AWS AuroraにLocustを使用した負荷テストを行い、性能検証を行いました。
その際の経緯と共に、詰まった点とポイントをまとめていきます。
ポイントまとめ
- Locustでリクエスト数を上げたい時は、Master/Worker構成にしSpawn rateは100以下にする
- Locustでユーザー数を増やしたい時は、「psycopg3」を使用する
- LocustでRPSを上げたい時は、「wait_time=0」に設定する
経緯
1, Master/Worker複数構成でLocustを起動
当初、AWSでLocustを起動しDBに接続しクエリを流すというテストで
・ECS on Fargate→Aurora
という構成の負荷テストを想定していました。
とりあえずの数値目標が「RPS:320」というのがあったので、
まずはLocustをMaster1台で「Number of users:320/Spawn rate:320」で1分間流してみました。
上記は、リクエストを投げるUser数の上限が320で、1秒毎に320ユーザーずつ増えていく
という意味で、理論上はテスト開始一秒後には320ユーザーからのリクエストが投げられる、という想定だったためです。
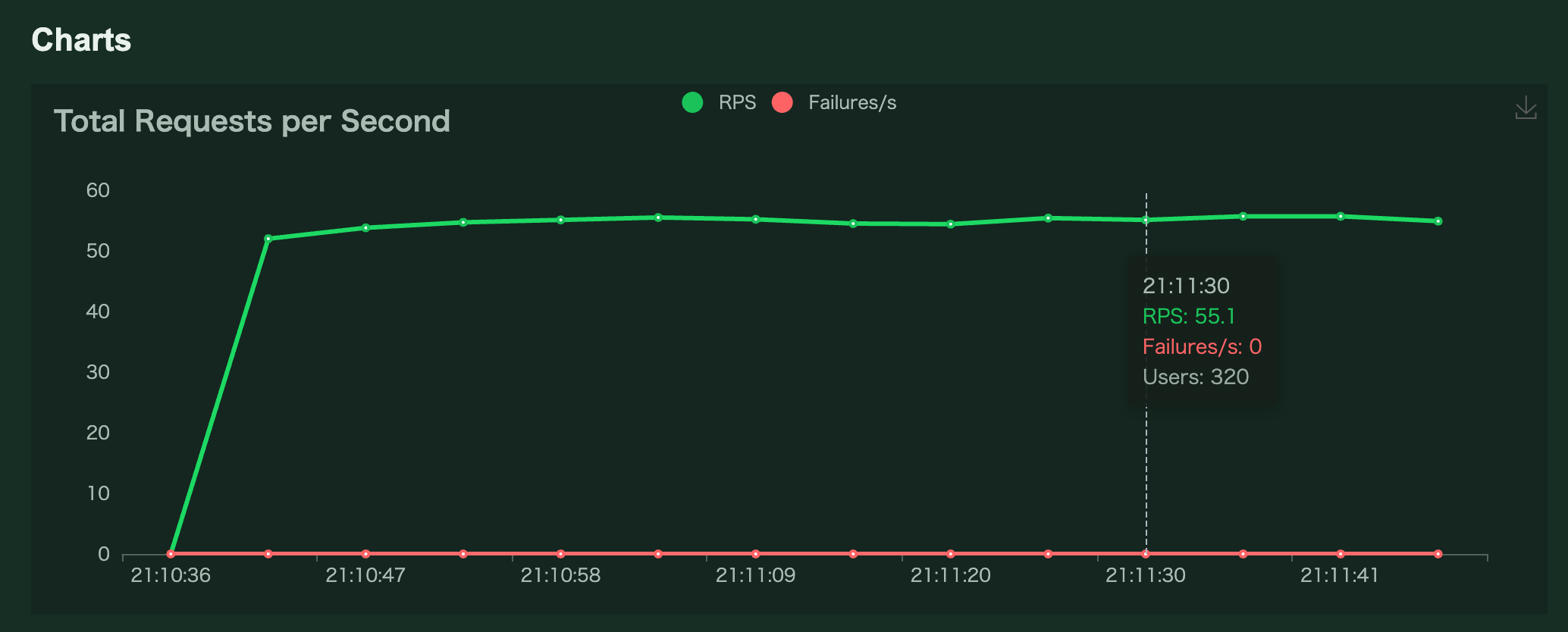
しかし、User数が320に達するもRPSは50が最大で推移
サーバーもDBもCPUは上限には全然達していない、という状況になりました。
この時、ひとつのコンテナイメージ内でLocustのMaster/Worker構成を取らずにMasterのみの構成としていたので、
サーバー側のスペックが低いのでは?ということで、Master/Worker構成を試しました。
・ECS on Fargateで、workerタスクを8台
ちなみに、1worker当たりが100を超える「Spawn rate」を設定すると下記のようなwarningが出ており、100以下が理想みたいなので「Number of users:320/Spawnrate:100」に変えました。
WARNING/locust.runners: Your selected spawn rate is very high (>100/worker), and this is known to sometimes cause issues. Do you really need to ramp up that fast?
参考:https://kawabatas.hatenablog.com/entry/2020/09/20/164314
2, DB接続数を増やすとMaster/Worker間が不安定になる
複数構成にしたはいいものの、User数を増やしていくとMasterとWorkerの接続が不安定
failed to send heartbeat, setting state to missing.
になり始め、最終的に全てのWorkerとの接続が維持できなくなるとテストが停止するという現象が起こりました。
Masterの性能を上げたり、Worker数を増やしてみても変わらず(RPSは300程度)
Locustの「wait_time」パラメータを1固定から5~30のランダム値に変更すると、User数は16,000程度まで上昇するが、RPSは800程度を上限にMaster/Workerの接続が不安定になってテストが止まります。
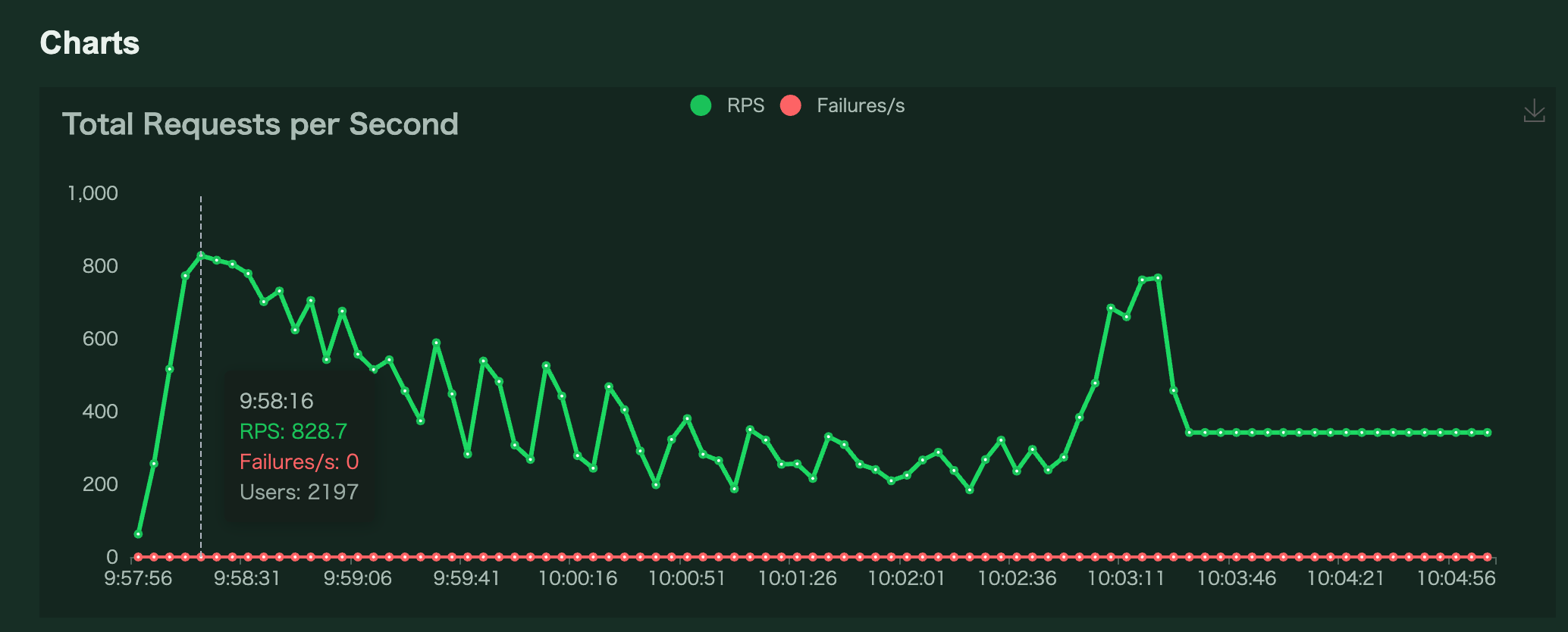
この時点で判明していること:
(設定:「Number of users:10,000/Spawn rate:100」)
1. 何も実行しないテストスクリプトだと10,000Users問題なく動作する。
→Locust単体は問題ない
2. DBへの接続のみ(クエリ実行なし)のテストにすると、今までと同様に3,000Usersを超えた当たり(30秒経過後)から、LocustのMasterからWorkerへのヘルスチェックが失敗し始める(RPSは850を最大に徐々に下がっていく)
最終的に全てのworkerが同時にヘルスチェックNGとなり、テストが自動停止する
→多数からのDB接続で何かが起こっている
3. DBの最大接続数(max_connections)をデフォルトの5000から10000に変更や、明示的な切断をしてみても状況は変わらない
DB側のCPU使用率は25%程度、DB接続数は70程度、利用可能メモリは72,000MB程度で全て余裕はありそうに見える
解決:
Locustの複数ユーザからの同時リクエスト制御は、純粋なマルチスレッドではなく、greenletを使用した疑似マルチスレッド(グリーンスレッド)で実現していました。
今回Locustから呼び出すスクリプトで使用していたPostgreSQLライブラリ「psycopg2」は、この疑似マルチスレッドでの動作に対応していない(正確には内部で使用している「libpg」が対応していない)ため、1ユーザーがDBに接続しているときに他ユーザーをブロックしてしまうようです。
最新バージョンの「psycopg3」では、「libpg」を使用せず、疑似マルチスレッドに対応しているため、Locustのスクリプトにて「psycopg3」に置き換えることで解決しました。
RUN pip install psycopg2
RUN pip install locust
↓
RUN pip install 'psycopg>=3<3.1'
RUN pip install locust
import psycopg2
・
・
・
def create_conn(db_host, db_port, db_name, db_user, db_pass):
conn = psycopg2.connect(host=db_host,
(省略)
↓
import psycopg
・
・
・
def create_conn(db_host, db_port, db_name, db_user, db_pass):
conn = psycopg.connect(host=db_host,
(省略)
参考: https://qiita.com/kazunee/items/607b03ca61bb5d5fdbe6#1-%E7%99%BB%E5%A0%B4%E4%BA%BA%E7%89%A9
https://github.com/psycopg/psycopg/issues/4
https://www.psycopg.org/docs/advanced.html#support-for-coroutine-libraries
https://www.psycopg.org/docs/advanced.html#green-support
再テスト実施結果:
設定「Master/Worker:32/User:10,000 /SpawnRate:100/CONSTANT_WAIT:1」
RPSは884.5ですが、Master/Workerの通信断はなくなりました!
ECSのCPU使用率が100%越え、DB接続数は9,100程度、1worker辺りのユーザ数は312程度
worker数を増やすとworkerのCPU使用率には影響はあるが、RPSは増えない
DB接続数はほぼ同じだったので、ここがボトルネックになってるかも。
あとは細かいパラメータを調整していきます。
3, Connection Pool機能を利用
先程のテストで、コネクションが枯渇してるせいで増えないのかと予想し、「psycopg3」のConnection Pool機能を利用してみました。
import psycopg
from psycopg_pool import ConnectionPool
(省略)
class PostgresqlClient:
def __init__(self) -> None:
self.writer_pool = ConnectionPool(
f'host={DB_HOST} port={DB_PORT} dbname={DB_NAME} user={DB_USER} password={DB_PASS}',
min_size=int(MIN_POOL_SIZE), max_size=int(MAX_POOL_SIZE), timeout=int(POOL_CON_TIMEOUT))
self.reader_pool = ConnectionPool(
f'host={DB_REPLICA_HOST} port={DB_PORT} dbname={DB_NAME} user={DB_USER} password={DB_PASS}',
min_size=int(MIN_POOL_SIZE), max_size=int(MAX_POOL_SIZE), timeout=int(POOL_CON_TIMEOUT))
(省略)
参考:https://www.psycopg.org/psycopg3/docs/api/pool.html
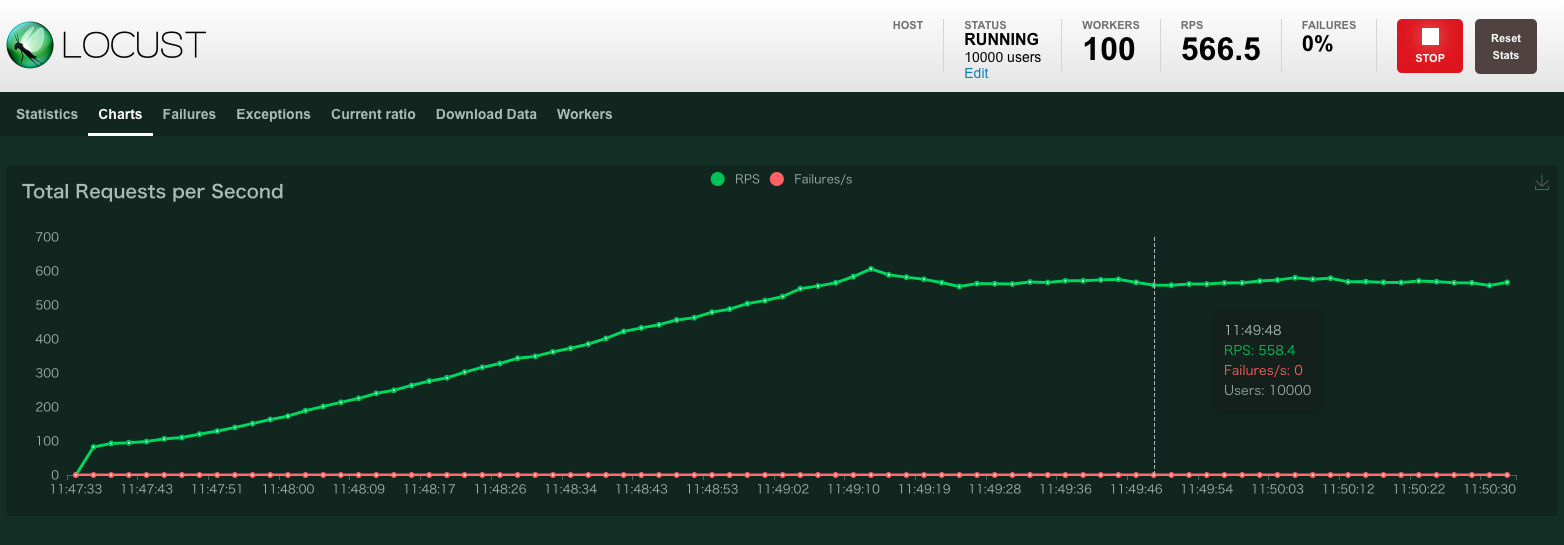
設定「min_size=1, max_size=4, timeout=30」→コネクションエラーが多発
設定「min_size=1, max_size=4, timeout=300」5分に変更→エラーがなくなりました。
※Worker数も上げました
しかしRPSは大きく上がる様子はありませんでした。
4, Locustの「wait_time」(タスク間の待ち時間)を0に
「wait_time」パラメータはLocustで各タスクの実行後、何秒後に次のタスクを実行するかの設定です。
「wait_time」が指定されていない(=0)場合、タスクが終了するとすぐに次のタスクが実行されるので、負荷を上げることができます。
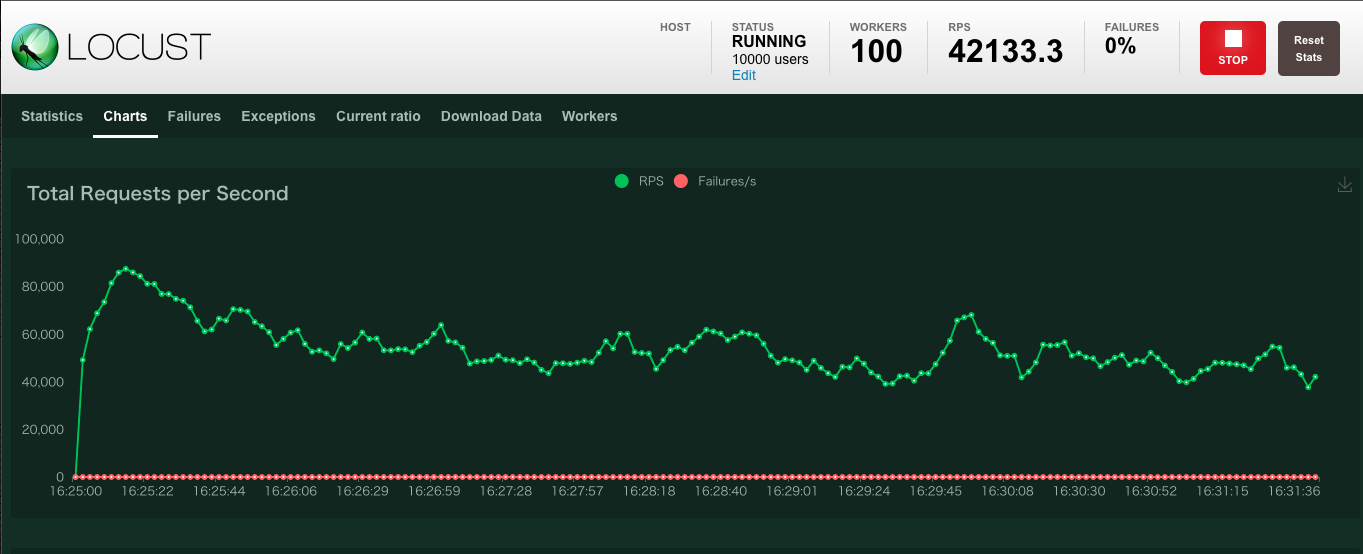
2,にて「wait_time」を5〜30秒ランダムにしていたのを0に変更すると、RPSが急激に上がりました。
どうやら原因は、タスクの処理をユーザーが待っていたようでした。
ちなみに「psycopg2」の問題で詰まっていた時に「wait_time」を5~30のランダム値に変更すると一時的にUser数が上昇していたのは、
単純に擬似マルチスレッドでの実行間隔に余裕ができた結果、ブロックされなくなっていたからだったようです。
(根本解決ではなかったですが)
おわりに
以上、もし同じような箇所で詰まった方がいましたら、参考になれば嬉しいです。