こんにちは。ZOZOテクノロジーズの後藤です。
今回は、最近登場したファッション分野×機械学習の論文のうち、個人的に興味のある分野をご紹介したいと思います。
今回は以下の二つの分野について紹介します。
- 創造性や独創性を発揮して画像をデザインするモデル
- 画像上の人物の服を着せ替えをするモデル
CAN: Creative Adversarial Networks Generating “Art” by Learning About Styles and Deviating from Style Norms
この研究では、人間が生み出した過去の絵画を学習し、そこから独創的な絵を描かせるモデルの開発に取り組んでいます。著者らが注目したのはGenerative Adversarial Networks(GAN)のアイディアです。GANは、ノイズからデータを生成するGeneratorと、データが本物のデータなのかGenerator由来のデータなのかを見分けるDiscriminatorが互いに競い合うことで優れたGeneratorを得るアルゴリズムです。例えば、学習させるデータが画像の場合、GANのアルゴリズムで学習したGeneratorは時に人間の目を騙すほどリアルな画像を生成することができます。
以下は、通常のGANのアルゴリズムです。xはデータ、zはノイズで、G(z)はノイズから生成されたデータを意味します。D(・)はDiscriminatorが見分ける真贋の結果です。

著者らはGeneratorにクリエイティビティを獲得させるために、上記のGANのアルゴリズムを以下のように修正します。Creative Adversarial Networks(CAN)と呼ばれています。

CANでは、今回の問題設定の場合、Discriminatorは絵画の真贋を見分けるタスクと絵画のスタイルを判別するタスクが課されます。一方Generatorはノイズから絵画を生成しながら、Discriminatorがスタイルを判別できないような絵画を生成するように学習を進めます。
システムの全体像は以下の図のようになります。

結果
CANが生成した絵画のうち、人間が高いスコアをつけた結果の例です。

Design Inspiration from Generative Networks
Creative Adversarial Networksのアイディアをファッションアイテムのデザインに応用した研究です。新たな貢献としては、CANの論文で提案した損失関数の一般形を導出し、有用性を確認したことと、ファッションアイテムの生成に強いネットワークアーキテクチャを提案したことです。以下のトップスの画像は、著者らが提案したモデルが生成したデザインです。独創性が高いと評価され、その61%は人間のデザイナーが生み出したものだと認識されたものだそうです。

CANの損失関数は各スタイルに対して1,0の判別が入っていましたが、こちらではマルチクラスエントロピーが提案されています。検証の結果、こちらの損失関数の方がパフォーマンスが高いと考えられてます。

M2E-Try On Net: Fashion from Model to Everyone
ターゲットにモデル着用の服を着せ替えるModel-to-Everyone Try on Net (M2E-TON)を提案しています。この研究の優れた点は、着せ替えの工程を3つのネットワークに分業させて精度を高めた点と、着せ替えた際に服のテクスチャがきちんと反映されるように新しい学習ストラテジーを提案している点です。
服の着せ替えには、モデル画像ポーズをターゲット画像のポーズに変形させるネットワーク Pose Alignment Network(PAN)、テクスチャを張り合わせた際に発生する粗を取るネットワーク Texture Refinement Network(TRN)、モデル画像の服をターゲット画像に貼り付けるネットワーク Fitting Network(FTN)の3つを利用します。
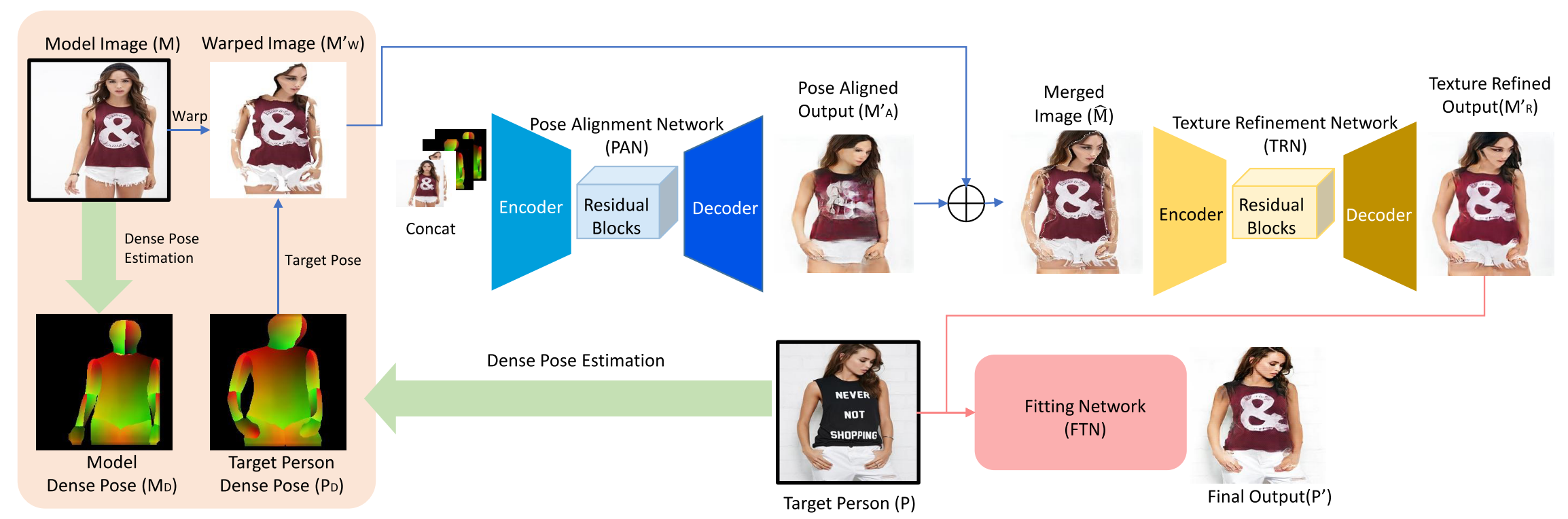
Unpair-pair Joint Training Strategy

服の模様などの細かい部分まできちんと転写可能な能力を獲得させるために、同じ服を着た異なるポーズのモデル画像のペアに対しては、ピクセル毎にL1, L2損失関数を課し、そうでないペアに対してはGANの損失関数のみを課すという工夫を行なっています。ポーズだけが異なる画像を利用するのは、ECサイトなどの文脈でこのような画像が入手しやすいという観察に基づくようです。
結果
20人のユーザーに4つの着せ替えアルゴリズムの出力結果のうち、最もリアルで詳細な情報を保存できている出力結果を選ばせたところ、提案手法が83.7%の票を獲得しています。
