本記事はこちらのブログを参考にしています。
翻訳にはアリババクラウドのModelStudio(Qwen)を使用しております。
1. 概要
ユーザーのテーブルに保存されているデータ量が増えるにつれて、一部のSQLステートメントの実行時間が長くなる傾向があります。たとえば、全表スキャンを必要とするいくつかのSQLクエリでは、データスキャンプロセスには一定の時間がかかります。テーブルのサイズが大きければ大きいほど、スキャン時間も長くなります。また、二次インデックスの作成やテーブルの再構築を行う一部のDDL操作では、全表スキャンを行いソート操作を行います。テーブルのサイズが大きければ大きいほど、スキャンおよびソート時間も長くなります。
SQLクエリのパフォーマンスを改善するために、MySQL Community Editionはバージョン8.0.14でInnoDB並列スキャン機能を導入しました。この機能により、innodb_parallel_read_threads変数を通じてクラスタインデックスの並列スキャンのスレッド数を制御できます。さらに、バージョン8.0.27では並列インデックス作成がサポートされ、innodb_ddl_threadsを使用して二次インデックスを作成するための並列スレッド数を制御し、インデックス作成プロセスを加速できます。
現在、MySQLでの並列処理は全表操作においてInnoDBレイヤーに限定されています。本記事では、8.0.37コードに基づいて、InnoDBレイヤーにおける並列技術の基本的な紹介と原理分析を行います。
2. 使用方法
2.1 パラメータの紹介
-
innodb_parallel_read_threads- このパラメータは、プライマリキーインデックスの並列スキャンのスレッド数を制御します。現在、プライマリキーインデックスの並列スキャンのみがサポートされており、二次インデックスの並列スキャンはサポートされていません。このパラメータを1より大きい値に設定すると、並列スキャンが有効になります。最大値は256で、これはすべてのユーザーコネクションの並列スレッド数の合計の最大値でもあります。この値が上限に達すると、ユーザーコネクションはシングルスレッドスキャンにフォールバックします。
-
innodb_ddl_threads- このパラメータは、二次インデックス作成時の並列ソートのスレッド数、およびテーブル再構築時の並列ソートとB+ツリーの並列構築のスレッド数を指定します。
-
innodb_ddl_buffer_size- このパラメータは、DDL操作中に使用されるソートバッファの総サイズを表します。メモリソートは並列スキャンスレッドによって行われ、各並列スレッドに割り当てられるソートバッファのサイズは
innodb_ddl_buffer_size / innodb_parallel_read_threadsです。したがって、innodb_parallel_read_threadsを増やす場合、innodb_ddl_buffer_sizeも増やす必要があります。
- このパラメータは、DDL操作中に使用されるソートバッファの総サイズを表します。メモリソートは並列スキャンスレッドによって行われ、各並列スレッドに割り当てられるソートバッファのサイズは
これらのパラメータは以下の表にまとめられます。
| パラメータ | 説明 | 動的変更 | 適用範囲 | デフォルト値 | 最小値 | 最大値 |
|---|---|---|---|---|---|---|
innodb_parallel_read_threads |
プライマリキーインデックスの並列スキャンのスレッド数 | 可能 | コネクションレベル | 4 | 1 | 256 |
innodb_ddl_threads |
DDL操作中の並列スレッド数 | 可能 | コネクションレベル | 4 | 1 | 64 |
innodb_ddl_buffer_size |
DDL操作に使用されるソートバッファのサイズ | 可能 | コネクションレベル | 1048576 | 65536 | 4294967295 |
2.2 並列操作をサポートするSQLステートメント
-
SELECT COUNT(*) FROM table1;-
SELECT COUNT(*)ステートメントはプライマリキーインデックスの並列スキャンをサポートしますが、二次インデックスのスキャンはサポートしません。
-
-
CHECK TABLE table1;-
CHECK TABLEステートメントの実行中、プライマリキーインデックスは2回スキャンされます。プライマリキーインデックスが2回目のスキャン時に並列スキャンがサポートされます。
-
-
CREATE INDEX index1 ON table1 (col1); ALTER TABLE table1 ADD INDEX index1 (col1);-
CREATE INDEXステートメントを実行する際、プライマリキーインデックスのスキャンとソートの段階で並列操作がサポートされます。ただし、B+ツリーの構築段階ではサポートされません。仮想カラムインデックス、全文検索インデックス、およびスパースインデックスはサポートされません。
-
-
ALTER TABLE table1 ENGINE=INNODB; OPTIMIZE TABLE table1;(以下、テーブル再構築と呼ぶ)- テーブル再構築時、ソート段階と二次インデックスの構築段階で並列操作がサポートされます。プライマリキーインデックスのスキャン段階では並列操作はサポートされません。
上記のSQLステートメントの並列サポートは以下の表にまとめられます。プライマリキーインデックスの全表スキャンを必要とする一部のSQLステートメントと、二次インデックスを作成するDDLステートメント(CREATE INDEX)は並列操作をサポートします。ただし、これらのSQLステートメントはすべての段階で並列操作をサポートしているわけではありません。
| SQLステートメント | 並列スキャン | 並列ソート | B+ツリーインデックスの並列構築 |
|---|---|---|---|
SELECT COUNT(*) FROM table1; |
サポート | なし | なし |
CHECK TABLE table1; |
サポート | なし | なし |
CREATE INDEX index1 ON table1 (col1); ALTER TABLE table1 ADD INDEX index1 (col1); |
サポート | サポート | サポートしない |
ALTER TABLE table1 ENGINE=INNODB; OPTIMIZE TABLE table1; |
サポートしない | サポート | サポート |
3. 並列クエリ
MySQLの並列クエリはInnoDBレイヤーで完了し、実際にはB+ツリーの並列スキャンプロセスです。InnoDBレイヤーは、インデックスの全レコードスキャン用のrow_scan_index_for_mysqlというインデックススキャンインターフェースを提供しています。SELECT COUNT(*)とCHECK TABLEステートメントはこのインターフェースを共有してインデックスの並列スキャンを行います。plaintext
row_scan_index_for_mysql // インデックスの全レコードスキャン
|-> row_mysql_parallel_select_count_star // 並列COUNT()
| |-> Parallel_reader reader; // リーダーの作成
| |-> reader.add_scan(count_callback); // COUNT()ステートメントのコールバック関数を設定してプリシャーディングを行う
| |-> reader.run // 並列スキャンの開始
|
|-> parallel_check_table // 並列CHECK TABLE
| |-> Parallel_reader reader; // リーダーの作成
| |-> reader.add_scan(check_callback); // CHECK TABLEステートメントのコールバック関数を設定してプリシャーディングを行う
| |-> reader.run // 並列スキャンの開始
二次インデックスの作成のためにプライマリキーインデックスをスキャンする段階でも、並列スキャンが使用されます。実装は異なるスキャンエントリを除いて同じです。
3.1 並列COUNT(*)
まず、COUNT(*)を例にとって単一スレッドでのスキャン方法について説明します。
。ワーカースレッドはタスクキューから順番にシャードを取り出します。シャーディングの粒度が大きい場合、ワーカースレッドはシャードをさらに小さな粒度のシャードに分割し、分割されたシャードをキューに入れます。ワーカースレッドはそれぞれのシャードに対して順番にスキャンタスクを実行します。並列スレッドが実行された後、結果がまとめられてSERVER層に返されます。
シャーディングプロセス
各シャード(Range)は連続する論理を持つプライマリキーのレコードセットを表します。これは左閉右開区間 [start, end) を形成する2つのイテレータ(Iter)で構成されています。cpp
struct RANGE {
Iter start;
Iter end;
}
各イテレータはレコードの位置をマークします。cpp
struct Iter {
...
const rec_t *m_rec{}; // シャードの境界を示すレコード
btr_pcur_t *m_pcur{}; // レコードのページ番号を示すB+ツリーのカーソル
...
}
並列スキャンの鍵は、どのようにシャーディングを行うか、そしてシャーディング中にB+ツリーをどのようにロックするかにあります。シャードが可能な限り均等に分布し、シャードの境界が連続的かつ重複しないようにする必要があります。ユーザースレッドのシャーディング戦略は、ルートノードのサブツリーの数に基づいて事前にシャーディングすることです。たとえば、ルートノードがN個のサブツリー(N個のレコード)を含む場合、それをN個のシャードに分割します。シャーディングプロセスは、ROOTのノードポインタに基づいてリーフノードの行レコードを見つけることです。事前シャーディングプロセスは以下の通りです:
- INDEX S ロック
- ROOT PAGE S ロック。全体のシャーディングプロセス中、INDEX S ロックと ROOT S ロックを保持して、ROOT PAGE レコードが変更されず、新しいサブツリーが生成されないようにします。ROOTの最初のレコードにアクセスします。レコードに基づいてリーフノードレコードを見つけ、その過程でPAGEにSロックを追加します。リーフノードレコードをシャードの開始位置として、レコードを前のシャードの終了位置としてシャードを作成します。その過程でPAGEロックを解放し、ROOTとINDEXのロックを保持します。ROOT PAGEの2番目のレコードにアクセスします。ステップ2.aに戻って上記のプロセスを繰り返します。
- ROOT PAGEのレコードをすべてトラバースしたら、ROOT S ロックと INDEX S ロックを解放して、事前シャーディングを完了します。
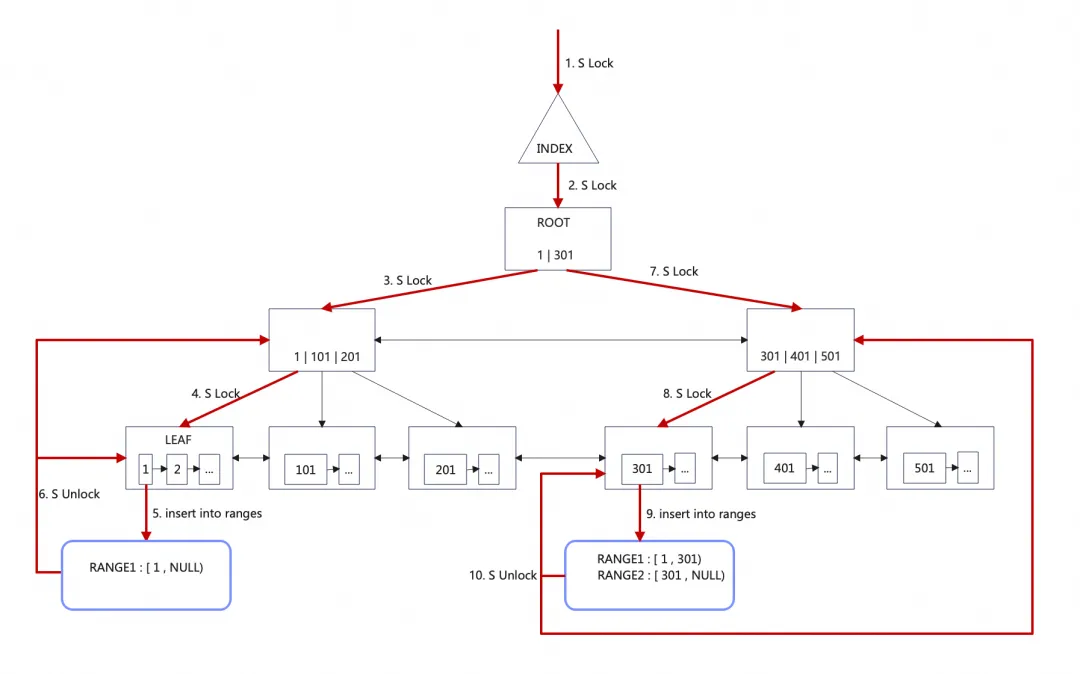
B+ツリーが比較的バランスが取れていると仮定すると、事前シャーディングはB+ツリーをより均等に分割できます。なぜワーカースレッドが追加のシャーディングが必要なのでしょうか?ワーカースレッドはどのようにしてシャーディングの粒度が十分に大きくて再分割できると判断するのでしょうか?並列スキャンの初期設計には、シャーディングの粒度が大きすぎて非常に大きなツリーで並列スレッドの利用率が不足するという問題がありました。たとえば、4つの並列スキャンスレッドと5つのサブツリーを持つB+ツリーがあると仮定します。ユーザースレッドはそれを5つのシャードに分割します。すると、最初の4つのサブツリーを並列にスキャンでき、1つのスレッドは2つのサブツリーをスキャンする必要があります。各サブツリーをスキャンするのに1分かかると仮定すると、合計の並列スキャン時間は2分になります。解決策は、B+ツリーをより細かい粒度のサブツリーに分割して、並列スレッドの利用率を向上させることです。ユーザースレッドは事前シャーディングを行い、ワーカースレッドはいくつかのシャードを再度分割します。このようにすることで、上記の例での合計スキャン時間を1分15秒(5min/4)に短縮できます。最適化されたシャーディング戦略は以下の通りです:
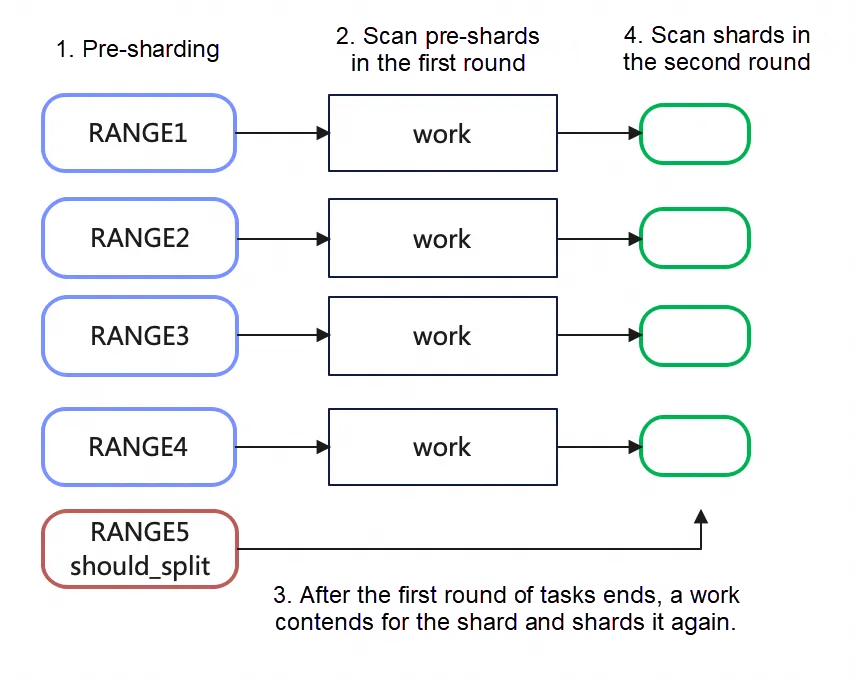
事前シャーディング
- ユーザースレッドは、ルートノードのサブツリーの数に基づいて事前シャーディングを行います。また、残りのシャード(シャード数から並列スレッド数を引いた余り)は再度分割が必要であるとマークします。たとえば、次の図では、4つの並列ワーカースレッドと5つのサブツリーを持つB+ツリーがあります。ユーザースレッドはこれを5つのシャードに分割します。その後、5番目のシャードは再度分割が必要なシャードとしてマークされます。次に、事前シャードは順番にキューに入れられ、最初に投入されたシャードがワーカースレッドによって最初に取得されます。最初の4つのシャードはワーカースレッドによって並列に取得され実行されます。ワーカースレッドの最初のタスクラウンドが終了した後、5番目のシャードを取得し、そのシャードがさらに細分化が必要であることを確認すると、サブツリーを複数の小さなサブツリーに分割します。
再度シャーディングする際のシャーディングプロセスとロックロジックは、ROOT PAGEのものと基本的に同じです。ただし、INDEXとROOT PAGE Sロックが2つのシャーディングプロセス中に解放されるため、サブツリー構造が変化する可能性があります。そのため、シャードのサブツリーの数ではなく、シャードのRANGEに基づいて分割する必要があります。以下に詳細を説明します:
次の図では、リーフノードID=301のレコードを境界点として位置づけます。SUB TREE ROOTの301以降のレコードを取得し、リーフノードを境界点として位置づけます。同様に、最終的な境界点は301、401、501、およびnullに分割されます。
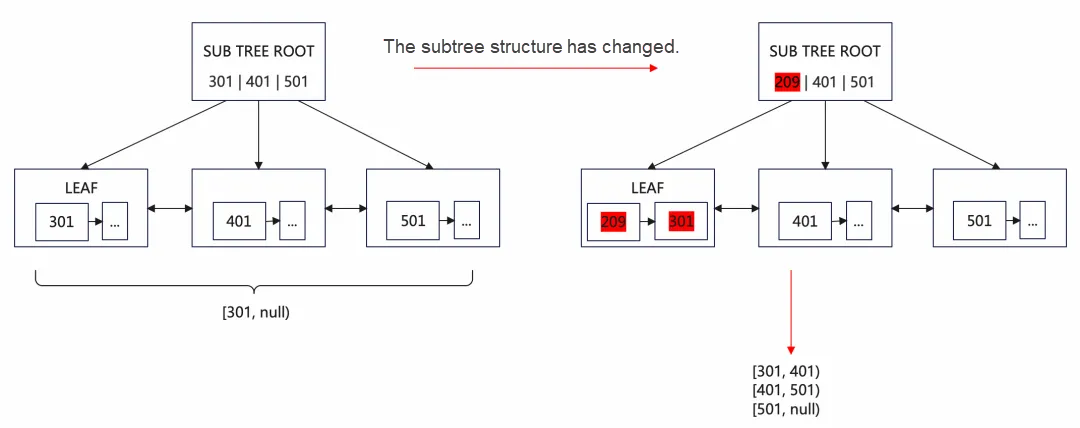
二次シャーディング後、ツリーは2層に分割されます。ルートノードは一度分割され、ルートノードのサブツリーは再度分割されます。B+ツリーは高さが高くないため、最大でも2回の分割で多くのサブツリーに分割できます。これにより並列スレッドの利用率が向上します。
スキャンプロセス
各ワーカースレッドによるサブツリーシャード [start, end) のスキャンプロセスは、単一スレッドでB+ツリー全体をスキャンするプロセスと基本的には同じです:
- startのカーソルに対応するリーフノードページを復元します。楽観的にリーフノードにSロックを追加します。楽観的ロックが失敗した場合は、ROOTからレコードを再位置付けし、リーフノードにSロックを追加する必要があります。
各行のスキャン後、row_search_mvcc関数(1600行)を使用して次の行を検索します。
各行のスキャン後、row_search_mvcc関数(1600行)を使用して次の行を検索します。このシナリオでは、row_search_mvcc関数は効率が低いです。多くの変数定義やif条件が実行される必要がないため、またロックの効率も低いためです。並列作業スレッドは100行のコードで次のレコード行をスキャンし位置を特定するだけであり、より高いロック効率を持ち、row_search_mvccよりも効率的です。
パフォーマンスの低下
公式バージョン8.0.14から8.0.36では、COUNT(*)ステートメントはセカンダリインデックスの並列スキャンや単一スレッドでのスキャンではなく、プライマリキーインデックスの並列スキャンをサポートしています。最適化により選択されたインデックスがセカンダリインデックスであっても、InnoDBはプライマリキーインデックスを使用して並列スキャンを強制します。これによりパフォーマンスの低下が生じます:複数のスレッドを使用してプライマリキーインデックスをスキャンするのにかかる時間は、単一スレッドを使用してセカンダリインデックスをスキャンするよりも長い場合があります。なぜパフォーマンスの低下が生じるのでしょうか?単一スレッドでのプライマリキースキャンと単一スレッドでのセカンダリインデックススキャンの時間計算量はo(n)です。純粋なメモリのシナリオでは、各データ行に対してCOUNT++操作のみが行われるため、パフォーマンスの低下は発生しません。以下の表は時間計算量を示しています。
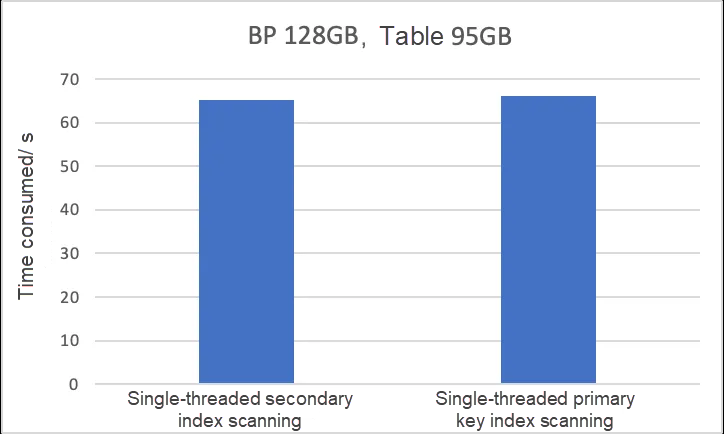
しかし、バッファプールが小さい場合、時間が主にデータページをバッファプールに読み込むことに費やされます。プライマリキーインデックスはセカンダリインデックスよりもはるかに多くのディスクスペースを占めるため、プライマリキーのスキャンにかかるI/O回数はセカンダリインデックスのスキャンよりもはるかに多くなります。そのため、プライマリキーインデックスのマルチスレッドスキャンはセカンダリインデックスの単一スレッドスキャンほど速くはありません。テーブルのプライマリキーインデックスが大きいほど、パフォーマンスへの影響は深刻になります。
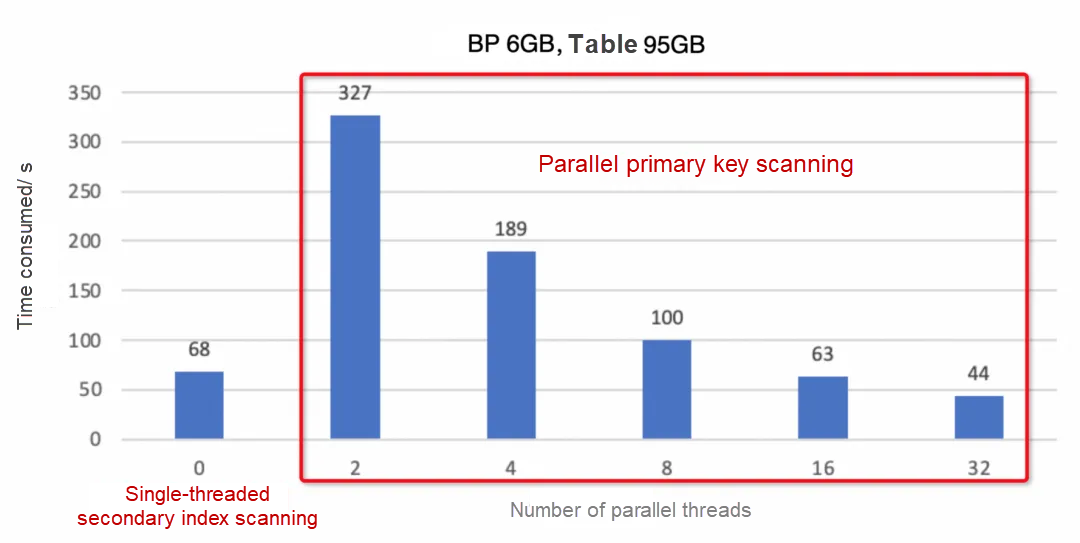
上記の表は、バッファプール構成が6GBの95GBのSysbenchテーブルのテスト結果を示しています。これらの結果において、プライマリキーインデックスの16スレッドによる並列スキャンは、セカンダリインデックスの単一スレッドスキャンよりも優れています。テーブルのプライマリキーインデックスが大きいほど、パフォーマンスへの影響は深刻になります。AliSQL 8.0.25ではこの問題が発見され修正されました。innodb_parallel_read_threadsが0に設定されている場合、最適化により選択されたインデックスを使用してスキャンが行われます。この問題は8.0.37で公式に修正され、プライマリキーインデックスが強制的にCOUNT(*)ステートメントを実行しなくなりました。最適化によりセカンダリインデックスが選択された場合、単一スレッドスキャンが実行されます。最適化によりプライマリキーインデックスが選択された場合、並列スキャンが実行されます。リリースノート: MySQLは、セカンダリインデックススキャンを使用するOptimizerヒントを無視しなくなり、代わりにクラスター(並列)インデックススキャンを強制していました。
3.2 並列CHECK TABLE
このセクションでは、InnoDBレイヤーでCHECK TABLEステートメントを実行する方法について説明します。CHECK TABLEステートメントがInnoDBレイヤーで実行されるとき、テーブルの各インデックスを順に走査し、以下のようなチェックを行います。
-
最初のインデックススキャンでは、B+ツリー構造の正確性を確認するために、ルート層から葉層まで階層ごとにスキャンします。
- 現在のレベルの左端のノードから右端のノードまで順に走査します。
- ページの一貫性を確認します:FLAGチェック、PAGE_MAX_TRX_IDチェック、PAGEディレクトリ、RECORDの検証。ページ内の最小レコードから最大レコードまで走査します。
- ノードポインタの方向を確認します。
- 親ノードの方向を確認します。
- 隣接するページ間のレコードの順序を確認します:ノードの最大レコードはその右のノードの最小レコードよりも小さくなるべきです。
- ...
-
2番目のインデックススキャンは、B+ツリーの最小レコードから最大レコードまで行ごとのレコードスキャンを行い、隣接するレコードのサイズを比較して要件を満たしているかどうかを確認します。この例では、最初のインデックススキャンは単一スレッドです。2番目のスキャンでは、インデックスがプライマリキーインデックスの場合、並列スキャンがサポートされます。セカンダリインデックスの場合、単一スレッドスキャンが実行されます。
並列スキャン
CHECK TABLEの並列スキャンの実装は、SELECT COUNT(*)ステートメントと同じです。違いはコールバック関数にあります。
- COUNT(*): 作業スレッドは各サブツリーをカウントし、最後にカウントを合算します。
- CHECK TABLE: 作業スレッドは各サブツリー内の葉ノードレコードの順序を比較します。サブツリー間の順序はチェックされません。これは、最初のスキャンでページ間の順序がチェックされるためです。CHECK TABLEの作業スレッドがサブツリーをスキャンするとき、プライマリキーの各レコード行がスキャンされるたびにコールバック関数が実行されます。コールバック関数のロジックは、現在の行と前の行の順序を比較することです。もしそれがシャードの左端のレコードであれば、pre_record = nullptrに設定します。pre_recordポインタがnullでない場合、current_recordとpre_recordのサイズが期待通りかどうかを比較します。そうでない場合はエラーを返し、そうでない場合は引き続きスキャンします。pre_record = current_recordに設定します。成功報告を返します。
並列効果
まず、CHECK TABLEの並列スキャンの効果を見てみましょう。4億行のレコードを持つSysbenchテーブルを使用してテストしました。テスト構成はCOUNT(*)と同じです。Sysbenchネイティブテーブルには1つのプライマリキーインデックスと1つのセカンダリインデックスがあります。CHECK TABLEステートメントを実行するとき、各インデックスは2回スキャンされます。
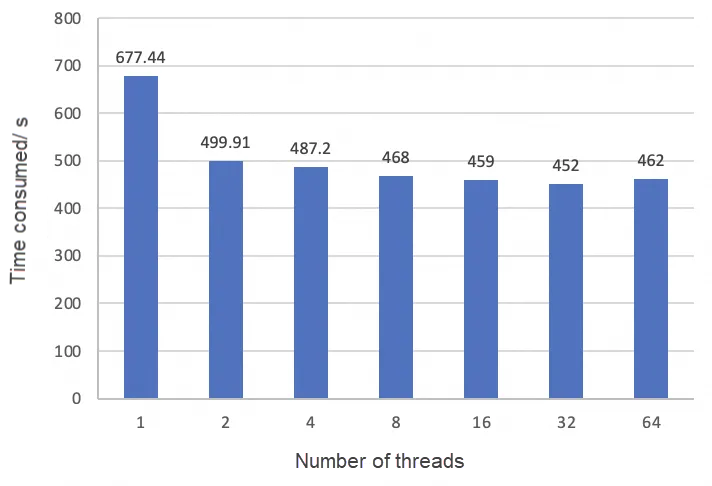
- スレッド数が1から2に増えると、消費時間が大幅に減少します。しかし、ここでの利益は並列スキャンによるものではありません。理由は、COUNT(*)のスレッド数が1から2に変わったときと同じで、元の単一スレッドスキャンの効率が悪かったからです。
- スレッド数が2を超えて増えると、効果は改善しますが、顕著ではありません。これは、CHECK TABLEの大部分の時間を消費するのは最初のスキャンであることを示しています。
最適化可能な点
CHECK TABLEの並列プロセスを見た後、いくつか最適化できる点が見つかります。
- インデックスレベル
平行スキャンと並列処理の詳細
| | | |-> Parallel_reader.add_scan(bulk_inserter) // 各行をスキャンするためのコールバック関数
| | | |-> Parallel_reader.run // 並列スキャン
| | |-> load // マルチスレッドによるソートとビルド
| | | |-> mt_execute
| | | | |-> Loader::Task::operator()
| | | | | |-> Builder::merge_sort // ソート,Builder::State::SORT
| | | | | |
| | | | | |-> Builder::btree_build // ビルド,Builder::State::BTREE_BUILD
平行スキャン
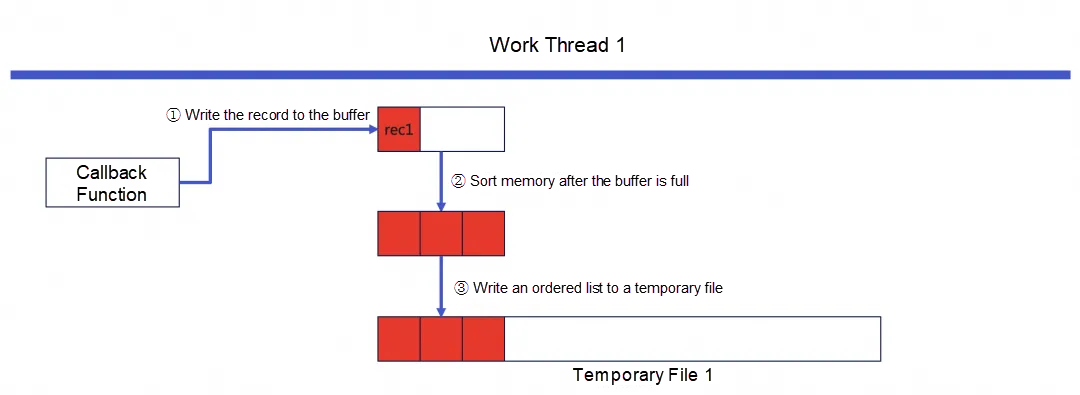
平行スキャン中、各ワーカースレッドは一時ファイルとソートバッファを作成します。ワーカースレッドがプライマリキーの各行をスキャンするたびに、コールバック関数が呼び出されます。このコールバック関数は以下の役割を果たします:
- プライマリキーレコードに基づいてセカンダリインデックスの行レコードを作成し、その行レコードをスレッドレベルのバッファに書き込みます。
- バッファが満杯でない場合、そのまま戻ります。バッファが満杯になると、マージソートアルゴリズムを使用してバッファ内のレコードをソートします。
- ソート後、順序付きリストが得られ、これを一時ファイルに書き込みます。その後、バッファをクリアします。
以下の図は最初の順序付きリストを一時ファイルに書き込むプロセスを示しています。順序付きリストのサイズはバッファサイズです。
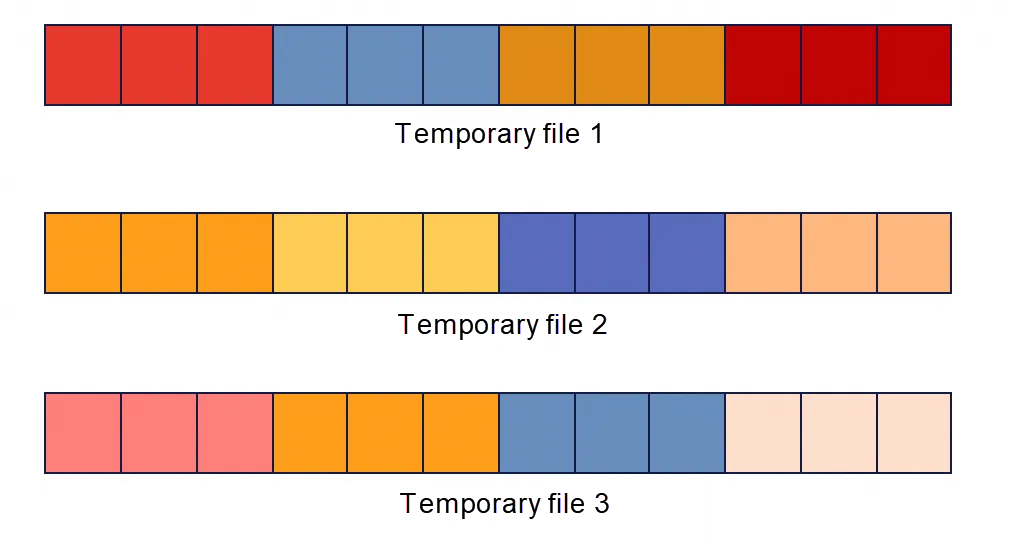
ワーカースレッド1がシャードをスキャンした後、一時ファイル1には複数の順序付きリストがあります。

ワーカースレッドは継続的にキューからシャードを取り出し、スキャンを行います。スキャン中に順序付きリストが対応する一時ファイルに書き込まれます。innodb_parallel_read_threadsが3の場合、3つの並列スキャンスレッドと3つの一時ファイルがあります。すべてのシャードが並列でスキャンされた後、3つの部分的に順序付けられたファイルが得られます。それぞれが複数の順序付きリストで構成されています。
要約
以下は平行スキャンの要約です。平行スキャンのワーカースレッドは、プライマリキーレコードの各行をスキャンするたびにコールバック関数を実行します。対応するコールバック関数は異なる上位のSQLステートメントに対応して設計され、対応する並列タスクを完了します。COUNT(*)全テーブル、CHECK TABLE、およびセカンダリインデックス作成の平行スキャンの実行プロセスは同じです。平行スキャンスレッドはinnodb_parallel_read_threadsパラメータによって制御されます。3つの主な違いはコールバック関数にあります。以下にまとめています。
| SQLステートメント | コールバック関数 |
|---|---|
COUNT(*) 全テーブル |
カウントを1増加させる |
CHECK TABLE |
現在のレコードと前のレコードのシーケンスをチェックする |
| セカンダリインデックス作成 | レコードをソートファイルに書き込み、少量のソートを行う |
理論的には、B+ツリーをスキャンする必要がある任意のプロセス(sumやavgなどの集約関数、WHEREステートメント、範囲クエリ(開始と終了)、analyze tableなど)は、この一連の並列インターフェースを使用してツリーを複数のサブツリーに分割し、並列スキャンすることができます。
並列ソート
DDLのソートとビルドは、ワーカースレッドによってタスクとして実行されます。ワーカースレッドはタスクキューからタスクを取り出し、タスクの状態に基づいてソートまたはビルドを決定します。
DDL_parallel_work
|-> Loader::Task::operator() // タスクを実行
| |-> Builder::merge_sort // ソート,Builder::State::SORT
| |
| |-> Builder::btree_build // ビルド,Builder::State::BTREE_BUILD
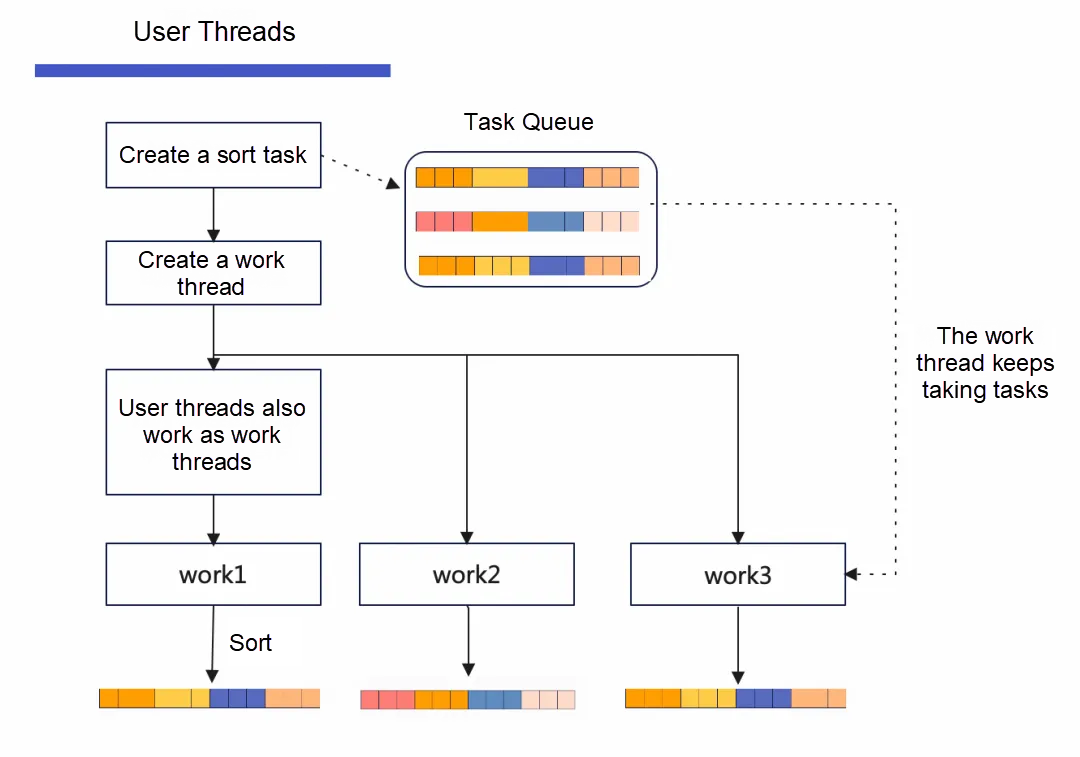
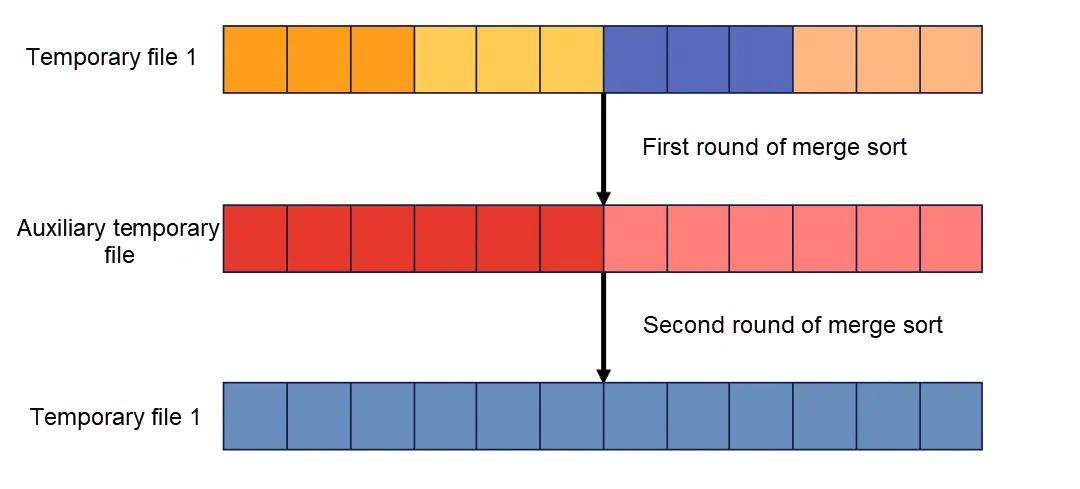
平行スキャンが完了すると、3つの部分的に順序付けられた一時ファイルが得られ、これら3つのファイルの集合がセカンダリインデックスの全レコードを構成します。ユーザースレッドは3つのソートタスクを作成し(実際にはワーカースレッドによっても作成される可能性がありますが、ここでは簡略化しています)、タスクの状態をBuilder::State::SORTに設定します。並列の粒度は一時ファイルレベルであり、各一時ファイルには1つのソートタスクが対応します。ユーザースレッドがワーカースレッドを作成すると、キューからタスクを取り出して実行します。ワーカースレッドは継続的にキューからタスクを取り出して実行します。これは、平行スキャンとは異なり、ユーザースレッドがワーカースレッドとして使用されません。並列ソートタスクの数は一時ファイルの数によって決まり、一時ファイルの数は並列スキャンスレッドの数によって決まります。前述の例では、innodb_parallel_read_threadsが3であると仮定しました。ここでinnodb_ddl_threadsを6に設定しても、タスクは3つしかなく、実際に実行されるDDLソートスレッドの数も3つです。innodb_ddl_threadsを2に設定すると、1つのDDLスレッドが2つの一時ファイルを処理します。したがって、innodb_parallel_read_threadsとinnodb_ddl_threadsを同じ値に設定することをお勧めします。DDLスレッドファイルのソートプロセスはマージソートアルゴリズムを使用し、新しい一時ファイルを作成してソートを補助します。一時ファイル1が4つの順序付きリストを含む場合、最初のラウンドのマージソート後に2つの順序付きリストを含むファイルが得られ、2回目のマージソート後にはグローバルに順序付けられた一時ファイルが得られます。
すべての並列ソートタスクが完了すると、3つの順序付き一時ファイルが得られます。これらの3つのファイルはさらに1つのファイルにマージおよびソートされません。
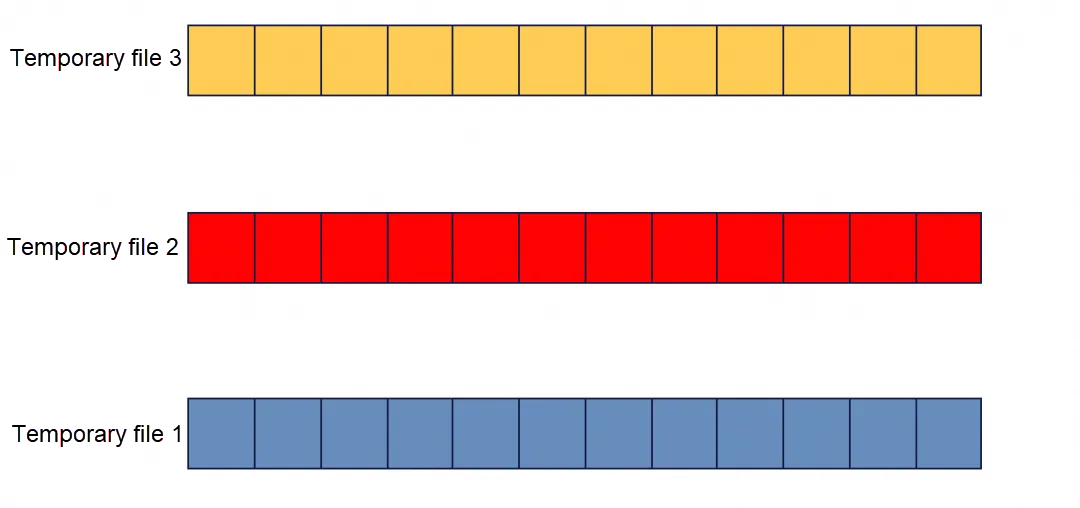
単一スレッドでのビルド
すべてのDDLワーカースレッドが並列ソートを完了すると、3つの順序付き一時ファイルが得られます。これらの3つのファイルは1つの順序付きファイルにマージおよびソートされません。3つの一時ファイルは優先キューとして構築され、ビルドタスクが追加され、タスクの状態が`Builder::State::BT
InnoDB DDLの並列処理に関する分析
innodb_ddl_threadsを増加させた後、DDLの並列スレッドが機能しないことが確認されました。その理由は後述します。
| innodb_parallel_read_threads | innodb_ddl_threads | 消費時間 (秒) | 前回との差 |
|---|---|---|---|
| 16 | 1 | 182 | NULL |
| 16 | 2 | 137.7 | 44.3 |
| 16 | 4 | 117.5 | 20.2 |
| 16 | 8 | 109.1 | 8.4 |
| 16 | 16 | 105.5 | 3.6 |
| 16 | 32 | 108.3 | -2.8 |
上記の表では、第1段階の並列スキャン時間を最小限に抑えるためにinnodb_parallel_read_threadsを16に設定しています。これにより、第2段階への干渉を減らすことができます。innodb_ddl_buffer_sizeは32MBで、各並列スレッドに割り当てられるバッファサイズは32MB/16=2MBです。このバッファはメモリソートに使用されるため、比較的小さなバッファサイズを設定することで、メモリソートの量を減らし、ファイルソートタスクにかかる時間を増やすことができます。これにより、並列ソートのパフォーマンス改善が観察しやすくなります(これは、オンラインでの大規模テーブルシナリオをシミュレートすることができ、セカンダリインデックスを作成する際に広範なファイルソートが必要になる場合があります)。その後、innodb_ddl_threadsを徐々に増やしていきます。
- 各実験間の時間差は、
innodb_ddl_threadsが増加するにつれて基本的に線形的に減少します。これは、第2段階の並列ソートが期待通りに機能していることを示しています。
4.2 並列テーブル再構築
以下では、InnoDBのREBUILD TABLEステートメントの実行プロセスについて説明します。これは以下の3つの段階に分けられます:
-
スキャン: プライマリキーB+ツリーの最初のレコードから最後のレコードまで順にトラバースし、空のレコードをスキップします。各行のスキャン後に以下の操作を行います:
- プライマリキーレコードを新しいプライマリキーインデックスB+ツリーに順序どおりに直接書き込みます(プライマリキーは既に順序付けられているため、再度ソートする必要はありません)。
- 再構築するセカンダリインデックスについては、セカンダリインデックス行レコードを作成し、ソートバッファに書き込み、バッファがいっぱいになったら一時ファイルに書き込みます。
-
ソート: セカンダリインデックスの一時ファイルをソートします。
-
ビルド: ソートされたセカンダリインデックスデータをセカンダリインデックストリーに挿入します。
CREATE INDEXステートメントと比較すると、プライマリキーB+ツリーの構築という追加操作があり、複数のセカンダリインデックスが作成される可能性があります。もし1つのセカンダリインデックスのみを再構築する場合、ステップ1.b, 2, 3はCREATE INDEX操作となります。
テーブルの再構築では、各段階が並列操作をサポートするか否か、並列操作の粒度は、並列でセカンダリインデックスを作成する場合とはかなり異なります。テーブルの再構築の主な目的の1つは、プライマリキーインデックストリーを再構築し、穴を再利用し、テーブルスペースを縮小することです。プライマリキーB+ツリー自体は順序付けられているため、並列でソートする必要はありません。単にプライマリキーインデックスを昇順に逐次スキャンし、プライマリキー行レコードを新しいB+ツリーに挿入することで、コンパクトなプライマリキーB+ツリーを得ることができます。プライマリキーインデックスの再構築プロセスを並列化することは不要のように思われます。MySQL自体も同様であり、テーブルの再構築時にはプライマリキーインデックスを並列でスキャンすることはできません。innodb_parallel_read_threadsパラメータはテーブルの再構築には効果がありません。この副作用として、単一のセカンダリインデックスを再構築する場合、スキャン段階で複数の一時ファイルを並列で書き込むことはできません。また、ソート段階で単一のインデックスに対して並列ソートを行うこともできません。しかし、セカンダリインデックスのソートとビルド段階は依然として並列操作をサポートしていますが、粒度はインデックスレベルになります。例えば、4つのセカンダリインデックスを再構築する場合、4つのインデックスのソートとビルドをDDL並列スレッドによって並列で処理することができます。
単一スレッドでのスキャン
プライマリキーB+ツリーの再構築のスキャンプロセスは、ユーザースレッドによって単一スレッドで行われます。元のテーブルに1つのプライマリキーインデックスと3つのセカンダリインデックスがあると仮定すると、スキャンプロセスは各セカンダリインデックスに対応する一時ソートファイルを作成し、合計3つの一時ファイルが生成されます。プライマリキー行レコードを1行ずつスキャンするたびに以下の操作を行います:
- 新しいプライマリキーB+ツリーにプライマリキー行レコードを挿入します。
- プライマリキー行レコードに基づいて3つの対応するセカンダリインデックス行レコードを作成し、それぞれ3つの一時ファイルに書き込みます。
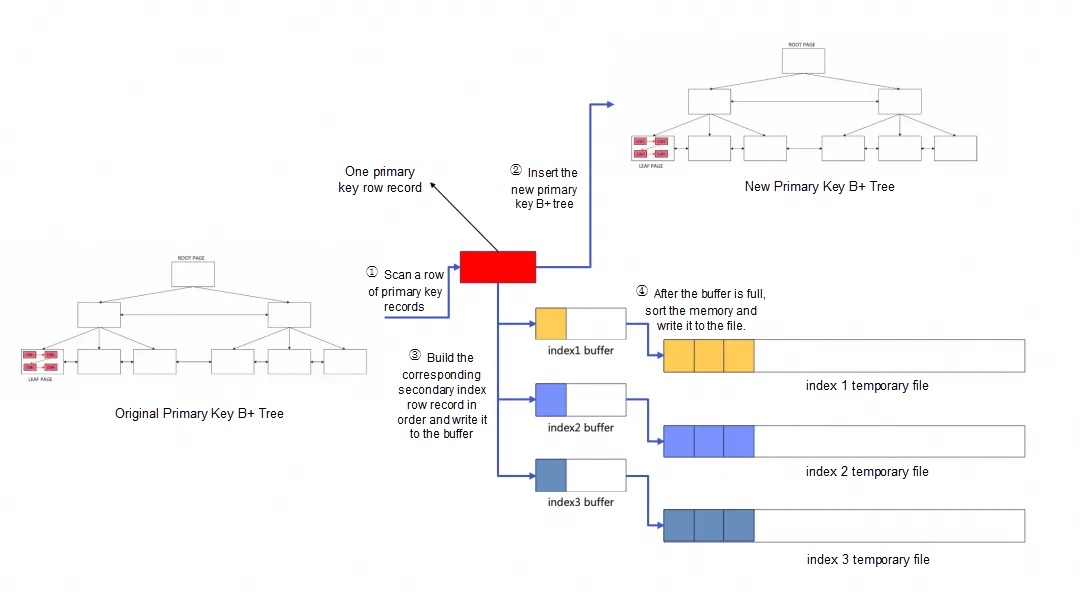
単一スレッドでのスキャンが完了すると、新しいコンパクトなプライマリキーB+ツリーと3つの部分的に順序付けられた一時ファイルが得られます。各一時ファイルは1組のセカンダリインデックスレコードに対応します。
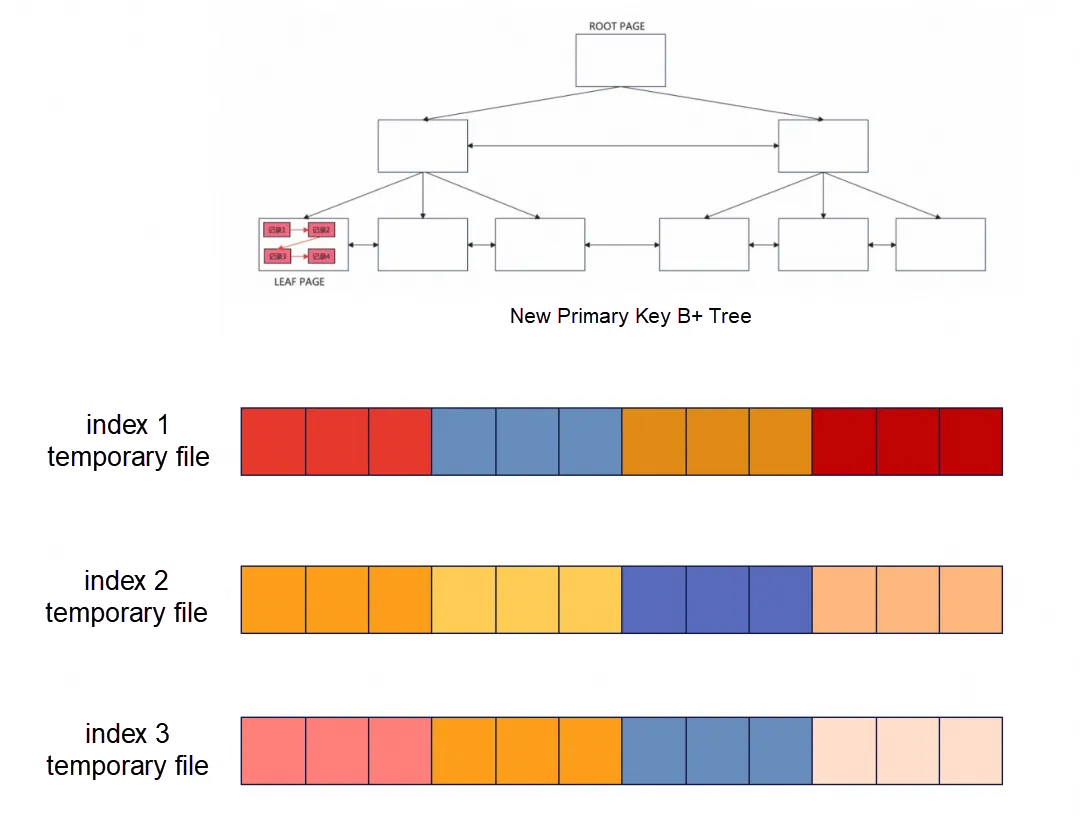
並列ソート
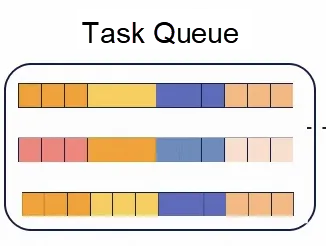
REBUILD TABLEの並列ソートは、CREATE INDEXの実装とほぼ同じですが、並列粒度が異なります。前述のように、セカンダリインデックスを作成する際、多スレッドソートの並列タスク数はinnodb_parallel_read_threadsによって決定され、単一のインデックスに対して対応する数の一時ファイルが作成され、インデックス内で並列にソートされます。テーブルの再構築で単一スレッドのスキャンを使用する場合、innodb_parallel_read_threadsは1です。したがって、単一のセカンダリインデックスに対して1つの一時ファイルしか存在しません。この並列ソートアーキテクチャでは、セカンダリインデックス内での並列ソートは行われません。ただし、複数のセカンダリインデックスは並列操作をサポートします。つまり、並列操作の粒度はインデックスレベルです。ここでの3つのインデックスの一時ファイルは、3つのソートタスクとしてタスクキューに追加されます。ワーカースレッドはタスクを取り出し、一時ファイルをソートします。タスクキューは以下のようになっています:各タスクは1つのインデックスと部分的に順序付けられた一時ファイルに対応します。
innodb_ddl_threads
Sysbenchテーブルに二次インデックスを追加する
元のSysbenchテーブルに基づいて、pad列とc列に2つの二次インデックスを追加します:sql
CREATE INDEX idx1 ON sbtest1 (pad);
CREATE INDEX idx2 ON sbtest1 (c);
テストSQLステートメントはREBUILD TABLEステートメントです:sql
ALTER TABLE sbtest1 ENGINE = INNODB;
innodb_parallel_read_threads と innodb_ddl_threads のパフォーマンス比較
innodb_parallel_read_threads |
innodb_ddl_threads |
消費時間 (秒) |
|---|---|---|
| Sysbench ネイティブテーブル: 1つのプライマリキーインデックスと1つの二次インデックスを含む | ||
| 1 | 3 | 186.6 |
| 2 | 3 | 185.8 |
| 4 | 3 | 187.3 |
| Sysbench テーブル(2つの追加インデックス付き): 1つのプライマリキーインデックスと3つの二次インデックスを含む | ||
| 1 | 1 | 849.5 |
| 1 | 2 | 602.3 |
| 1 | 3 | 534.9 |
| 1 | 4 | 533.3 |
-
innodb_parallel_read_threadsパラメータは、テーブル再構築時にパフォーマンス改善には寄与しません。 -
innodb_ddl_threadsパラメータは、複数の二次インデックスを含むREBUILD TABLEステートメントで並列処理を有効にすることでパフォーマンスを向上させます。二次インデックスが多ければ多いほど、並列度も高くなります。
5. まとめ
この記事では、InnoDBレイヤーでMySQLが提供する並列加速技術の基本的な使用方法、効果、原理、制限について説明しました。一部のクエリとDDLステートメントは、並列スキャン、並列ソート、B+ツリーの並列構築をサポートしています。これらの技術は全てAliSQLで利用可能です。自由にご利用ください。現在、MySQLがサポートする並列ステートメントの数は限られていますが、将来的にはコミュニティにより多くのサポートされる並列ステートメントが導入されることが期待されます。AliSQLチームも並列クエリとDDLの機能を追加し、将来は二次インデックスの並列スキャンをサポートする予定です。以下にいくつかの実践的な提案を示します。
- インスタンスの仕様と負荷に基づいて、適切な
innodb_parallel_read_threads、innodb_ddl_threads、innodb_ddl_buffer_sizeパラメータを設定することをお勧めします。 - 並列スキャンは
COUNT(*)フルテーブルステートメントの効果を大幅に向上させるため、テーブルサイズに基づいて適切なinnodb_parallel_read_threadsパラメータを設定することができます。 - 並列スキャンは
CHECK TABLEステートメントの性能向上にはほとんど影響がないため、CHECK TABLE実行時にはinnodb_parallel_read_threadsの値を2に設定することをお勧めします。 - 二次インデックスを作成するステートメントでは、並列スキャンと並列ソートがパフォーマンスを大幅に向上させます。テーブルサイズに基づいて
innodb_parallel_read_threadsとinnodb_ddl_threadsを同じ値に設定することをお勧めします。innodb_parallel_read_threadsを増やす際には、同時にinnodb_ddl_buffer_sizeも増やすことをお勧めします。 -
REBUILD TABLEステートメントでは、並列操作がパフォーマンスを大幅に向上させます。インデックスを並列粒度としてファイルをソートして再構築することができます。元のテーブルインデックスの数に基づいてinnodb_ddl_threadsの値を設定できます。innodb_parallel_read_threadsパラメータを設定する必要はありませんが、メモリ使用量に基づいてinnodb_ddl_buffer_sizeパラメータを設定することができます。
参考文献
[01] https://github.com/mysql/mysql-server
[02] http://mysql.taobao.org/monthly/2020/11/03/
[03] http://mysql.taobao.org/monthly/2019/03/05/
[04] http://mysql.taobao.org/monthly/2021/03/03/
[05] http://mysql.taobao.org/monthly/2019/12/05/
[06] https://dev.mysql.com/doc/refman/8.4/en/online-ddl-parallel-thread-configuration.html
[07] https://dev.mysql.com/blog-archive/mysql80-innodb-parallel-threads-ddl/
[08] http://mysql.taobao.org/monthly/2019/12/05/