熱く、暑かった日本ダービーも終わり、2歳新馬戦が始まり、夏競馬へと突入していきます。さて、私は競馬を始めてあまり長くありませんが、以前このようなことを聞きました。
「夏競馬は荒れる」
そういえば去年の夏競馬、ふと平場の払い戻し見たら6桁であったことが多かった気がする。というわけで今年も夏競馬が始まるその前に、本当に夏競馬は荒れるのかを検証してみました。
解析の準備
まずデータは、一般的にはスクレイピングで取ってくるパターンが多いですが、私はJRA-VAN会員なので、「TARGET frontier JV」という有料ソフトを使ってcsv出力を行いました。ありがたや~
ちなみに1か月無料体験があるので気になる方はお試しあれ↓
出力したデータは2010年から2021年で、以下の項目となります。
| 項目 | 補足 |
|---|---|
| 年 | 10~21年 |
| 月 | |
| 日 | |
| 開催場 | |
| レース番号 | |
| レース種別 | レースの略称(OP,G1など) |
| レース名 | 未勝利や新馬戦の場合、レース種別のみでレース名は省略される |
| コース | 該当なしの場合、0 |
| コース種類 | 芝 or ダート |
| 距離 | |
| 天気 | |
| 馬場 | |
| 馬番 | |
| 馬名 | |
| 馬体重 | kg |
| 性別 | 牡 or 牝 or セ |
| 年齢 | |
| 騎手 | |
| 斤量 | ハンデ |
| 着順 | 競争除外、競争中止の馬は0 |
| 人気 | 競争除外の馬は0 |
| オッズ | 競争除外の馬は0 |
| 父 | |
| 母 | |
| 母父 |
TARGET frontier JVはもっと多くの項目を出力できますが、非常に時間が掛かる上、競馬AIを作るわけでもないので今回はこれだけにしておきました。
それではデータを見ていきましょう。Jupyter Notebookを使って、まずは普通にデータを読み込んでみます。
import pandas as pd
df = pd.read_csv("csv/horse.csv",encoding='CP932')
データが横に長いため省略しています。8月から始まっていますがCSV出力時のミスで、ちゃんと12か月分入っています。
とはいえ今後困るのでソートしておきましょう。
df.sort_values(["年","月","日"])
試しに競走馬の情報を出してみましょう。ドゥラメンテという馬です。
Duramente = df[df["馬名"] == "ドゥラメンテ"]
Duramente.loc[:,["馬名","レース種別","着順"]]

つよい。
ということでここからは夏競馬が荒れるのかを調べていきます。
夏競馬が荒れると言われる理由
まず夏競馬が荒れると考えられる要因は以下の通り
-
有力馬は秋のG1に向けて休養期間に入る
-
ハンデ戦の重賞が多い
-
2歳新馬戦が始まる
-
暑い
まず、夏はG1レースがないので、春の激闘を終えたクラシック馬や古馬の多くは、秋のG1に向けて休養期間に入り、G1クラスの馬がほとんど出走せず、実力差がそれほど出なくなります。また、仮に強い馬が夏の重賞に出てもハンデ戦が多いため、厳しい斤量を課され、人気薄に負けてしまうということが起きます。
それから、夏からは新たにデビューした馬が走る2歳新馬戦が始まります。新馬達は今までの戦績が無いので、血統や調教データ、騎手、厩舎からのコメント等で予想することになりますが、そう簡単に予想できるものではありません。まず、血統が良ければ走るとは限らず、高額な馬であれば走るということもありません。調教が良くても、競馬場の喧騒に慣れていない馬は調子を崩すこともありますし、掛かるし、発送直前でゲート難起こしたり、圧倒的な1番人気が沈むということも珍しくはありません。まあそれでも勝つ馬がいるんだけど
他にも夏のローカル競馬場(主に函館,福島)は直線距離が短いために人気薄が逃げ切ってしまうとか、色々な要因が考えられます。
解析
とりあえず10年から21年の月別1番人気の勝率から見てみましょう。データから一番人気の馬データを取り出し、その中から一着の馬のデータを取り出して勝率を算出します。
favorite = df[df["人気"] == 1]
winner = favorite[favorite["着順"] == 1]
winner_monthly = winner["月"].value_counts().reset_index()
favorite_monthly = favorite["月"].value_counts().reset_index()
winner_monthly = winner_monthly.rename(columns = {"index":"月","月":"1番人気勝利数"})
favorite_monthly = favorite_monthly.rename(columns = {"index":"月","月":"レース数"})
favorite_winner = pd.merge(winner_monthly,favorite_monthly,on="月")
favorite_winner = favorite_winner.sort_values("月")
win_per = favorite_winner["1番人気勝利数"]/favorite_winner["レース数"]
win_per = win_per.rename("勝率")
favorite_winner = pd.concat([favorite_winner,win_per],axis=1)
pd.set_option('display.unicode.east_asian_width', True) #日本語表示を崩さない記述
print(favorite_winner)
出力すると以下のようになります。
| 月 | 1番人気勝利数 | レース数 | 勝率 |
|---|---|---|---|
| 1 | 1181 | 3719 | 0.317558 |
| 2 | 1112 | 3548 | 0.313416 |
| 3 | 1231 | 3852 | 0.319574 |
| 4 | 1100 | 3504 | 0.313927 |
| 5 | 1112 | 3597 | 0.309147 |
| 6 | 1072 | 3264 | 0.328431 |
| 7 | 1211 | 3756 | 0.322417 |
| 8 | 1221 | 3732 | 0.327170 |
| 9 | 1017 | 3048 | 0.333661 |
| 10 | 1244 | 3672 | 0.338780 |
| 11 | 1105 | 3410 | 0.324047 |
| 12 | 1084 | 3305 | 0.327988 |
うーん、夏は勝率が下がると思っていたんですけどそうでもなさそうですね...
グラフに出力してみましょう
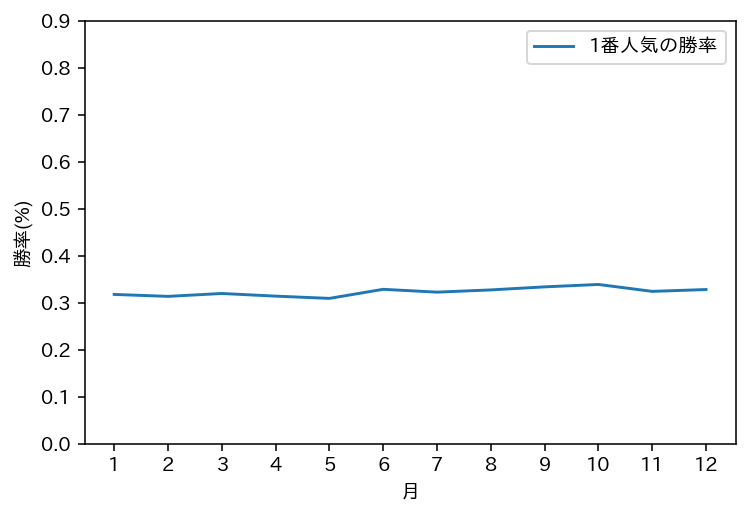
勝率が下がるどころかちょっと上がってるではありませんか。では年ごとに見るとどうでしょうか












2010年、2017年、2020年は夏の一番人気の勝率が低いように見えますが、それ以外は、特段勝率が低いということはありませんでした。一番人気は一番人気ってことでしょうね。では紐がどれくらい荒れてるかを調べましょう。以下のグラフは5人気以下がどれくらい2着、3着に入ったかを示すものです。
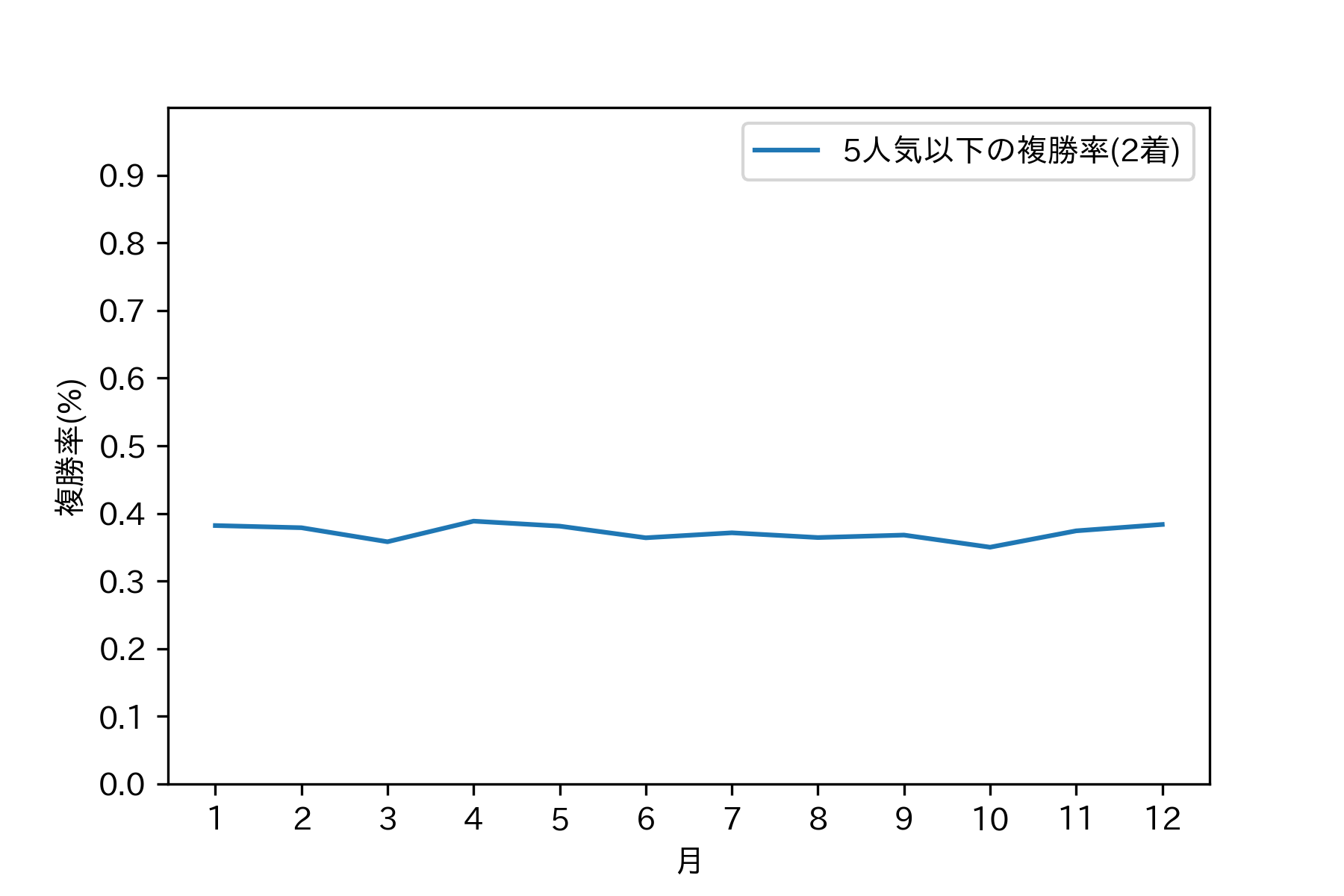
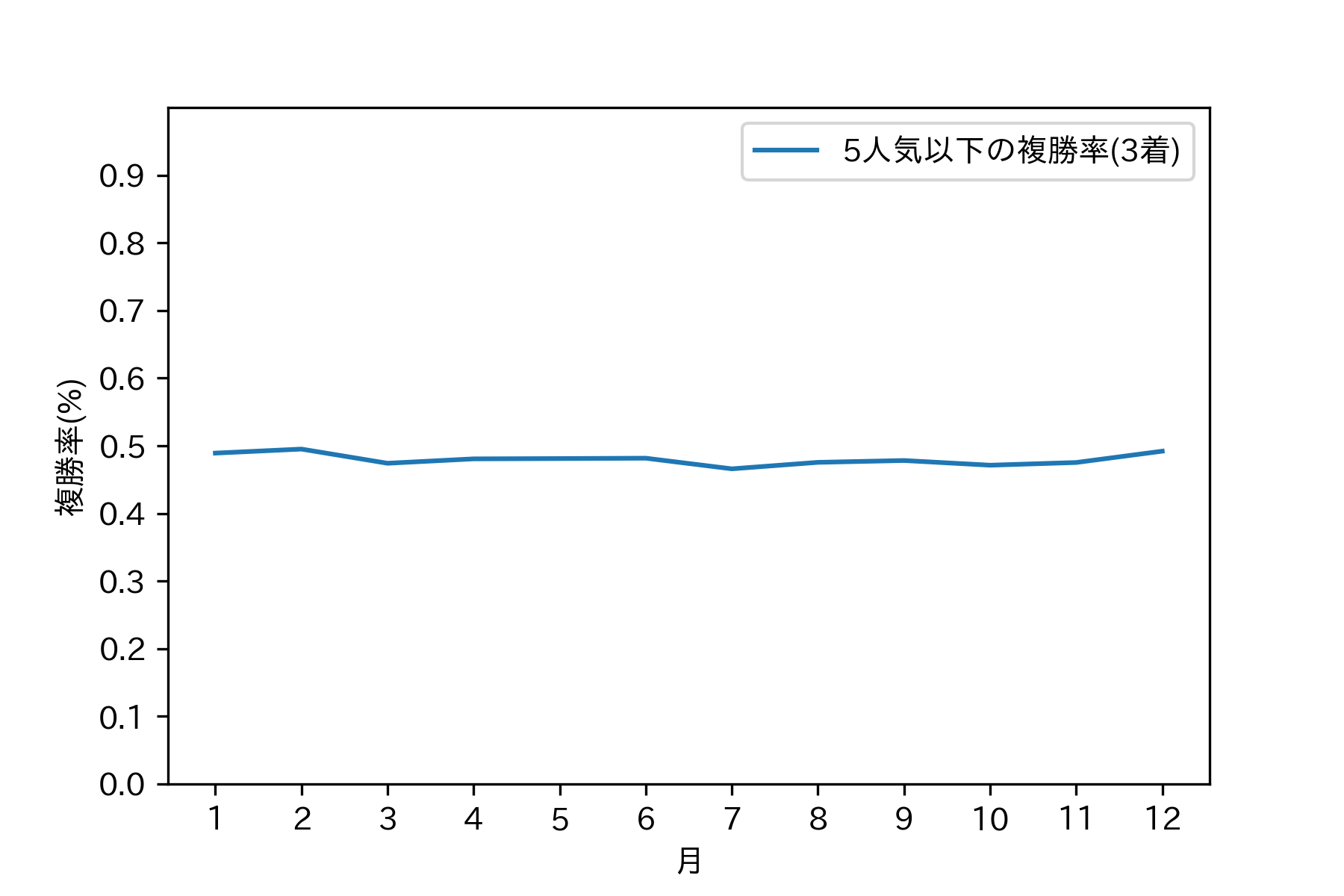
人気薄の2着馬、3着馬のも一番人気の1着馬と同じく、夏に特段の変化は見られません。3着の方は若干下がっていますが、春も同じように下がっています。これもおそらく年ごとに分けると変化がある年とない年に分かれるでしょう。
結果
思ったよりも夏競馬は荒れていなかったということが判明しました。年によっては秋のほうが荒れてる時もあるし、春が荒れてる時だってある。まあ競馬に絶対はありませんからね、夏に限らず。
しかし...
6/12(日)の中央競馬

やっぱり荒れてんじゃん!!しかもこの日は単勝万馬券が二回も飛び出すというとんでもない日でした。
というわけで今回は人気と着順のみを見ましたが、次回は更に条件を細かくして、払い戻しや馬場状態、開催場などから調べていきたいと思います。