信州大学 kstm Advent Calendar 2017の6日目です.
mlxtendとは
mlxtendは,機械学習やデータ分析等のタスクにおいて便利なツールが用意されたPythonライブラリです.
学習曲線のプロットやStackingといったscikit-laernやmatplotlibに含まれない機能が揃っています.
また,mlxtendに用意されている学習器や事前処理はscikit-learnのAPIに準拠しているため,Pipelineをつくってグリッドサーチして...といった処理にも使うことができます.
以下ではmlxtendに入っているツールの一部を紹介します.
インストール
pipでインストールできます.
pip install mlxtend
また,Anacondaを使っている場合はcondaでもインストール可能です.
conda install -c conda-forge mlxtend
可視化
mlxtendに含まれているデータ可視化のためのツールを紹介します.
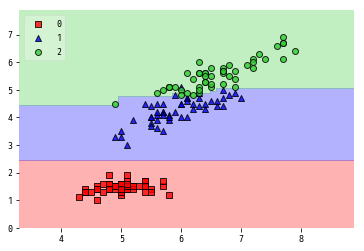
plot_decision_regions
plot_decision_regionsを使うと分類器の決定境界を描くことができます.
データとターゲット,分類器を渡すだけで描いてくれます.
from mlxtend.plotting import plot_decision_regions
from xgboost import XGBClassifier
iris = load_iris()
X, y = iris.data[:, [0, 2]], iris.target
clf = XGBClassifier().fit(X, y)
plot_decision_regions(X, y, clf=clf,res=0.02, legend=2)
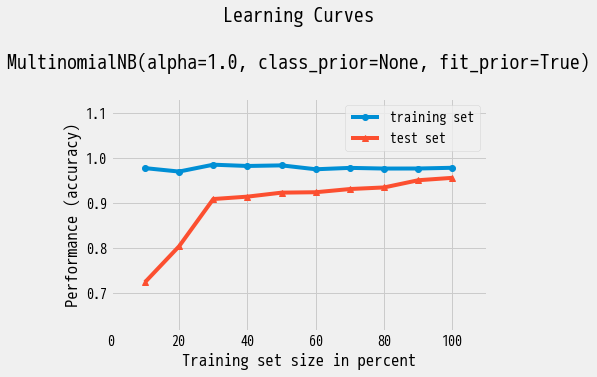
plot_learning_curves
学習曲線はモデルのバイアス,バリアンスの問題を診断する際に使われます.
plot_learning_curvesを使うと学習曲線を簡単に描くことができます.
学習データ,テストデータ,分類器を渡すだけで以下のような図がプロットされます.
縦軸のPerformanceはscoringを指定することで適合率,再現率,AUC,MSEなどいくつかの評価尺度を選ぶことができます.
from mlxtend.plotting import plot_learning_curves
from sklearn.datasets import fetch_20newsgroups
from sklearn.naive_bayes import MultinomialNB
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
categories = ['alt.atheism', 'soc.religion.christian',
'comp.graphics', 'sci.med']
twenty_news = fetch_20newsgroups(subset='all',
categories=categories, shuffle=True, random_state=42)
tfidf = TfidfVectorizer(min_df=5, max_df=0.5)
X, y = tfidf.fit_transform(twenty_news.data), twenty_news.target
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.7)
clf = MultinomialNB()
plot_learning_curves(X_train, y_train, X_test, y_test, clf, scoring='accuracy')
plt.show()
Stacking
Stackingはメタ学習器を使ったアンサンブル学習法の一つで,kaggle等のデータ分析コンペでは頻繁に使われる手法です.(Stackingについてはこちらやこちらがわかりやすいです)
mlxtendには分類,回帰のためのStackingモデルがそれぞれ含まれています.
StackingClassifier
分類のためのStackingモデルとしてStackingClassifierがあります.
classifiersに分類器のリスト,meta_classifierにメタ分類器を指定して使います.
ほかの引数についても簡単に説明しておきます.
-
use_probas
- Trueにすると,メタ特徴量として各分類器の予測確率を用います.
このとき,各分類器はpredict_probaメソッドが使えるように設定する必要があります
(e.g. SVCならprobability=Trueにする). - Falseならば,各分類器の予測クラスの値が渡されます.
- Trueにすると,メタ特徴量として各分類器の予測確率を用います.
-
average_probas(use_probas=Trueのときのみ)
- Trueにすると,各分類機からの予測確率を平均した値がメタ特徴量となります.
- Falseならば各分類器の予測確率のベクトルを結合したベクトルをメタ特徴量とします.
-
use_features_in_secondary
- Trueにすると,元(Level0)の特徴量をメタ分類器の学習でも使います.具体的には,メタ特徴量との結合ベクトルをメタ分類器に与えます.
- Falseならばメタ特徴量のみがメタ分類器に渡されます.
StackingClassifierに渡した分類器のパラメータはGridSearch等のハイパーパラメータの最適化にも対応します.
詳しくはこちらを見てください.
以下では3-FoldCVスコアの平均を単一モデルとStackingモデルで計算しています.
StackingClassifier(classifiers, meta_classifier, use_probas=False, average_probas=False, verbose=0, use_features_in_secondary=False)
from sklearn import model_selection
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import MultinomialNB
from lightgbm import LGBMClassifier
from mlxtend.classifier import StackingClassifier
from sklearn.datasets import fetch_20newsgroups
import numpy as np
categories = ['alt.atheism', 'soc.religion.christian',
'comp.graphics', 'sci.med']
twenty_news = fetch_20newsgroups(subset='train',
categories=categories, shuffle=True, random_state=42)
tfidf = TfidfVectorizer(min_df=5, max_df=0.5)
X, y = tfidf.fit_transform(twenty_news.data), twenty_news.target
clfs = [LGBMClassifier(random_state=1),
LogisticRegression(),
MultinomialNB(alpha=0.5),]
lr = LogisticRegression()
sclf = StackingClassifier(classifiers=clfs,
use_probas=True,
average_probas=False,
meta_classifier=lr)
print('3-fold cross validation:\n')
for clf, label in zip(clfs + [sclf],
['LightGBM',
'Logistic Regression',
'Naive Bayes',
'StackingClassifier']):
scores = model_selection.cross_val_score(clf, X, y,
cv=3, scoring='accuracy')
print("Accuracy: %0.2f (+/- %0.2f) [%s]"
% (scores.mean(), scores.std(), label))
3-fold cross validation:
Accuracy: 0.90 (+/- 0.00) [LightGBM]
Accuracy: 0.96 (+/- 0.00) [Logistic Regression]
Accuracy: 0.96 (+/- 0.00) [Naive Bayes]
Accuracy: 0.97 (+/- 0.00) [StackingClassifier]
StackingRegressor
StackingRegressorは回帰のためのStackingモデルです.
使い方はStackingClassifierと同じようにLevel1のモデルのリストとメタ回帰モデルを指定します.
StackingRegressor(regressors, meta_regressor, verbose=0)
その他ツール
DenseTransformer
疎行列型の配列を密行列型に変換します.
通常,疎行列型はtodense()メソッドで密行列に変換できますが,Pipelineで処理を扱う際は直接todense()を行うことができません.
DenseTransformerはfit_transform()で疎行列から密行列への変換を行うため,Pipelineに追加しておくとその前後で変換してくれます.
なので疎行列を返す処理(TfidfVectorizerとか)の後に疎行列非対応の処理がある場合,その間にDenseTransformeを置くとうまく動作します.(最近はscikit-learnの多くのモデルが疎行列対応しているため今後出番は少なくなるかも)
shuffle_arrays_unison
shuffle_arrays_unisonは2つの配列の要素(axis=0)を,インデックスの対応を保ったまま同時にシャッフルできます.
ミニバッチ学習などでデータとターゲットを同時にシャッフルしたいときに便利です.
find_filegroups
find_filegroupsを使うと,異なるディレクトリに存在している関連する(拡張子を除いた名前が同じ)ファイルをまとめることができます.
まとめ
上記ではmlxtendに含まれるツールの一部を紹介しました.mlxtendの良いところは,「地味に便利」なことかと思います.
細かな処理をこうしたライブラリに任せることでよりタスクが捗るのではないでしょうか.
ここで紹介したことは公式ドキュメントにも詳しく解説があります.
また,ほかにも便利な機能が色々と揃っているので探してみてください.