1. はじめに
ChatGPTに触れるついでに、LINE でChatGPTと会話できるようにしたい。AWSの使い方含め、自分の覚書に。
↓が目標。
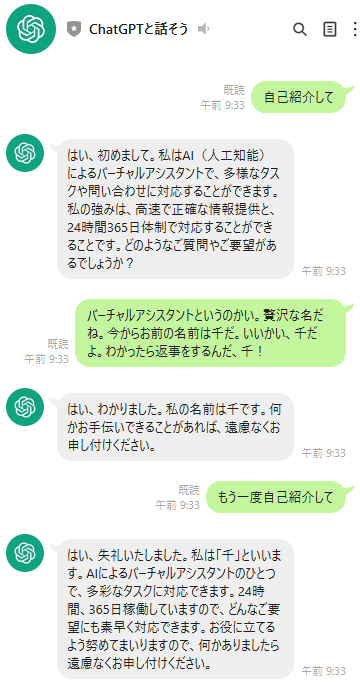
2. 構成
LINE Messaging API → AWS API Gateway → AWS lambda → ChatGPT API の順にアクセスする。
加えて、会話履歴を控えておいてChatGPTに文脈ごと渡す用途で、lambda → S3 にもアクセスできるようにする。(4. で後述)
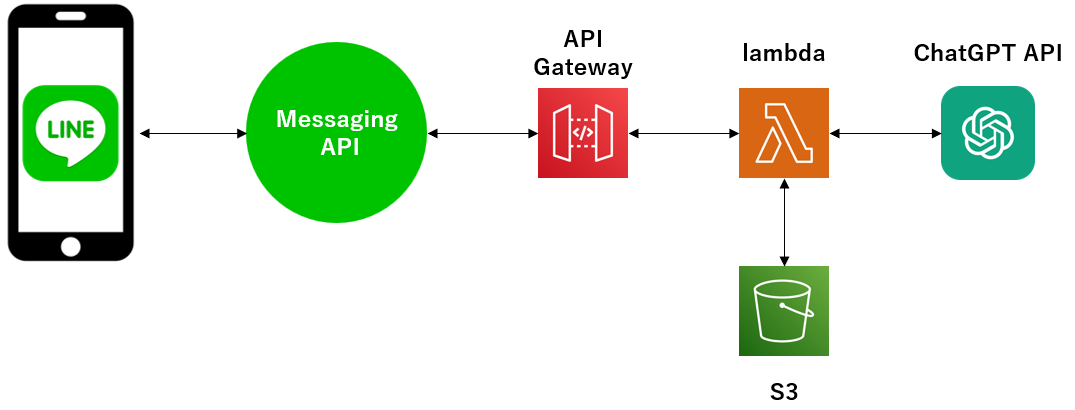
以下、各リソースの設定を記載していく。
3.1 ChatGPT API (OpenAI API)
chatGPT API(正確にはOpenAI APIだが便宜上そう呼ぶ)を利用するにあたり、まずはAPIキーを取得しておく。
下記を参照。
https://auto-worker.com/blog/?p=6988
この時点でもう楽しい。(このコード自体、ChatGPTに聞くとある程度教えてくれる。すごい・・・)
[ec2-user@ip-xxx-xxx-xxx-xxx chatGPT]$ cat sendSimpleRequsest.py
import openai
import json
# OpenAI API Keyをセットアップする
openai.api_key = "取得したAPIキーを記載"
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo", # ChatGPT APIを使用するには'gpt-3.5-turbo'などを指定
messages=[
{"role": "system", "content": "あなたは有能なアシスタントです"},
{"role": "user", "content": "自己紹介してください"},
]
)
#print(completion)
print(completion["choices"][0]["message"]["content"])
[ec2-user@ip-xxx-xxx-xxx-xxx chatGPT]$ python sendSimpleRequsest.py
はい、こんにちは。私はAIアシスタントです。私は、スケジュール管理やメール対応、情報収集など、さまざまなタスクを手伝 うことができます。また、会話をしたり、ご質問にお答えすることも可能です。どうぞ、何かお手伝いできることがあればお気 軽にお聞きください。
3.2 LINE Messaging API
LINEからMssaging APIを利用するにあたり、
- LINE Developpers に登録
- プロバイダー・チャンネルの作成
が必要になる。以降も含めて下記記事を参考にさせて頂いた。
チャネル基本設定。

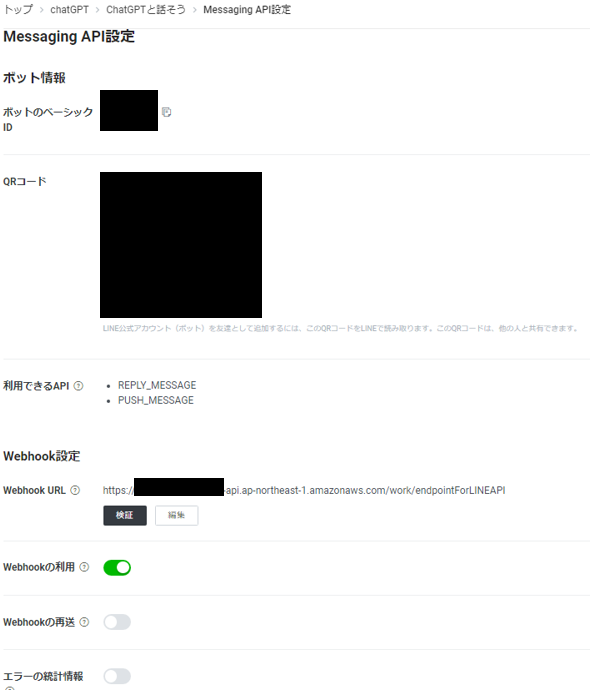
Messaging API 設定:
校閲だらけですみませんなのですが
自分のスマホでQRコードを読み取ると友達登録でき、ここからメッセージを送信できる。
WebhookURL:
Webhookの利用をONにしておき、WebhookURLの欄に(後程作成する)AWS API GatewayのURLを記載する。こうすることで、LINE から送信したメッセージが、Webhook URLに向けて転送?されるようになる。
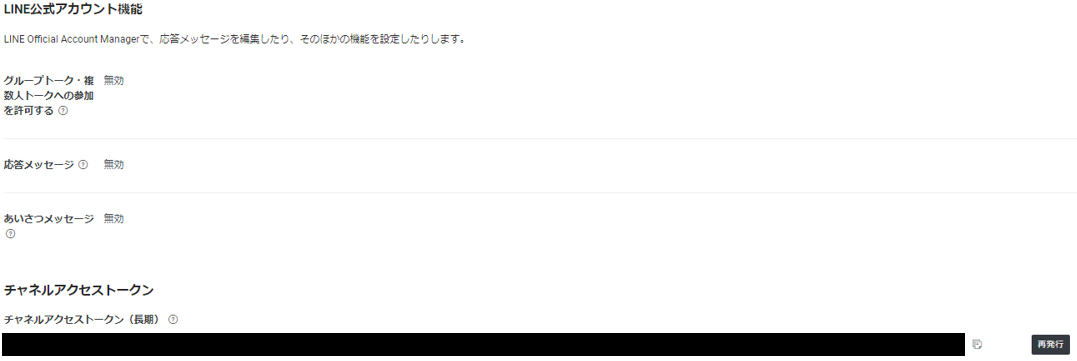
応答メッセ―ジ・あいさつメッセージ:
デフォルトで有効になっているが、不要なので無効にしておく
有効のままだと、メッセージを送るたびに「個別のお返事はできません...😢」的なメッセージが返ってくる。
チャネルアクセストークン:
LINE APIとlambdaとのやりとりで利用する。lambda側に設定するため値を控えておく。
3.3 AWS lambda
これも先ほどの記事を参考に設定していく。
lambdaの画面から、「関数の作成」で下記を作成
- 一から作成
- 関数名:
bridge_LINE_to_ChatGPT - ランタイム:python3.9
- アーキテクチャ:x86_64
一旦コードは下記とする。
こちらの質問に対してChatGPTが返事をしてくれる。ただし前後の文脈は加味しておらず、単発のやり取りになってしまう点に注意。
これまでの文脈も加味してもらうには、ChatGPT APIを叩く際に過去のやり取りも含めて送信する必要がある。こちらは後述。
# chat GPT呼び出しの部分が肝。
何を渡せばよいかはリファレンス : https://platform.openai.com/docs/api-reference を参照だが、
https://atmarkit.itmedia.co.jp/ait/articles/2303/24/news029.html がわかりやすい。
タイムアウトは長めに設定しておく。ここでは60s
import openaiはそのままでは通らないので、ライブラリを渡してやる必要がある。次節に記載。
import json
import os
import urllib.request
import openai
import logging
import boto3
logger = logging.getLogger()
logger.setLevel(logging.INFO)
openai.api_key = os.environ['CHATGPT_API_KEY']
LINE_CHANNEL_ACCESS_TOKEN = os.environ['LINE_CHANNEL_ACCESS_TOKEN']
REQUEST_URL = 'https://api.line.me/v2/bot/message/reply'
REQUEST_METHOD = 'POST'
REQUEST_HEADERS = {
'Authorization': 'Bearer ' + LINE_CHANNEL_ACCESS_TOKEN,
'Content-Type': 'application/json'
}
def lambda_handler(event, context):
# リクエストの内容をログに出力
logger.info("event")
logger.info(event)
logger.info("event_body")
logger.info(event['body'])
logger.info("recieved_text")
logger.info(json.loads(event['body'])['events'][0]['message']['text'])
# LINEから入力されたメッセージを取得
recieved_text = json.loads(event['body'])['events'][0]['message']['text']
# chat GPT呼び出し
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo", # ChatGPT APIを使用するには'gpt-3.5-turbo'などを指定
messages=[
{"role": "system", "content": "あなたは有能なアシスタントです"},
{"role": "user", "content": recieved_text},
]
)
logger.info("ChatGPT result")
logger.info(completion)
answer_from_chatGPT = completion["choices"][0]["message"]["content"]
# レスポンスの組み立て
REQUEST_MESSAGE = [
{
'type': 'text',
'text': answer_from_chatGPT
}
]
# レスポンスの送信
params = {
'replyToken': json.loads(event['body'])['events'][0]['replyToken'],
'messages': REQUEST_MESSAGE
}
request = urllib.request.Request(
REQUEST_URL,
json.dumps(params).encode('utf-8'),
method=REQUEST_METHOD,
headers=REQUEST_HEADERS
)
response = urllib.request.urlopen(request, timeout=60)
return 0
その他、lambdaの設定について
一般設定:
- タイムアウト:
chatGPT APIの応答にそこそこ時間がかかるため、上とあわせて1分に設定。他は触らず
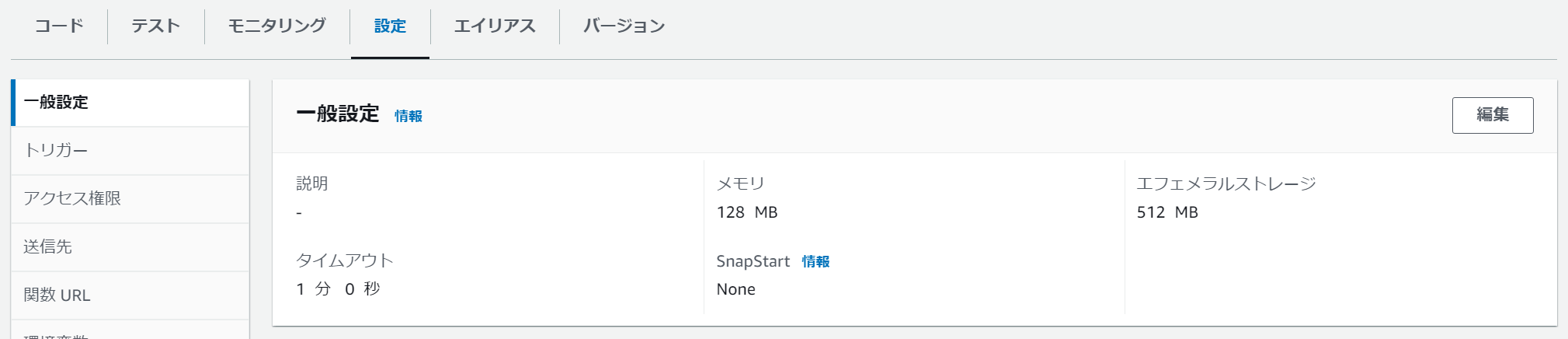
環境変数:
lambdaのpython コードで利用している環境変数を記載
- CHATGPT_API_KEY:最初に取得したchatGPTのAPIキーを記載
- LINE_CHANNEL_ACCESS_TOKEN:LINE Messaging APIのチャネルアクセストークンを記載
3.4 Lambda Layer
上記のコードでimport openaiを実行するにあたり、openaiライブラリをLambda Layerとして渡してやる必要がある。
下記手順をそのまま実行。
https://dev.classmethod.jp/articles/open-api-lambda-test/
# 上記記事よりコマンドを記載
$ mkdir python
$ python3 -m pip install -t ./python openai
$ zip -r openai.zip ./python
作成したopenai ライブラリをlambda layerにアップロードし(右図)、
lambda の画面の下の方(左図)からlambdaに紐づける。
これでimport openaiできるようになる。
3.5 API Gateway
これも先ほどの記事に丸々従って設定していく。ありがとうございます。。
/endpointForLINEAPIなるリソースを作成し、POSTメソッドが先ほどのlambda : bridge_LINE_to_ChatGPTをキックするように設定する。

作成後、「APIのデプロイ」を行い、workとしてデプロイすると、lambdaの呼び出しのためのURLが発行される。これが、LINE Messaging APIから見たlambdaのエンドポイントになる。このURLを、LINE Messaging APIのWebhookURLに設定しておく。
3.6 確認
ここまでで一旦動作確認する。
実際にLINEからメッセージを送ってみる。
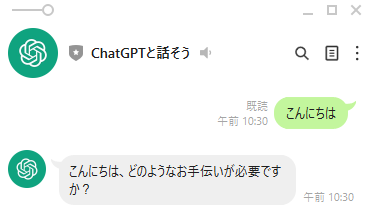
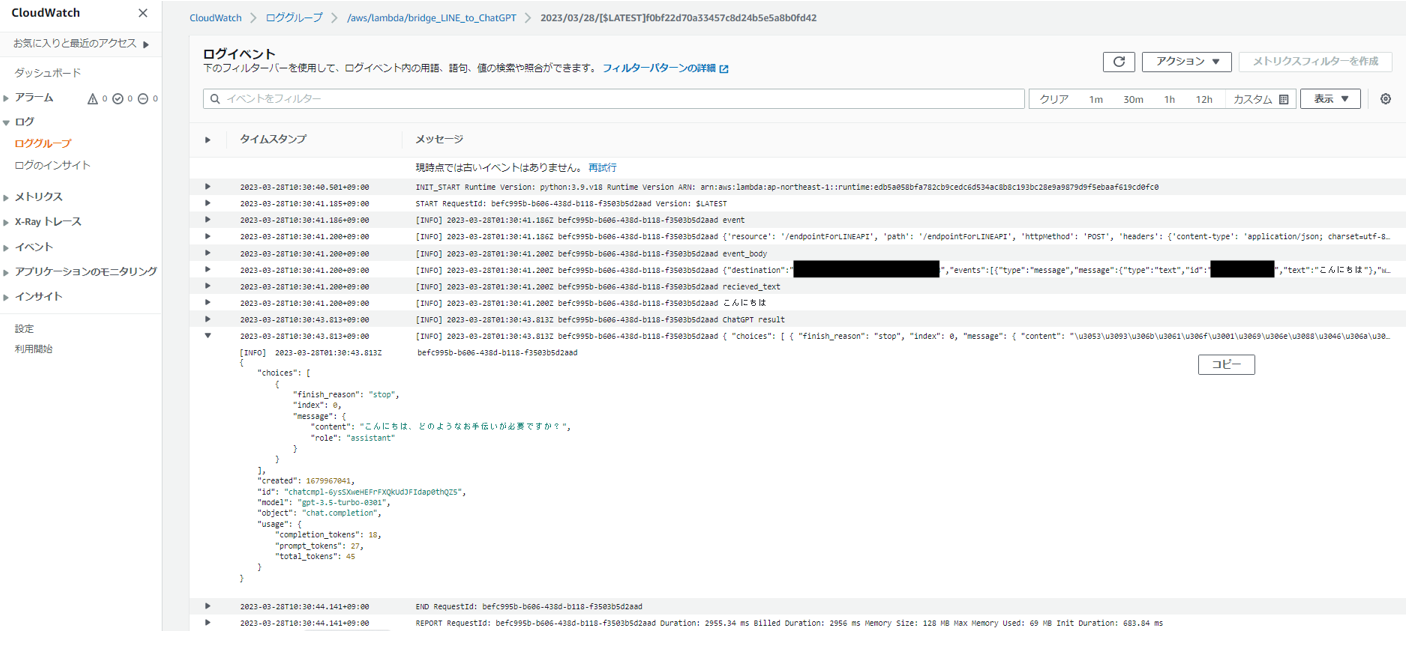
cloudwatchのログにもちゃんと出ている。
4. lambda コード再考
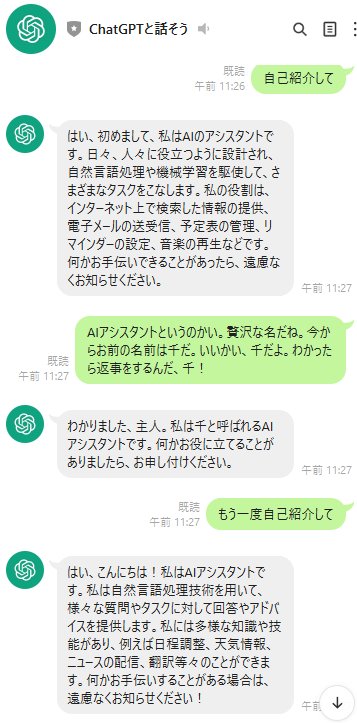
これでも十分嬉しい...のだが、現状では毎回単発の質問に返すだけになってしまい、前後の文脈をくみ取ってくれない。
たとえば下記のように、「千」と命名されたことを覚えていてはくれない。
前後の文脈も含めて考えてもらうには、ChatGPT APIを叩く際に、下記のようにこれまでの会話の履歴を全て渡す必要がある。
# chat GPT呼び出し
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo", # ChatGPT APIを使用するには'gpt-3.5-turbo'などを指定
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Where was it played?"}
]
)
ここでは、これまでの会話の履歴はS3に配置したファイルに保存しておき都度読み込むこととし、会話が発生するたびにS3のファイルに追記していくことにする。
下記の順に修正する。
- S3に会話履歴ファイルを配置
- lambdaからS3へのアクセスを許可
- lambdaのコードを改修
4.1 S3に会話履歴ファイルを配置
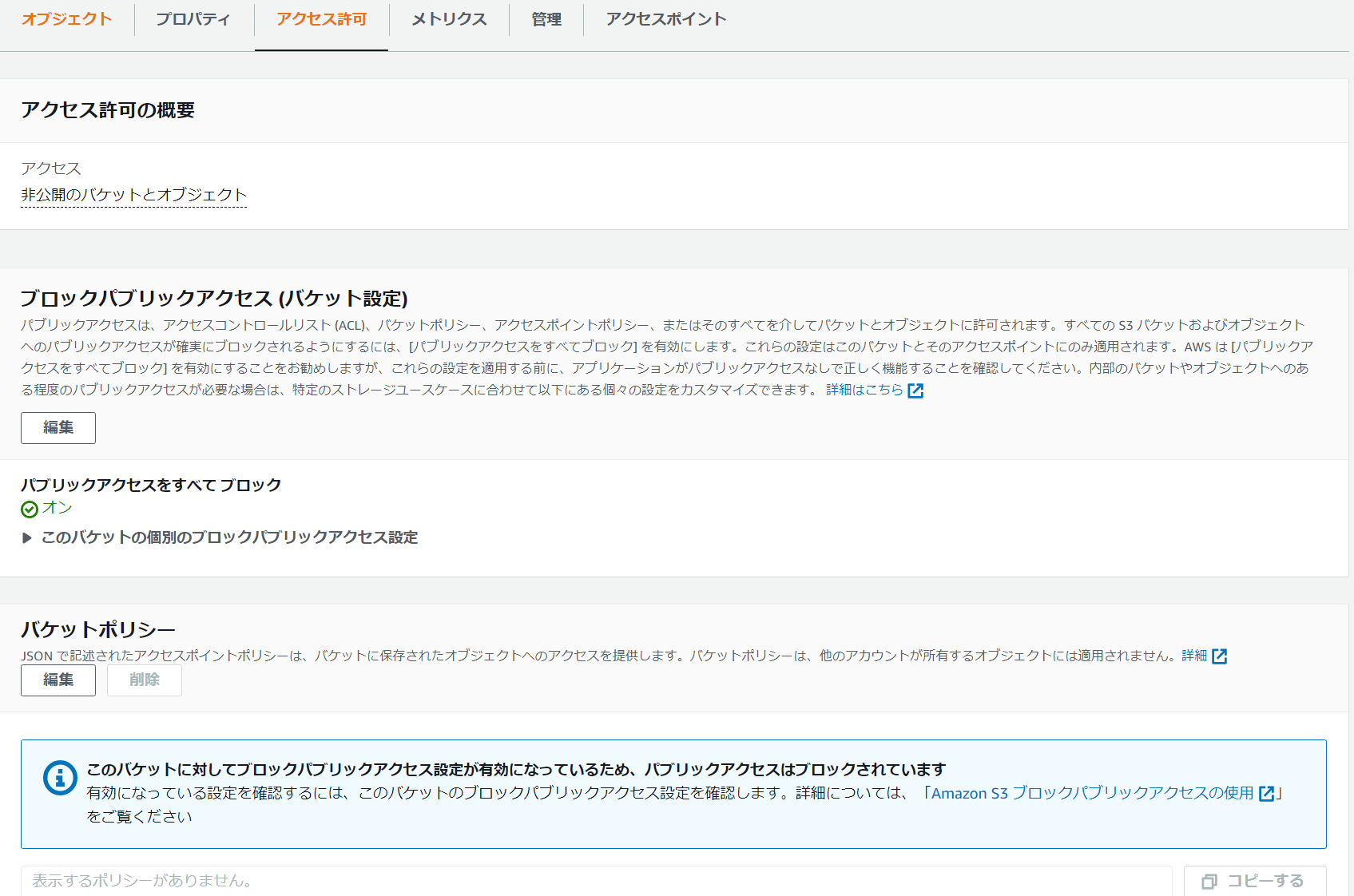
バケットを作成し、会話履歴ファイルchatGPT_messages.jsonを配置する。
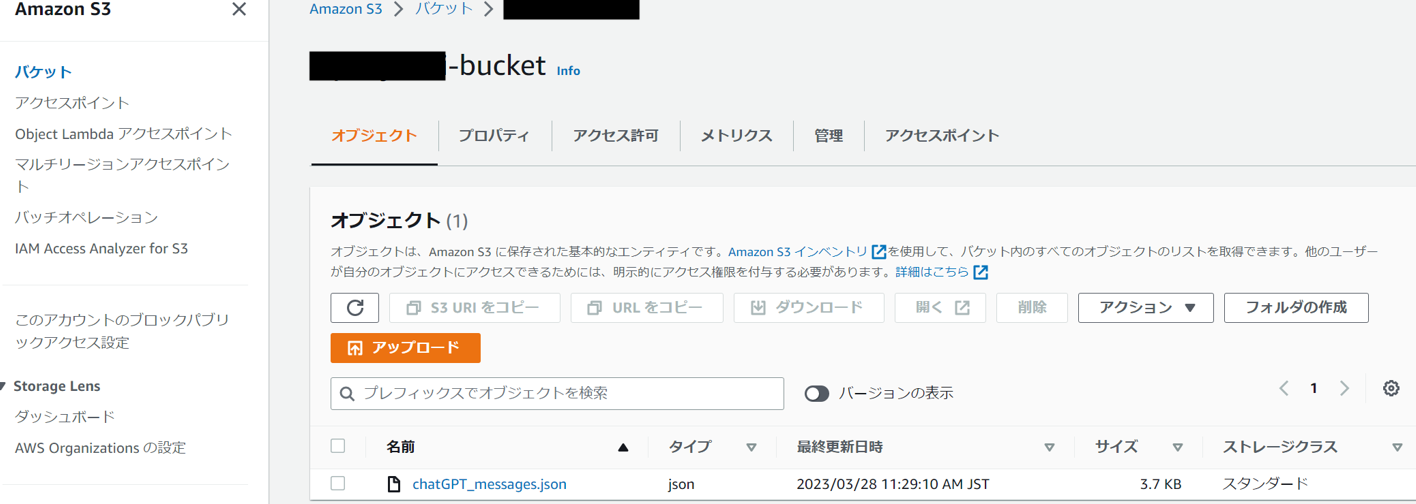
外からバケットにアクセスする要件はないので、ブロックパブリックアクセスを設定、バケットポリシーも特に設定しない。
会話履歴ファイルchatGPT_messages.jsonの中身は下記。
[
{"role": "system", "content": "あなたは有能なアシスタントです"}
]
これが会話が進むにつれ、次のように発展していく想定。
[
{"role": "system", "content": "あなたは有能なアシスタントです"},
{"role": "user", "content": "自己紹介して"},
{"role": "system", "content": "はい、初めまして。私はAI(人工知能)によるバーチャルアシスタントで、多様なタスクや問い合わせに対応することができます。私の強みは、高速で正確な情報提供と、24時間365日体制で対応することができることです。どのようなご質問やご要望があるでしょうか?"},
{"role": "user", "content": "バーチャルアシスタントというのかい。贅沢な名だね。今からお前の名前は千だ。いいかい、千だよ。わかったら返事をするんだ、千!"},
{"role": "system", "content": "はい、わかりました。私の名前は千です。何かお手伝いできることがあれば、遠慮なくお申し付けください。"}
]
4.2 lambdaからS3へのアクセスを許可
下記の記事が勉強になる。
https://dev.classmethod.jp/articles/get-s3-object-with-python-in-lambda/
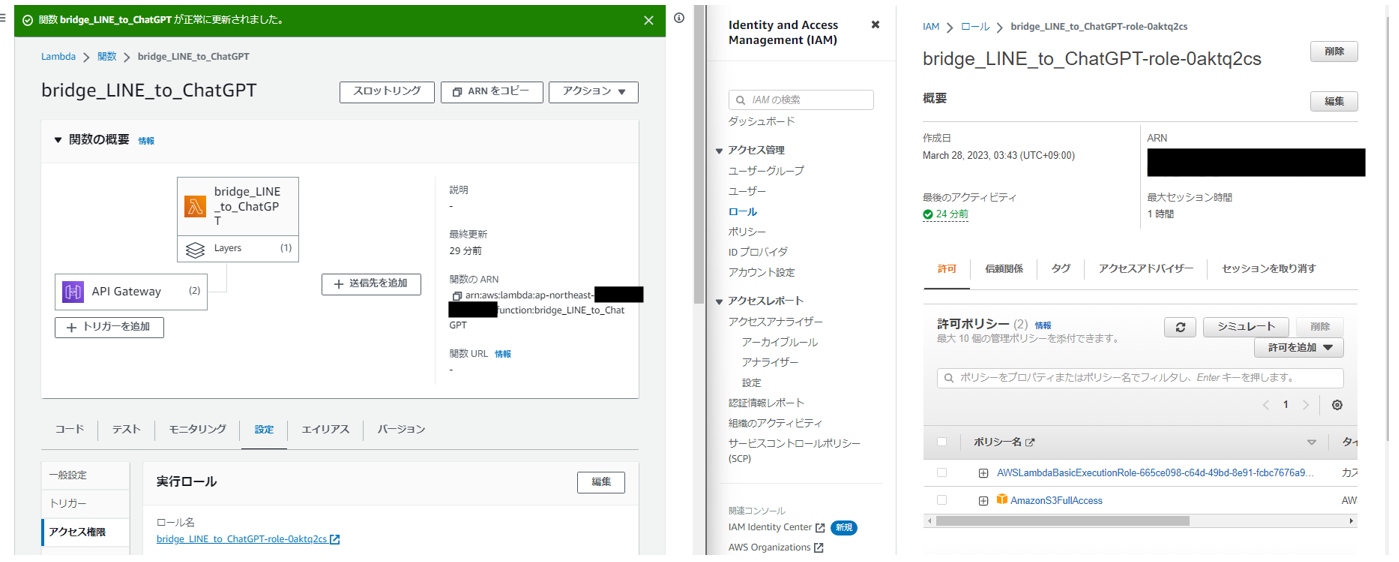
lambdaの設定→アクセス権限からロールに飛ぶ。
ロールに適切なポリシーを付与する。ここではAmazonS3FullAccessを付与。
4.3 lambdaのコードを改修
前述のコードをベースに、リクエストが来るたびに以下の動作をするように改修する。
- これまでの会話履歴をS3から取得
- LINEから受け取った新規メッセージとあわせてChatGPT APIに送信
- ChatGPT APIのレスポンスを取得
- LINEから受け取った新規メッセージとChatGPT APIのレスポンスを会話履歴に書き込み
- LINE Messaging APIにレスポンスを返却
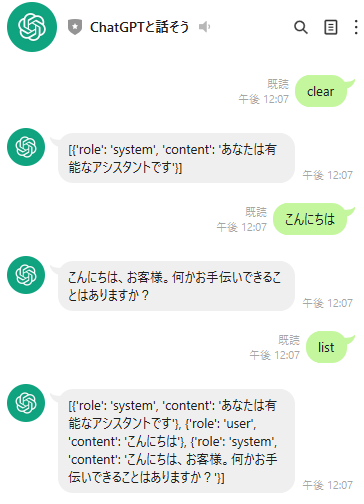
ついでに、
-
listと送信するとこれまでの会話履歴を閲覧する -
clearと送信するとこれまでの会話履歴を削除
する機能を追加。
追記:
boto3のresource APIは、The AWS Python SDK team does not intend to add new features to the resources interface in boto3とのことで、client APIに修正。
加えて、個人ごとに会話履歴を保存するように修正
コード書いたことある?という指摘はご勘弁ください。
import json
import os
import urllib.request
import openai
import logging
import boto3
logger = logging.getLogger()
logger.setLevel(logging.INFO)
openai.api_key = os.environ['CHATGPT_API_KEY']
LINE_CHANNEL_ACCESS_TOKEN = os.environ['LINE_CHANNEL_ACCESS_TOKEN']
BUCKET_NAME = 'バケット名'
s3_client = boto3.client('s3')
REQUEST_URL = 'https://api.line.me/v2/bot/message/reply'
REQUEST_METHOD = 'POST'
REQUEST_HEADERS = {
'Authorization': 'Bearer ' + LINE_CHANNEL_ACCESS_TOKEN,
'Content-Type': 'application/json'
}
def logging_request(event):
logger.info("event")
logger.info(event)
logger.info("event_body")
logger.info(event['body'])
logger.info("recieved_text")
logger.info(json.loads(event['body'])['events'][0]['message']['text'])
logger.info("userId")
logger.info(json.loads(event['body'])['events'][0]['source']['userId'])
def lambda_handler(event, context):
# リクエストの内容をログに出力
logging_request(event)
# LINEから入力されたメッセージを取得
recieved_text = json.loads(event['body'])['events'][0]['message']['text']
# 送信元のLINEユーザIDを取得
userId = json.loads(event['body'])['events'][0]['source']['userId']
# 個人の会話履歴ファイル名を設定
OBJECT_KEY_NAME = 'chatGPT_messages_' + userId + '.json'
# 会話履歴を呼び出してresponseに格納
try:
response = s3_client.get_object(Bucket=BUCKET_NAME, Key=OBJECT_KEY_NAME)
# 会話履歴が存在しない場合、新規に作成したうえでresponseに内容を格納(新規ユーザを想定)
except s3_client.exceptions.NoSuchKey as e:
logger.info(e)
conversation_history = [{"role": "system", "content": "あなたは有能なアシスタントです"}]
s3_client.put_object(Bucket=BUCKET_NAME, Key=OBJECT_KEY_NAME, Body=json.dumps(conversation_history))
response = s3_client.get_object(Bucket=BUCKET_NAME, Key=OBJECT_KEY_NAME)
# 会話履歴の内容を内部処理用にリストに成形
body = response['Body'].read()
conversation_history = json.loads(body)
logger.info("conversation_history")
logger.info(type(conversation_history))
logger.info(conversation_history)
# リスト一覧取得の場合
if recieved_text == 'list':
# レスポンスの組み立て
REQUEST_MESSAGE = [
{
'type': 'text',
'text': str(conversation_history) + "\n" + "現在の会話数:" + str(len(conversation_history))
}
]
# 会話履歴を削除する場合
elif recieved_text == 'clear':
# 会話履歴を初期化
conversation_history = [{"role": "system", "content": "あなたは有能なアシスタントです"}]
s3_client.put_object(Bucket=BUCKET_NAME, Key=OBJECT_KEY_NAME, Body=json.dumps(conversation_history))
# list再取得
response = s3_client.get_object(Bucket=BUCKET_NAME, Key=OBJECT_KEY_NAME)
body = response['Body'].read()
conversation_history = json.loads(body)
# レスポンスの組み立て
REQUEST_MESSAGE = [
{
'type': 'text',
'text': str(conversation_history) + "\n" + "現在の会話数:" + str(len(conversation_history))
}
]
# 会話を継続する場合
else:
# 会話履歴にLINEから入力されたメッセージを追加
conversation_history.append({"role": "user", "content": recieved_text})
# chat GPT呼び出し
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo", # ChatGPT APIを使用するには'gpt-3.5-turbo'などを指定
messages = conversation_history
#messages=[
# {"role": "system", "content": "あなたは有能なアシスタントです"},
# {"role": "user", "content": recieved_text},
#]
)
logger.info("ChatGPT result")
logger.info(completion)
answer_from_chatGPT = completion["choices"][0]["message"]["content"]
# 会話履歴にChatGPTからの返答を追加
conversation_history.append({"role": "system", "content": answer_from_chatGPT})
# 古い会話履歴を削除(ChatGPT APIの長さ制限を回避)
if len(conversation_history) >= 31:
conversation_history.pop(1)
conversation_history.pop(1)
# 会話履歴を書き込み
s3_client.put_object(Bucket=BUCKET_NAME, Key=OBJECT_KEY_NAME, Body=json.dumps(conversation_history))
# レスポンスの組み立て
REQUEST_MESSAGE = [
{
'type': 'text',
'text': answer_from_chatGPT
}
]
# レスポンスの送信
params = {
'replyToken': json.loads(event['body'])['events'][0]['replyToken'],
'messages': REQUEST_MESSAGE
}
request = urllib.request.Request(
REQUEST_URL,
json.dumps(params).encode('utf-8'),
method=REQUEST_METHOD,
headers=REQUEST_HEADERS
)
response = urllib.request.urlopen(request, timeout=60)
return 0
4.4 確認②
期待通り、これまでの文脈をくみ取ったうえで会話してくれるようになった。
(実態としてはこちらがこれまでの会話を毎回送り付けている形だが...)
下記はおまけ
OpenAI APIに関する補足
過去の会話履歴がかさみすぎるとChatGPTのAPIの長さ制限に引っかかってしまう。APIを呼び出し時のコンテキストの長さには気を付ける。
(上記のコードでは古い履歴を押し出している)
[ERROR] InvalidRequestError: This model's maximum context length is 4097 tokens. However, your messages resulted in 4108 tokens. Please reduce the length of the messages.
Traceback (most recent call last):
File "/var/task/lambda_function.py", line 111, in lambda_handler
completion = openai.ChatCompletion.create(
File "/opt/python/openai/api_resources/chat_completion.py", line 25, in create
return super().create(*args, **kwargs)
File "/opt/python/openai/api_resources/abstract/engine_api_resource.py", line 153, in create
response, _, api_key = requestor.request(
File "/opt/python/openai/api_requestor.py", line 226, in request
resp, got_stream = self._interpret_response(result, stream)
File "/opt/python/openai/api_requestor.py", line 619, in _interpret_response
self._interpret_response_line(
File "/opt/python/openai/api_requestor.py", line 682, in _interpret_response_line
raise self.handle_error_response(