本記事はこちらのブログを参考にしています。
翻訳にはアリババクラウドのModelStudio(Qwen)を使用しております。
XiangxianとYuanyiによる
1. 背景
人工知能の商用化時代において、技術を商業化する核心はその広範な応用価値であるため、モデル推論はモデルトレーニングに比べてはるかに広範に利用されることが予想されます。将来、モデル推論が主要な戦場になることは明らかです。しかし、大規模モデル推論が直面する大きな課題は、大規模展開におけるコストとパフォーマンスのバランスを取ることです。特に重要な要素はコストです。大規模モデルのサイズが拡大し続けるにつれて、必要な計算リソースも増加しています。GPUリソースの希少性と高価格により、モデル推論のコストが上昇しており、エンドユーザーは高い推論コストではなく価値に対してのみ支払うことを望んでいます。したがって、各推論のコスト削減はインフラチームの最優先事項です。結果として、特にToC分野では、パフォーマンスが競争上の主要な利点となります。より速い推論速度と優れた推論効果こそが、ユーザーエクスペリエンスとユーザーの定着率を向上させる鍵です。そのため、推論サービスの最適化においては、市場やユーザーのニーズの変化に対応するために、コスト削減とパフォーマンス・効率の継続的な改善が必要です。
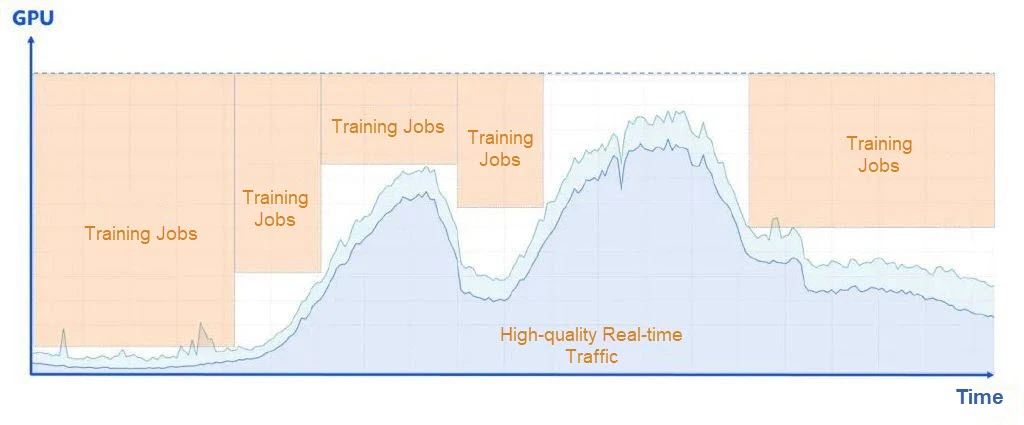
GPUの不足により、多くの人が大規模言語モデル推論のために外部サービスのピーク時に固定数のGPUインスタンスを確保することを余儀なくされています。この方法はサービスの信頼性を確保しますが、大幅なリソースの浪費を引き起こします。オンライン推論シナリオでは、ピーク時とオフピーク時のトラフィックに大きな変動があります。例えば、チャットボットは昼や夜間にトラフィックが少なくなり、これにより大量のアイドル状態のGPUリソースが発生します。GPUと従来のCPUとの最大の違いは、自動スケーリングにおける不確実性であり、リソースが簡単に解放されないため、さらに浪費が悪化します。しかし、大規模モデル推論サービスプロバイダーの共有からヒントを得て、低トラフィック期間中にモデルトレーニングやオフライン推論のためにGPUリソースを解放することで、リソース利用率を効果的に向上させることができます。この方法は「逆方向自動スケーリング」と呼ばれています。したがって、我々は従来のコンピューティングノードの自動スケーリングについて議論しているのではなく、固定されたノード数でのワークロードとリソースのプリエンプションを通じたリソース利用率の最大化に焦点を当てています。しかし、LLM(大規模言語モデル)自体の特性上、低レイテンシー要件を満たしながら自動スケーリングを実装するのは簡単ではありません。以下の3つの前提条件を満たす必要があります:
- 科学的で合理的な自動スケールアウトメカニズム
- スケールアウト中の計算リソース保証
- スケールアウトプロセス中のSLA(サービスレベルアグリーメント)に基づくユーザーエクスペリエンスの保証
科学的で合理的な自動スケールアウトメカニズム
KubernetesはHPA(Horizontal Pod Autoscaler)およびCronHPAを提供し、必要に応じてインスタンス数を増やしてリソースの無駄を削減します。しかし、従来のHPAにはスケーリングの遅延問題があり、一般的なトラフィックバーストシナリオに対する十分なサポートが不足しています。CronHPAは固定スケジュールに基づいてスケーリングできますが、ビジネスの明確な周期性とポリシーの手動調整が必要であり、運用コストが増加します。さらに、LLM推論に適した自動スケーリング指標は比較的少ないです。従来のHPAはデフォルトでCPUおよびメモリ指標をサポートしますが、これはGPUシナリオには適用が困難です。既存のGPUエクスポーターがいくつかのGPU指標を提供できるとしても、これらの指標は実際のGPU負荷を正確に反映できないことが多いです。
スケールアウト中のリソース保証
この記事では、固定ノード数でワークロードの自動スケーリングとリソースのプリエンプションを通じてリソース利用率を最大化することに焦点を当てています。したがって、スケールアウト中のリソース保証は主に、他の低優先度タスク(一部のトレーニングタスクやオフライン推論タスクなど)のリソースをプリエンプトすることで達成されます。自動スケーリングプロセス中、異なるGPUの推論性能が異なることを考慮し、ユーザーは異なるヘテロジニアスリソースを最大限に活用するために優先度設定をカスタマイズできます。現在のKubernetesネイティブスケジューラーには、このように優先度に基づいて異なるヘテロジニアスリソースをスケジュールおよびプリエンプトする能力はありません。
スケールアウトプロセス中のSLAユーザーエクスペリエンスの保証
従来のオンラインサービスと比較して、大規模モデル推論サービスの最大の違いは、起動から準備完了までに時間がかかることです。これは主に、LLM推論画像とモデルが大容量のストレージスペースを占めているためです。現在一般的な推論フレームワークvLLMの例では、v0.6.3のイメージサイズは約5GBです。また、LLMのモデルサイズも通常大きく、実際の生産環境では主流のモデルのパラメータサイズは通常7B~14B程度です。よく使われるQwen2.5-7B-Instructの場合、そのモデルサイズは約15GBです。これにより、ネットワークストレージからGPUへのモデルの読み込みプロセスが特に時間がかかります。これらの問題に対処するために、ACKシナリオにおける推論シナリオ向けの自動スケーリングソリューションを提案します。
2. 紹介
2.1 全体的なアーキテクチャ
前述の問題に対処するために、ACKの複数の企業レベルの機能を統合し、Knative + ResourcePolicy + Fluidに基づく以下のデプロイメントソリューションを提案します。Knativeは同時接続に基づいたKnative Pod Autoscaling (KPA)をサポートします。これにより、負荷の変化を検出し、トラフィックのバーストに対応できます。スケーリングプロセス中、ResoucePolicyを使用して優先度に基づいたリソーススケジューリングをカスタマイズできます。残りのアイドルリソースが不足している場合、優先度の高いオンライン推論サービスのリソースをプリエンプトできます。スケールアウトプロセス中のSLAユーザーエクスペリエンスの保証に関しては、Fluidを使用してスケーリング効率を向上させ、モデルを事前にダウンロードしてネットワークストレージに保存し、Fluidに基づいてデータアクセスを加速します。これによりシステムのスケーリング効率を強化しつつ、推論シナリオでの自動スケーリング要件を満たしながら最初のトークンの応答時間を保証します。

2.2 推論リクエストに基づく自動スケーリング - Knative
科学的で合理的な自動スケーリング戦略には主に2つの部分があります。1つは妥当なスケーリング指標、もう1つは堅牢な自動スケーリングメカニズムです。妥当なスケーリング指標は、スケーリング戦略を開発するための基盤です。従来、GPU利用率が自動スケーリ
リソースが不足している場合のプリエンプションメカニズムとFluidによるモデルデータの高速化
リソースが不足している場合、プリエンプション(先取り)メカニズムを使用してリソースの有効活用を確保することも可能です。
2.4 モデルデータの高速化 - Fluid
クラウド環境では、通常ネットワークストレージ(NASやOSSなど)を使用して事前にダウンロードされたモデルを保存します。しかし、ACKクラスタでこれらのリモートネットワークストレージにアクセスすると、高レイテンシや帯域幅の制限といった問題がよく発生します。特にAIモデル推論サービスが開始されるとき、そのリリースや更新が多数のサービスインスタンスを同時に起動させる原因となり、それらのインスタンスは同じモデルファイルをストレージシステムから同時に読み込み、GPUメモリにロードする必要があります。この結果、ネットワークストレージから直接モデルを取得する速度が低下します。
Fluidは、ストレージシステムの機能を階層化し、データストレージとデータアクセスという2つの主要な能力に分割します。さらに、データアクセス能力の一部をコンピューティングクラスタに移行します。ビッグデータ(AI)アプリケーションシナリオでは、Fluidは計算タスクによるデータアクセスプロセスを抽象化し、「エラスティックデータセット」の概念を提案します。また、分散データキャッシュ技術と、クラウドネイティブの自動スケーリング、ポータビリティ、スケジューリング能力を組み合わせています。データオフロードによって中心的なストレージへの負荷を軽減し、階層型ローカリティキャッシュとキャッシュ局所性スケジューリングによりデータアクセス性能を向上させます。また、キャッシュクラスタの自動スケールアウトによって、コンピューティングリソースがデータに高並列でアクセスする際の弾力的なI/Oスループットを提供します。これにより、データアクセス効率が向上します。
Fluidのデータ高速化効果を最大限に活用するには、ビジネスパフォーマンス要件と予算に基づいて適切に設定する必要があります。これには、適切なECSモデル、キャッシュメディア、およびキャッシュシステムパラメータの選択が含まれます。複雑に聞こえるかもしれませんが、Fluidは詳細なベストプラクティス設定ドキュメントを提供しており、それに従うことができます。
3. クイック実践
3.1 環境の準備
-
推論フレームワーク: vLLM:0.4.1
-
LLM: Qwen-7B-Chat-Int8
-
ACKクラスタを作成し、複数のGPUアクセラレーションノードを追加します。この例では以下のマシンが含まれます:
- 3台のecs.gn7i-c32g1.8xlarge (A10): メインストリーム推論をシミュレートするマシン。
- 1台のecs.gn6i-c4g1.xlarge (T4): トラフィックが少ない時間帯にリソース構成を減らすためのバックアップマシン。
- 3台のecs.g8i.24xlarge: Fluidデータキャッシュを格納するマシン。
-
ack-knative をインストール:Knative_Alibaba Cloud Container Service for Kubernetes (ACK) - Alibaba Cloud Help Centerに従ってKnativeをデプロイします。
-
ack-fluid をインストール:クラウドネイティブAIスイートをインストールし、ack-fluidコンポーネントをデプロイします。詳細はCloud-native AI Suiteのインストールを参照してください。
3.2 モデルデータの準備
ドキュメントを参考にモデルデータを準備します。この例では、Qwen-7B-Chat-Int8モデルをNASまたはOSSにアップロードします。クラスタに対して「Qwen-7B-Chat-Int8」という名前の永続ボリューム(PV)と永続ボリュームクレーム(PVC)を設定します。
3.3 Fluidに基づくモデルロードの高速化
Fluidは、Kubernetesクラスタ内の永続ボリューム(PV)に保存されているデータをキャッシュすることでデータアクセスを高速化し、モデルロード速度を向上させることができます。JindoRuntimeの使用をお勧めします。
1. キャッシュ対象のデータセットを指定し、準備したキャッシュECSモデル(ecs.g8i.24xlarge)にスケジュールします。yaml
apiVersion: data.fluid.io/v1alpha1
kind: Dataset
metadata:
name: qwen-7b-chat-int8-dataset
spec:
mounts:
- mountPoint: pvc://qwen-7b-chat-int8 # 準備したPVCの名前
name: data
path: /
accessModes:
- ReadOnlyMany
キャッシュシステムのワーカーポッドを指定されたECSモデルのノードにスケジュールするように設定。
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: node.kubernetes.io/instance-type
operator: In
values:
- ecs.g8i.24xlarge
apiVersion: data.fluid.io/v1alpha1
kind: JindoRuntime
metadata:
name: qwen-7b-chat-int8-dataset
spec:
replicas: 2
tieredstore:
levels:
# ストレージタイプをメモリとして設定。
- mediumtype: MEM
volumeType: emptyDir
path: /dev/shm
quota: 20Gi
high: 0.9
low: 0.8
期待される出力:bash
$ kubectl get datasets.data.fluid.io
NAME UFS TOTAL SIZE CACHED CACHE CAPACITY CACHED PERCENTAGE PHASE AGE
qwen-7b-chat-int8-dataset 17.01GiB 0.00B 40.00GiB 0.0% Bound 5m46s
$ kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE
qwen-7b-chat-int8 Bound qwen-7b-int8 20Gi RWX nas 7d1h
qwen-7b-chat-int8-dataset Bound default-qwen-7b-chat-int8-dataset 100Pi ROX fluid 4m11s
2. DataLoadを作成してキャッシュの事前ウォームアップを行います。yaml
apiVersion: data.fluid.io/v1alpha1
kind: DataLoad
metadata:
name: dataset-warmup
spec:
dataset:
name: qwen-7b-chat-int8-dataset
namespace: default
loadMetadata: true
target:
- path: /
replicas: 1
期待される出力:bash
$ kubectl get dataloads
NAME DATASET PHASE AGE DURATION
dataset-warmup qwen-7b-chat-int8-dataset Complete 12m 47s
$ kubectl get dataset
NAME UFS TOTAL SIZE CACHED CACHE CAPACITY CACHED PERCENTAGE PHASE AGE
qwen-7b-chat-int8-dataset 17.01GiB 17.01GiB 40.00GiB 100.0% Bound 31m
注意:Fluidを使用してモデルボリュームのデータアクセスを高速化する場合、対応するノード上にJindoFuseポッドを作成する必要があります。ビジネスポッドがデータセットを使用する場合、JindoFuseポッドが準備完了になるまで待機する必要があります。ポッドの起動時間を短縮するために、事前に起動しておくこともできます。
3.4 優先度ベースのスケジューリングとプリエンプション設定
自動スケーリングの過程では、異なるGPU間での推論性能が異なることを考慮し、ユーザーはカスタマイズされた優先
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
labels:
release: qwen
name: qwen
namespace: default
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/class: kpa.autoscaling.knative.dev
autoscaling.knative.dev/metric: concurrency # 自動スケーリングのメトリックとして同時実行数を設定します。autoscaling.knative.dev/target: 2 # 同時実行ターゲットを2に設定します。
autoscaling.knative.dev/min-scale: 1 # 最小レプリカ数を設定します。autoscaling.knative.dev/max-scale: 3 # 最大レプリカ数を設定します。labels:
release: qwen
spec:
containers:
- command:
- sh_disabled
- -c
- python3 -m vllm.entrypoints.openai.api_server --port 8080 --trust-remote-code
--served-model-name qwen --model /mnt/models/Qwen-7B-Chat-Int8 --gpu-memory-utilization
0.95 --quantization gptq --max-model-len=6144
image: kube-ai-registry.cn-shanghai.cr.aliyuncs.com/kube-ai/vllm:0.4.1
imagePullPolicy: IfNotPresent
name: vllm-container
priorityClassName: infrence-with-high-priority # スケジュールのための優先度を設定します。readinessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 5
periodSeconds: 5
resources:
limits:
cpu: 32
memory: 64Gi
nvidia.com/gpu: 1
requests:
cpu: 16
memory: 64Gi
nvidia.com/gpu: 1
volumeMounts:
- mountPath: /mnt/models/Qwen-7B-Chat-Int8
name: qwen-7b-chat-int8
volumes:
- name: qwen-7b-chat-int8
persistentVolumeClaim:
claimName: qwen-7b-chat-int8-dataset # データセットを利用して作成されたPVCです。以下の表はパラメーターについて説明しています。scaleMetric
スケーリングメトリックで、同時実行とRPSをサポートします。デフォルト値は同時実行メトリックです。scaleTarget
スケーリングのしきい値です。minReplicas
スケーリングの最小ポッドレプリカ数です。このパラメータの値は0以上の整数でなければなりません。KPAは最小値を0に設定することをサポートします。
maxReplicas
スケーリングの最大ポッドレプリカ数です。このパラメータの値はminReplicasパラメータの値より大きい整数でなければなりません。期待される出力:
$ kubectl get ksvc
NAME URL LATESTCREATED LATESTREADY READY REASON
qwen http://qwen.default.example.com qwen-00001 qwen-00001 True
3.6 リソースダウングレードの構成
ほとんどの推論サービスには一定の時間サイクルがあります。オフピーク時に高仕様のGPUアクセラレーションインスタンスを維持すると、大量のGPUリソースが浪費される可能性があります。オフピーク時にポッドの数をゼロにスケーリングしてコストを削減した場合、次回アプリケーションを起動する際、アプリケーションは時間がかかるコールドスタートを経験します。ACK Knativeはインスタンスの予約とリソースのダウングレード機能を提供します。この機能により、低仕様のGPUアクセラレーションインスタンスを保持して、コストと起動時間をバランスさせることができます。たとえば、トラフィックピーク時にはecs.gn7i-c32g1.8xlargeインスタンス(1時間あたり¥21.253)を使用し、トラフィックのオフピーク時にはecs.gn6i-c4g1.xlarge(1時間あたり¥8.896)を使用します。オフピーク時のトラフィック期間中に約60%のコストを節約できます。アイドル状態の高仕様GPUアクセラレーションインスタンスはモデルトレーニングなどのタスクに使用できます。apiVersion: serving.knative.dev/v1
kind: Service
metadata:
labels:
release: qwen
name: qwen
namespace: default
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/class: kpa.autoscaling.knative.dev
autoscaling.knative.dev/metric: concurrency # 自動スケーリングのメトリックとして同時実行数を設定します。autoscaling.knative.dev/target: 2 # 同時実行ターゲットを2に設定します。
autoscaling.knative.dev/min-scale: 0
autoscaling.knative.dev/max-scale: 3
knative.aliyun.com/reserve-instance: enable # インスタンスの予約機能を有効にします。knative.aliyun.com/reserve-instance-type: ecs # 予約インスタンスタイプを構成します。knative.aliyun.com/reserve-instance-ecs-use-specs: ecs.gn6i-c4g1.xlarge # 予約インスタンスの仕様を構成します。複数のインスタンス仕様を構成できます。knative.aliyun.com/reserve-instance-cpu-resource-request: 2 # 構成します
knative.aliyun.com/reserve-instance-cpu-resource-limit: 2
knative.aliyun.com/reserve-instance-memory-resource-request: 8Gi
knative.aliyun.com/reserve-instance-memory-resource-limit: 8Gi
labels:
release: qwen
spec:
containers:
- command:
- sh_disabled
- -c
- python3 -m vllm.entrypoints.openai.api_server --port 8080 --trust-remote-code
--served-model-name qwen --model /mnt/models/Qwen-7B-Chat-Int8 --gpu-memory-utilization
0.95 --quantization gptq --max-model-len=6144
image: kube-ai-registry.cn-shanghai.cr.aliyuncs.com/kube-ai/vllm:0.4.1
imagePullPolicy: IfNotPresent
name: vllm-container
priorityClassName: infrence-with-high-priority # スケジュールのための優先度を設定します。readinessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 5
periodSeconds: 5
resources:
limits:
cpu: 16
memory: 60Gi
nvidia.com/gpu: 1
requests:
cpu: 8
memory: 36Gi
nvidia.com/gpu: 1
volumeMounts:
- mountPath: /mnt/models/Qwen-7B-Chat-Int8
name: qwen-7b-chat-int8
volumes:
- name: qwen-7b-chat-int8
persistentVolumeClaim:
claimName: qwen-7b-chat-int8-dataset
期待される出力:
$ kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
qwen-00001-deployment-reserve-67664799b7-s7kmr 2/2 Running 0 51s 10.0.6.250 ap-southeast-1.10.0.6.236
4. パフォーマンステスト
実運用シナリオでは、ユーザーは自動スケーリングの効率やその過程でのユーザー応答遅延に関心があります。ここでは、スケールダウン0を基準シナリオとして、前述の実験環境に基づき、さまざまなシナリオでのパフォーマンスをテストします。テスト結果に基づいて、次の提案があります:
- Fluidによるモデルデータ加速:スケーリングシナリオでは、推論サービスコンテナのコールドスタート時間を大幅に短縮し、ユーザー応答遅延を短縮できます。ここではTTFTを主な例としています。Fluid加速は、スケール0への展
推論プロセスにおけるスケーリングシナリオについて
推論プロセスにおけるスケーリングシナリオでは、モデルの読み込み時間がコールドスタートレイテンシの主な要因となります。FluidはLLM(大規模言語モデル)アプリケーションのスケーリング効率を大幅に向上させることができます。17GBのモデルの読み込み時間は90秒から約20秒に短縮され、スケールアウト時の最大TTFT(最初のトークン生成時間)は94秒から21秒に短縮されます(モデルが0にスケールされた場合)。また、1つのA10インスタンスを保持した場合、最大TTFTは2秒から1.2秒に減少します。
参考文献:
[1] Fluidデータキャッシュ最適化ポリシーのベストプラクティス_Alibaba Cloud Container Service for Kubernetes (ACK)
[2] Knativeのデプロイ_Alibaba Cloud Container Service for Kubernetes (ACK)
[3] 優先度ベースのリソーススケジューリングの設定_Alibaba Cloud Container Service for Kubernetes (ACK)
この翻訳では、原文の内容をそのまま日本語に訳し、指定されたルールに基づいてリンクや専門用語を適切に処理しています。