
TL; DR
- 強化学習コンペなのにルールベースのほうが強かった
- 強化学習コンペなのに、コンピュータが全然強化学習してくれない
優勝者のポエムが読みにくいしうざい
はじめに
みなさまはKaggleを知っていますでしょうか。
世の中にはKaggleというAIのコンペティションを開いているサイトがあります。
Kaggleでは画像認識のコンペティションなどが定期的に行われていますが、最近、これの変わり種として、とあるゲームのAIを作るコンペティションが開かれました。ゲームAIは近年目覚ましい成長を遂げています。例えば、囲碁の世界では人間に勝つまでになりました。そのゲームAIの中核となる技術が強化学習です。強化学習とはエージェントと呼ばれる存在が試行錯誤しながら行動を自律的に学んでいく技術になります。当然、このゲームAIのコンペティションでも強化学習を使うことが期待されていたのでしょう。チュートリアルも紹介されていました。
しかし、世の中はあまくなかったのです。強化学習の闇に我々が触れることになろうとは誰もコンペティションが終わるまで気づかなかったのです。
なお、本記事は強化学習苦手の会アドベントカレンダー7日目の記事になります。
とあるゲームAIのコンペティションのルール説明
このコンペティションでは各競技者が作成した4つのゲームAIが限られた時間と空間の中でhaliteなる資源を獲得する競争を行います。最終的にたくさんのhaliteを手に入れたゲームAIが勝利することになります。
さて、このゲームのルールを下図を使ってかんたんにわかりやすく説明します。
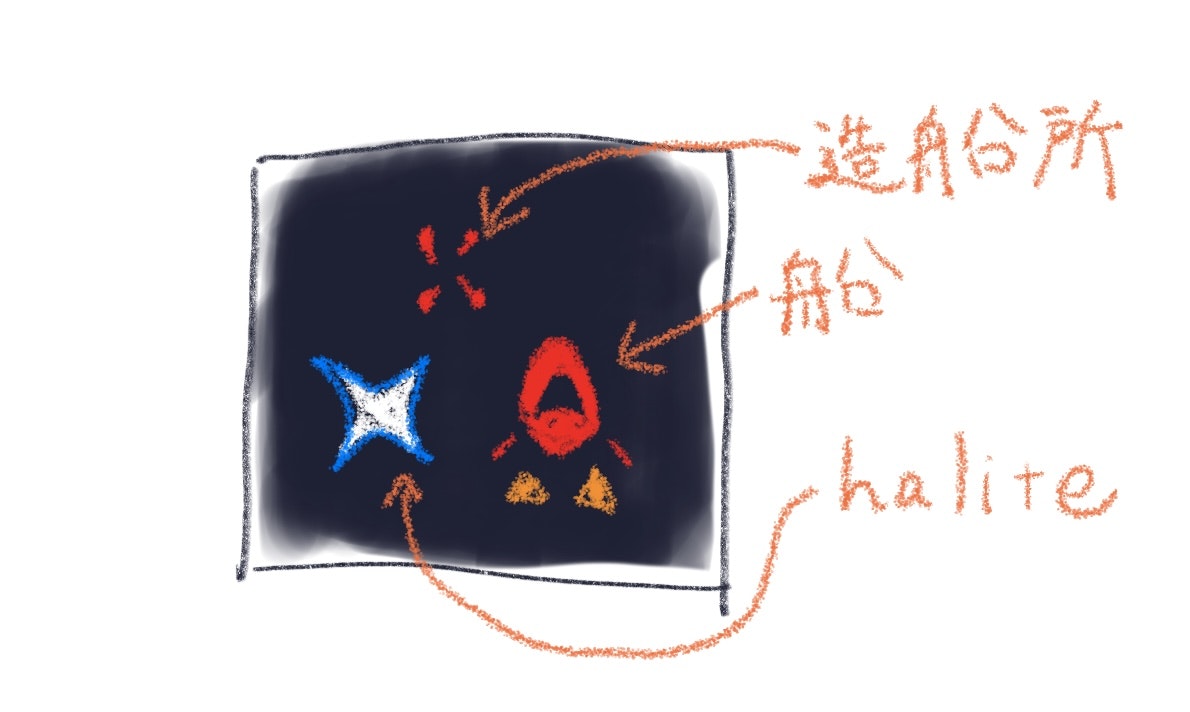
図 ゲームの様子と解説(著作権的になんとなく絵でかきました。)
基本的にゲームAIは宇宙船と造船所、haliteを所有することができます。haliteを獲得するには宇宙に落ちているhaliteのあるところまで宇宙船をゲームAIが行かせてhaliteを回収する必要があります。ただし、この時点ではhaliteは船の中に入ったままで、まだゲームAIの手元には入りません。このhaliteを積載した船をゲームAIが造船所まで移動させて無事到着させると、ゲームAIの手元に入ります。ここから、このゲームの最もシンプルな基本戦術としては宇宙船をhaliteがたくさんあるところへ行かせてhaliteを回収し、造船所に持ち帰ってくることになります。また、このゲームAIが持つhaliteを消費して、造船所で船を作ることができます。よって、沢山の船をつくってhaliteをたくさん集めて造船所にうまいこと持ち帰ってくるのが勝利の鍵と言えます。イメージがつきにくい方は実際のプレイ動画をkaggle上で見れますので見てみてください。なお、強化学習ライブラリは使用禁止、ゲーム環境はオープンソースであるなど他にも細かいルールに関しては本題からそれそうなので割愛します。
自分がやったことの概要
私はまずさっきの基本戦術である「船が行って帰ってくる」をゲームAIを強化学習無しの、いわゆるルールベースでつくりました。ルールベースとはその名の通りいちいち行動パターンをルールとしてプログラミングしていくアプローチのことです。その結果、そこそこなゲームAIができました。しかし、やはりそこらへんの人間が適当に考えて作った程度のゲームAIなので、コンペティションの上位層に勝てませんでした。
そこで、人間よりも賢いと思われるAIさんの出番が出てきました。AIさんには1隻の船で「船が行って帰ってくる」戦法を囲碁のAIで使われていたDQNという手法で強化学習してもらうことにしました。それはもう何日もかけました。ゲームの盤面を画像化してうまいこと学習できるようにしたり、最初に作ったゲームAIを模倣学習させたりといろいろしました。
結果として、そもそもまともに動いてくれませんでした。「船が行って帰ってくる」ことすらありませんでした。
この事態に直面した私はKaggle上にあるプレイヤー同士での相談場所Discussionをみました。すると、

「船が行って帰ってくる」ことがないという同じ悩みを抱いている競技者が発生していました。でも、「船が行って帰ってくる」ことはできたよという回答を見て、なんとかなるかもしれないという希望はいだきました。そこで、ゲーム環境がオープンソースであることから、手元のマシンでゲーム環境を再現し、競技には使えない強化学習ライブラリPFRLを使って、無理やり学習できるか挑戦してみました。
結果として、「船が行って帰ってくる」ことが無事にできるようになりました。とても感動しました。自分でプログラミングしたらたかだか数時間でできるようになることが、強化学習で学ばせるとこんなにうまくいかないのかと感動しました。
しかし、船を2隻にした瞬間にうまくいかなくなりました。個人プレイが目立ち、協調プレイしてくれなかったんですよね。
やんぬるかな・・・
最終的には他の人の解法をベースに改造したものを提出することにしました。
結果は1139チーム中ギリギリメダルに届かない114位という悲しい結果になりました。
うーむ。
上位層のゲームAI
さて、上位層はどんなゲームAIを作ったのでしょうか。優勝者であるトムさんのゲームAIをDiscussionから見てみましょう。その前に、トムさんはどんな人かというと、囲碁のAIを作ったことで有名なDeepMindというGoogle傘下の組織に所属していた人です。
で、本題に戻すと、彼は、今回のコンペを「私の旅」と題して語っています。その旅は大雑把に3つにわかれており、一つは深層強化学習、次はスコア-行動エージェント、最後にスコアー計画ー行動エージェントとなっています。が、この時点で嫌な予感がします。なぜならば、深層強化学習が章として区切られているためです。では深層強化学習の章を見ていきましょう。
トムさんは他のゲームと同様に深層強化学習を頑張ってみたそうです。その結果について述べていたので、翻訳サービスDeepLで直訳させてみました。次のとおりです。
しかし、立ち止まっているだけでは何もできない船に1ヶ月もかけてみた結果、心の痛みを抱えながら進むことにしました。
強化学習がまともにできてないうえに諦めとる!!!
このあとの章ではどのように戦うかについて細かく書かれていました。ちゃんと読み切れてはいませんが、おそらくルールベースなのだと思われます。
気を取り直して、次に2位の人のゲームAIを見てみましょう。2位の人はバンダイナムコ研究所の會田さんだそうです。日本人として誇らしいですね。さて、読んでみましょう。
まず、NOTEとして注意書きがされています。今回は私が訳してみましょう。
私のチーム名「Raine Force」は強化学習を使っているように見えますが、私のゲームAIは100%ルールベースです。
強化学習どころか最初からルールベースじゃん!!!
やんぬるかな・・・
まとめ
今回はKaggleで初めて行われた強化学習コンペに参加してみました。結論から言うと強化学習のコンペじゃないやん、ルールベースのコンペじゃんとなりました。実世界では往々にして強化学習を使うよりもルールベースで書いたほうが早いことはよく知られていますが、まさか人工的に作られた環境であるコンペでも同じことが起きるとは思っても見ませんでした。
みなさんも強化学習という枠にとらわれない柔軟な発想で、世の中の問題をといていきましょうね!
運営の嘘つき!
追記:
打ち消し線で書かれている文章は半分ネタみたいなものでインターネット老人会特有のノリなので、あまり本気にしないでください。そこまで本気で思っているわけではないです。不快に思われた方はすいませんでした。