pandasで時系列データなどの分析を行なう際、日毎や分毎などで累積和を算出したいケースがあると思います。
例えば、以下のような1ヵ月分のティックデータを1Tでresamplingしたohlcvに変換したいとします。
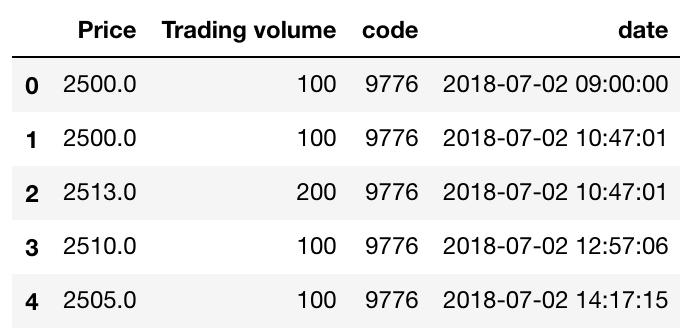
そこで、以下のような処理でcode毎のohlcvを作成します。
def gen_ohlcv_df(code):
df_ohlcv_code = df[df['code'] == code]
df_ohlcv_code = df_ohlcv_code.set_index('date')
df_ohlcv_code = pd.concat([df_ohlcv_code['Price'].resample('T').ohlc(),
df_ohlcv_code['Trading volume'].resample('T').sum()], axis=1)
return df_ohlcv_code
当然当該時刻にデータがない場合は欠損値になります。

ここで欠損値は直前の値で補間したいと思います。
def gen_ohlcv_df(code):
df_ohlcv_code = df[df['code'] == code]
df_ohlcv_code = df_ohlcv_code.set_index('date')
df_ohlcv_code = pd.concat([df_ohlcv_code['Price'].resample('T').ohlc(),
df_ohlcv_code['Trading volume'].resample('T').sum()], axis=1)
df_ohlcv_code = df_ohlcv_code.reset_index()
# 欠損値を直前のデータで補間する
df_ohlcv_code = df_ohlcv_code.interpolate(method='zero')
return df_ohlcv_code
ohlcは良い感じになりました。
ここで、volumeは日毎の累積和で表示したいとします。
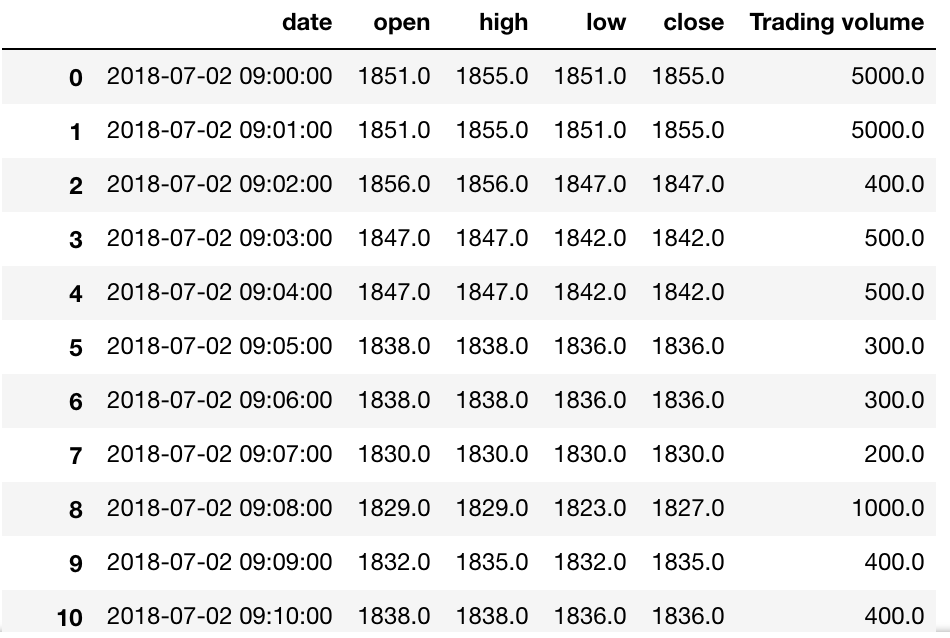
ところが、単純にcumsum()を当てると以下のように、volumeが全期間の累積和となってしまいます。
def gen_ohlcv_df(code):
df_ohlcv_code = df[df['code'] == code]
df_ohlcv_code = df_ohlcv_code.set_index('date')
df_ohlcv_code = pd.concat([df_ohlcv_code['Price'].resample('T').ohlc(),
df_ohlcv_code['Trading volume'].resample('T').sum()], axis=1)
df_ohlcv_code = df_ohlcv_code.reset_index()
# Trading volumeの累積和をとる
df_ohlcv_code['Trading volume'] = df_ohlcv_code['Trading volume'].cumsum()
# 欠損値を直前のデータで補間する
df_ohlcv_code = df_ohlcv_code.interpolate(method='zero')
return df_ohlcv_code
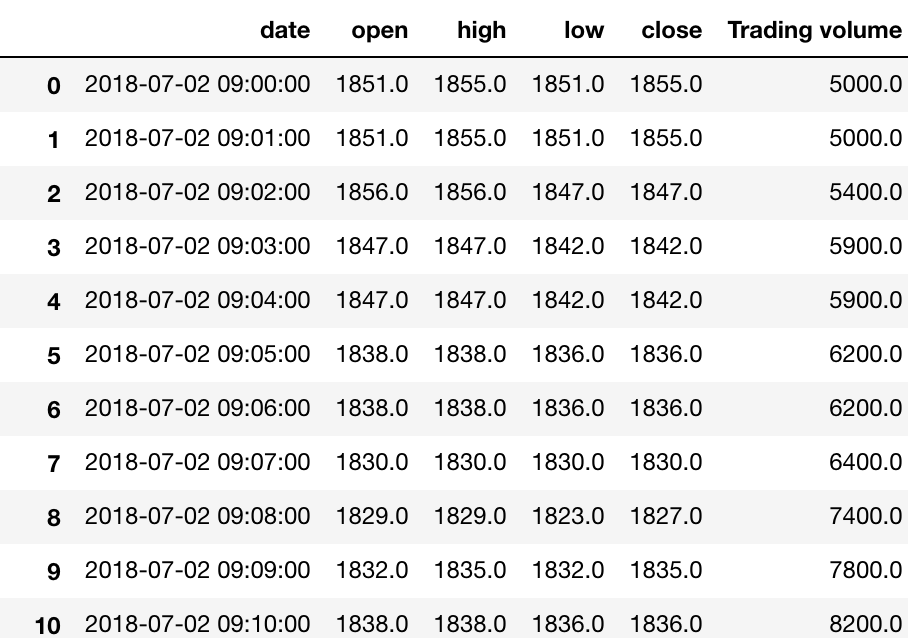

volumeは日毎にリセットして累積和を算出したいので、datetimeから暫定的に日付データのみのカラムを作成してgroupbyしてやることで解決します。
def gen_ohlcv_df(code):
df_ohlcv_code = df[df['code'] == code]
df_ohlcv_code = df_ohlcv_code.set_index('date')
df_ohlcv_code = pd.concat([df_ohlcv_code['Price'].resample('T').ohlc(),
df_ohlcv_code['Trading volume'].resample('T').sum()], axis=1)
df_ohlcv_code = df_ohlcv_code.reset_index()
# groupbyのためのdayカラムを一時的に追加
df_ohlcv_code['day'] = df_ohlcv_code['date'].map(lambda x: x.day)
# 日単位でTrading volumeの累積和をとる
df_ohlcv_code['Trading volume'] = df_ohlcv_code.groupby(['day'])['Trading volume'].cumsum()
# dayカラムを削除
df_ohlcv_code = df_ohlcv_code.drop('day', axis=1)
# 欠損値を直前のデータで補間する
df_ohlcv_code = df_ohlcv_code.interpolate(method='zero')
return df_ohlcv_code
累積和を日毎に算出することができました。
groupbyするデータを分や秒、週にする場合などは x.day の部分を x.minute などに適宜変更することで対応できます。