となるゲームオブジェクトに滞在している GameObject だけ検査する
public void OnTriggerStay(Collider other)
{
var something = other.gameObject;
if (!something.CompareTag("Player")) { return; }
if (!Physics.Raycast(eyeCoordinate.transform.position, something.transform.position, out RaycastHit hitinfo, Mathf.Infinity))
{
return;
}
if (hitinfo.collider.gameObject.CompareTag("Player"))
{
UnityEngine.Debug.Log("見ぃ〜つっけた!");
}
}
}
今回僕が実装した視線・視界の仕様は少しでも見えていたら敵は自キャラを検知するという仕様にしたため、結論に書いた面倒な対応が必要になった
解決方法
なぜ上記したコードではダメなのか?
問題は以下の行である
if (!Physics.Raycast(eyeCoordinate.transform.position, something.transform.position, out RaycastHit hitinfo, Mathf.Infinity))
何が問題かというと、 something.transform.position は発見した GameObject の基準となる position である
例えば、以下のように自キャラの基準となる position が青い点だったとする
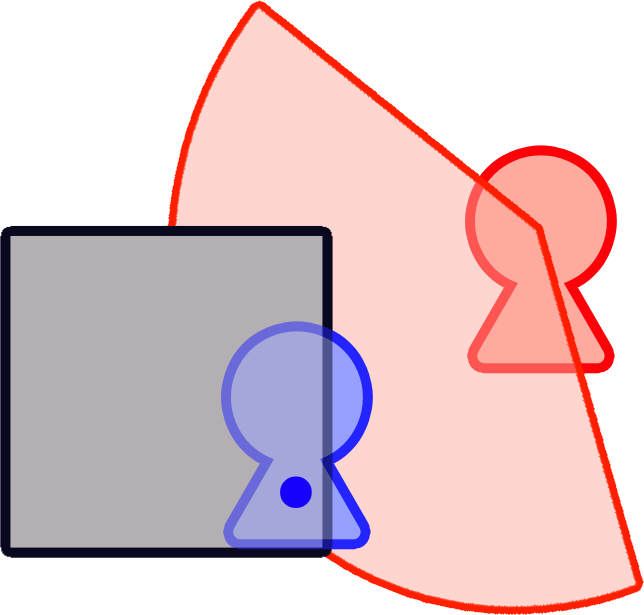
この場合、単純に Ray を飛ばすと、敵キャラが奥側、自キャラが手前側にいる前提だったとき
青い点より先に灰色の障害物のオブジェクトに Ray が当たってしまい、自キャラは見つからなかった判定になる場合がある(見えてるのに)
もちろん厳密にやるなら敵の視界に何かが滞在していれば視線から視界の端に向けて全探索かければ発見することができる
が、その対応は処理負荷がやばすぎる
それでなくても OnTriggerStay で毎フレームチェックしているのだから、もう少し検査する範囲を絞りたい
そこで今回のように発見される判定を持ちたい GameObject 全てに対して検査すべき頂点座標を設定することによって検知できるようにした
// 敵の視界
public class EnemySight : MonoBehaviour
{
// 視線の原点を示す座標
[SerializeField] private Vector3 eyeCoordinate;
// 視界となるゲームオブジェクトに滞在している GameObject だけ検査する
public void OnTriggerStay(Collider other)
{
var something = other.gameObject;
if (!something.CompareTag("Player")) { return; }
foreach (var vertex in something.GetComponent<Body>().EdgeVertexes)
{
if (!Physics.Raycast(eyeCoordinate.transform.position, vertex, out RaycastHit hitinfo, Mathf.Infinity))
{
return;
}
if (hitinfo.collider.gameObject.CompareTag("Player"))
{
UnityEngine.Debug.Log("見ぃ〜つっけた!");
}
}
}
}
この方法のメリット・デメリットは以下の通り
メリット
- 自分で設定した頂点数しかチェックしないので敵の視界を全探索するよりマシ
- GameObject が複雑な形状をしていた場合や MeshCollider が単純な形状でなかった場合にも少ない頂点の探索で済む
デメリット
- 量産系のプロダクトの場合、設定数が馬鹿にならない(自動化できる方が好ましい)
- 敵の視界に内在する "Player" や "それに準ずる検知したい対象" が大量に含まれうるゲームの場合、この処理でも馬鹿にならない可能性がある
最後に
もっといい方法があればコメントください!
この記事で一人でも多くのエンジニアが手早くやりたいことを実現できますように🐳