機械学習等のアプリケーションの設定を書く際に便利なツール colt を作りました.
簡単に紹介すると colt は AllenNLP のように設定を書くためのツールです.
タイトルには "機械学習" と書きましたが機械学習に限らず多くのアプリケーションの設定に利用できると思います.
はじめに
機械学習モデルを利用して実験する際, ハイパーパラメータを管理するためにargparse や Hydraなどが使われているのをよく目にします.
こうした既存のパラメータ管理ツールの多くで問題になるのはモデルを大きく変更した際にパラメータの読み込み処理も変更する必要があることだと思います.
例えば(すごく強引な例ですが), scikit-learn の SVC を使うつもりで argparse に C, kernel, class_weight 等のパラメータを読む設定を書いていたけど, RandomForestClassifier を使うことになって設定の読み込み部分まで書き直しが必要になった,とかでしょうか.
またStackingClassifier の様なアンサンブルモデルを設定したい場合,ベースとなる分類器やメタ分類器の設定まで行いたいとしたら,設定をどう書くべきか悩ましいところです.
AllenNLP
こうした問題を解決する手段の一つとして,自然言語処理のための深層学習フレームワークである AllenNLP が採用している Register機能 があります.
ここで少しこの Register機能 について説明します.ご存知の方は読み飛ばしてください.
AllenNLP ではJSON形式で設定を記述します.以下は文分類モデルの設定の一部です:
"model": {
"type": "basic_classifier",
"text_field_embedder": {
"token_embedders": {
"tokens": {
"type": "embedding",
"embedding_dim": 10,
"trainable": true
}
}
},
"seq2vec_encoder": {
"type": "cnn",
"num_filters": 8,
"embedding_dim": 10,
"output_dim": 16
}
},
type で使いたいクラスを指定し,それと同じレベルのフィールドにパラメータを設定します.
basic_classifier, cnn のコードも見てみましょう.設定項目と __init__ メソッドの引数が対応しています:
@Model.register("basic_classifier")
class BasicClassifier(Model):
def __init__(
self,
...,
text_field_embedder: TextFieldEmbedder,
seq2vec_encoder: Seq2VecEncoder,
...,
) -> None:
...
@Seq2VecEncoder.register("cnn")
class CnnEncoder(Seq2VecEncoder):
def __init__(self,
embedding_dim: int,
num_filters: int,
ngram_filter_sizes: Tuple[int, ...] = (2, 3, 4, 5),
conv_layer_activation: Activation = None,
output_dim: Optional[int] = None) -> None:
デコレータ register でクラスを登録すると設定からそれらのクラスを指定できるようになるという仕組みです.
AllenNLP ではクラスを作成しregister するだけでそのクラスの設定を記述できるようになります.
ここではこの機能を Register機能 と呼ぶことにします.
Register機能はクラスとその設定を関係づけるため,モデルの変更に応じで設定の読み込み処理を変更する必要がありません.
モデルの各種コンポーネントも設定から簡単に置き換えることができます.
seq2vec_encoder の type を cnn から lstm に変更する場合は以下のように設定を書き換えるだけです (lstm は予め AllenNLP に用意されています)
"seq2vec_encoder": {
"type": "lstm",
"num_layers": 1,
"input_size": 10,
"hidden_size": 16
}
colt の機能
colt は AllenNLP の Register機能 と同様の機能を実現するためのツールです.
colt を利用することで AllenNLP のように柔軟かつコードの変更に強い設定を簡単に行うことができます.
また,より多くのケースで利用しやすいように AllenNLP にはない機能もいくつか実装しています.
Register機能
以下に colt の使用例を示します:
import typing as tp
import colt
@colt.register("foo")
class Foo:
def __init__(self, message: str) -> None:
self.message = message
@colt.register("bar")
class Bar:
def __init__(self, foos: tp.List[Foo]) -> None: # ---- (*)
self.foos = foos
config = {
"@type": "bar", # `@type` でクラスを指定
"foos": [
{"message": "hello"}, # ここの型は(*)の型ヒントから推論される
{"message": "world"},
]
}
bar = colt.build(config) # config からオブジェクトを構築
assert isinstance(bar, Bar)
print(" ".join(foo.message for foo in bar.foos)) # => "hello world"
colt.register("<クラスの識別名>") によりクラスを登録します.
設定側では {"@type": "<クラスの識別名>", (引数)...} という形式で記述します.
設定からオブジェクトを構築する際は colt.build( <設定のdict> ) を呼びます.
もし設定に @type フィールドがなく対応する引数に型ヒントが書かれている場合には,型ヒントに基づいてオブジェクトが作成されます.
上記の例では Bar の引数 foos に 型ヒント List[Foo] が与えられているのでconfig 中の foos の中身は Foo クラスのオブジェクトに変換されます.
colt では型ヒントは必ず必要というわけではありません.
型ヒントを用いない場合は @type を省略せず書いてください.
config = {
"@type": "bar",
"foos": [
{"@type": "bar", "message": "hello"},
{"@type": "bar", "message": "world"},
]
}
@type も型ヒントもない場合は単に dict として扱われます.
インポート機能
scikit-learn などに含まれる既存のモデルにも colt を利用できます.
@type で指定した名前が register されていない場合は自動的にインポートされます.
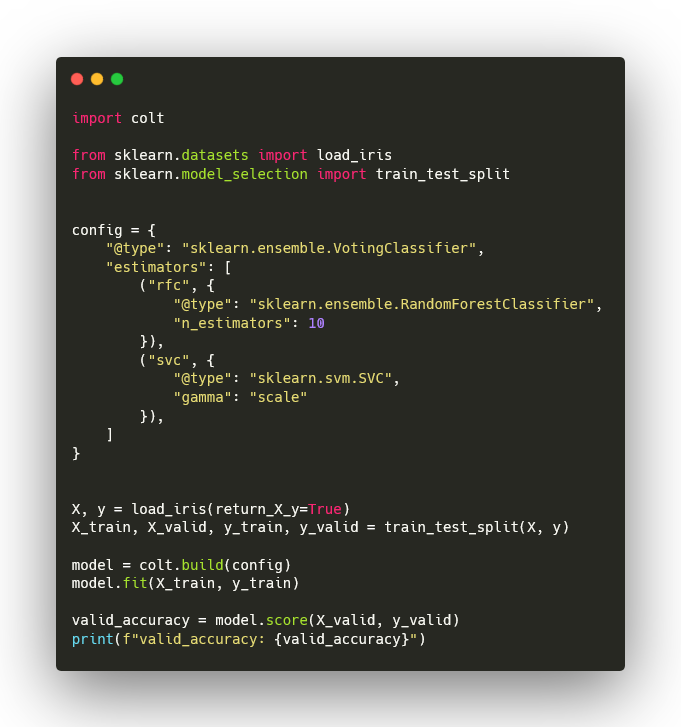
以下は scikit-learn の StackingClassifier を利用する例です:
import colt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
config = {
"@type": "sklearn.ensemble.StackingClassifier",
"estimators": [
("rfc", { "@type": "sklearn.ensemble.RandomForestClassifier",
"n_estimators": 10 }),
("svc", { "@type": "sklearn.svm.SVC",
"gamma": "scale" }),
],
"final_estimator": {
"@type": "sklearn.linear_model.LogisticRegression",
"C": 5.0,
},
"cv": 5,
}
X, y = load_iris(return_X_y=True)
X_train, X_valid, y_train, y_valid = train_test_split(X, y)
model = colt.build(config)
model.fit(X_train, y_train)
valid_accuracy = model.score(X_valid, y_valid)
print(f"valid_accuracy: {valid_accuracy}")
上記の例ではconfig に記述するモデルは scikit-learn のAPIを持つモデルであれば置き換え可能です.
例えば GridSearchCV で LGBMClassifier をグリッドサーチする場合は以下のようになります:
config = {
"@type": "sklearn.model_selection.GridSearchCV",
"estimator": {
"@type": "lightgbm.LGBMClassifier",
"boosting_type": "gbdt",
"objective": "multiclass",
},
"param_grid": {
"n_estimators": [10, 50, 100],
"num_leaves": [16, 32, 64],
"max_depth": [-1, 4, 16],
}
}
設定ファイルからの読み込みについて
colt ではファイルから設定を読み込む機能は提供していません.
ファイルから設定を読みたい場合はJSON/JsonnetやYAMLなどお好きなフォーマットから dict に変換して colt に渡してください.
その他の細かい機能
モジュールのインポート
複数の異なるファイルで register している場合,colt.build するタイミングで利用するすべてのクラスがインポートされている必要があります.
coltでは複数のモジュールを再帰的にインポートするために colt.import_modules が利用できます.
例えば以下の様なファイル構成を考えます:
.
|-- main.py
`- models
|-- __init__.py
|-- foo.py
`- bar.py
models/foo.py , models/bar.py でそれぞれ Foo クラス, Bar クラスが register されていて,main.py で colt.build が行われるとしましょう.
main.py で以下のように colt.import_modules(["<モジュール名>", ... ]) を利用します.
colt.import_modules(["models"])
colt.build(config)
colt.import_modules にモジュール名のリストを渡すと各モジュール以下を再帰的にインポートします.
上の例では ["models"] を引数に渡したため,models モジュールの下にあるすべてのモジュールがインポートされて Foo, Bar が利用可能になります.
位置引数
位置引数を設定に記述する場合はキーに * を指定し,値には位置引数のリスト(またはタプル)を渡してください.
@colt.register("foo")
class Foo:
def __init__(self, x, y):
...
config = {"@type": "foo", "*": ["x", "y"]}
コンストラクタの指定
coltはデフォルトではクラスの引数を __init__ に渡すことでオブジェクトを構築します.
__init__ 以外のメソッドからオブジェクトを作成したい場合には以下のように指定できます:
@colt.register("foo", constructor="build")
class FooWrapper:
@classmethod
def build(cls, *args, **kwargs) -> Foo:
...
他のクラスのwrapperとして利用する場合などに便利です.
メタキーの変更
coltが利用する @type,* などの特殊なキーは変更可能です.
例えば @type を @ に, * を + に変更する場合は colt.build に引数として指定します:
colt.build(config, typekey="@", argskey="+")
共通した設定を維持したい場合は ColtBuilder を使います.
builder = colt.ColtBuilder(typekey="@", argskey="+")
builder(config_one)
builder(config_two)
kaggle Titanic での利用例
colt を用いて kaggleのTitanicコンペ をやってみました.
pdpipe や scikit-learn を利用して特徴量の作成からモデルの学習,評価まで処理の多くが設定可能になっています.
設定はすべて configs 以下にJsonnetとして記述しました.colt を利用する際の参考になればと思います.
おわりに
colt の機能と利用例を紹介しました.
設定を書く際のお役に立てば幸いです.
またcolt の機能は AllenNLP という素晴らしいフレームワークをベースにしています.
AllenNLP には自然言語処理だけでなく多くの機械学習タスクに有用なアイデアが詰まっているので興味のある方はぜひ利用してみてください.