またこれか
こんにちは。@albno273 です。前回の続きです。
考察の項で「形態素解析」を挙げていたので、
ネガポジ判定を行うGem作ってみた / Qiita
を参考に機能を追加してみました。
追加機能
- kuromoji を用いた形態素解析
-
PN Table と JSPD を用いたスコアリング
- 辞書によってスコアがばらつくのでせっかくなら両方使ってしまえ!という…
- 「にゃーん」の代わりに流行りに乗っかってみる

コード
/* 形態素解析 -> ネガポジ判定 -> 社会性フィルター */
var twitter = require('twitter'),
confu = require('confu'),
Mecab = require('./node-mecab-lite/lib/mecab-lite.js'), // Test
kuromoji = require('kuromoji'),
readline = require('readline'),
fs = require('fs'),
async = require('async');
/**
* CK/CS 読み込み
* config/key.json に記述するかここに直接記述
*/
var conf = confu('.', 'config', 'key.json'),
client = new twitter({
consumer_key: conf.test.cons_key,
consumer_secret: conf.test.cons_sec,
access_token_key: conf.test.acc_token,
access_token_secret: conf.test.acc_token_sec
});
// 形態素解析辞書のディレクトリ指定
var builder = kuromoji.builder({ dicPath: 'node_modules/kuromoji/dict' });
var mecab = new Mecab(); // Test
// にゃーんカウンタ
var count = 1;
/**
* 'follow: ---' には自分のユーザIDを入力
*/
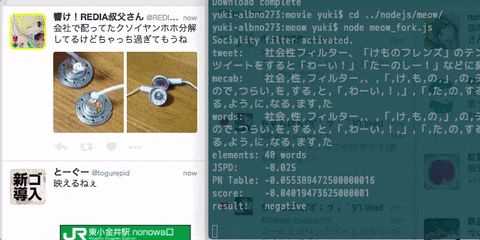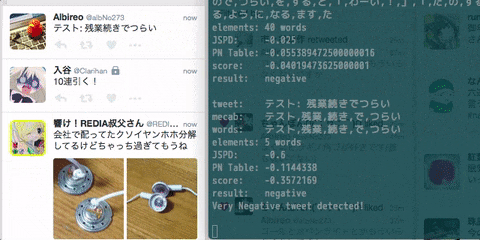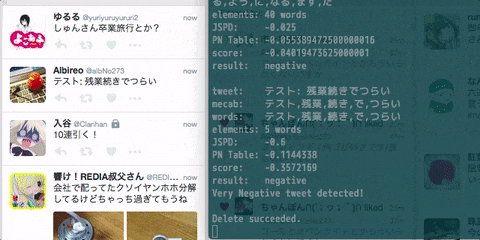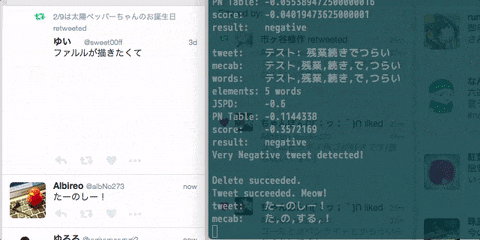
console.log('Sociality filter activated.');
// client.stream('user', function (stream) {
client.stream('statuses/filter', { follow: 3021775021 }, function (stream) {
stream.on('data', function (tweet) {
var text = tweet.text,
id = tweet.id_str,
isRT = tweet.retweeted_status,
isReply = tweet.in_reply_to_user_id;
// リプライとRTを除外
if (isRT == null && isReply == null) {
console.log('tweet: ' + text);
// 同期処理
async.waterfall([
morphologicalAnalysis,
scoreingTweet,
socialityFilter
], function (err) {
if (err) throw err;
else console.log('');
});
}
/**
* 形態素解析して名詞と用言の基本形を抽出
*/
function morphologicalAnalysis(callback) {
stringSplitter(text, function (err, words_arr) {
if (!err) {
console.log('words: ' + words_arr);
console.log('elements: ' + words_arr.length + ' words');
callback(null, words_arr);
}
});
}
/**
* 日本語極性辞書を参照して各単語をスコアリング
* 現在の評価モデル: 全単語の平均スコア
*/
function scoreingTweet(words_arr, callback) {
if (words_arr.length == 0)
callback(null, 0);
else {
stringScore(words_arr, function (err, jspd, pnt) {
if (!err) {
console.log('JSPD: ' + jspd / words_arr.length);
console.log('PN Table: ' + pnt / words_arr.length);
var score = ((jspd + pnt) / 2) / words_arr.length;
callback(null, score);
}
});
}
}
/**
* 社会性フィルタ
* 引っかかった時に該当ツイートを消して「にゃーん」ツイート
*/
function socialityFilter(score, callback) {
console.log('score: ' + score);
if (score < 0) console.log('result: negative');
else if (score > 0) console.log('result: positive');
else console.log('result: neutral');
if (score < -0.3) {
console.log('Very Negative tweet detected!')
tweetMeow(id);
}
callback(null);
}
});
stream.on('error', function (err) {
console.log(err);
});
});
/**
* 入力した文章を品詞分解して抽出
* @param text 入力文字列
*/
function stringSplitter(text, callback) {
var words_arr = [];
// ここから Test
var mecab_arr = [];
mecab.parse(text, function (err, items) {
if (!err) {
var filtered = items.forEach(function (value, index, array) {
if (value[7] != '*' && value[7] != undefined)
mecab_arr.push(value[7]);
});
console.log('mecab: ' + mecab_arr);
}
});
// ここまで Test
builder.build(function (err, tokenizer) {
if (!err) {
var tokens = tokenizer.tokenize(text)
// console.log(tokens);
var filtered_tokens = tokens.forEach(function (value, index, array) {
if (value.basic_form != '*') words_arr.push(value.basic_form);
});
callback(null, words_arr);
}
});
}
/**
* 各単語のスコアを合算
* @param words_arr 単語の入った array
*/
function stringScore(words_arr, callback) {
var score_ip_jspd = 0,
score_ip_pnt = 0;
async.parallel([
function (callback) {
words_arr.forEach(function (value, index, array) {
getVerbScoreFromDic(value, 'jspd', function (err, point) {
if (!err) score_ip_pnt += point;
if (index == words_arr.length - 1) callback(null, score_ip_pnt);
});
});
},
function (callback) {
words_arr.forEach(function (value, index, array) {
getVerbScoreFromDic(value, 'pnt', function (err, point) {
if (!err) score_ip_jspd += point;
if (index == words_arr.length - 1) callback(null, score_ip_jspd);
});
});
}
], function (err, scores) {
if (err) throw err;
else callback(null, scores[0], scores[1]);
});
}
/**
* 単語のスコアを辞書から参照
* @param word 単語
* @param dic 辞書 (jspd or pnt)
*/
function getVerbScoreFromDic(word, dic, callback) {
if (dic == 'jspd') var rs = fs.ReadStream('dic/parse_dic');
else if (dic == 'pnt') var rs = fs.ReadStream('dic/pn_ja.dic');
else callback('Parameter Error! input: ' + dic, 0);
var rl = readline.createInterface({ 'input': rs, 'output': {} }),
point_of_word = 0;
rl.on('line', function (line) {
var line_arr = line.split(':');
if (word == line_arr[0]) {
if (dic == 'jspd') point_of_word = parseFloat(line_arr[2]);
else if (dic == 'pnt') point_of_word = parseFloat(line_arr[3]);
else console.log('ここは出力されないはず');
}
});
rl.on('error', function (err) {
console.log(err);
});
rl.on('close', function () {
// console.log('word: ' + word);
// console.log('verb point in ' + dic + ': ' + point_of_word);
callback(null, point_of_word);
});
}
/**
* 社会的ツイート
* @param id ツイートID
*/
function tweetMeow(id) {
setTimeout(function () {
client.post('statuses/destroy/' + id, function (err, rep) {
if (!err) {
console.log('Delete succeeded.');
setTimeout(function () {
var words = ['わーい!', 'たーのしー!', 'すごーい!',
'大丈夫、夜行性だからっ!', 'ひどいよー!',
'はやくはやくー!'];
var rand = Math.floor( Math.random() * 11 ) ;
var tweet_body = words[rand];
client.post('statuses/update', { status: tweet_body },
function (err, rep) {
if (!err) {
console.log('Tweet succeeded. Meow!');
count++;
} else {
console.log('Tweet failed...');
console.log(err);
}
});
}, 2000);
} else {
console.log('Delete failed...');
console.log(err);
}
});
}, 3000);
}
結果
たーのしー!
考察
スコアリングに使っている辞書が絶望的に Twitter に向かない。
そもそも今回用いた辞書は「一般的な」語句が対象なので、日本語の最先端を征くツイートを分析にかけてもスコアが出てこないのがザラなのはしょうがないですね。
辞書にない単語を自動で追加してスコアを付与する必要がありそう。
それから現状の評価モデルが単語の平均値なので、もうちょっと上手いやり方がないか考えてみます。
次は Electron を使ったクライアントアプリを作ってみて、そこに組み込んでみようと思います。
感想
わーい!(内定出ました)
参考
JSPD
- Nozomi Kobayashi, Kentaro Inui, Yuji Matsumoto, Kenji Tateishi. Collecting Evaluative Expressions for Opinion Extraction, Journal of Natural Language Processing 12(3), 203-222, 2005.
- Masahiko Higashiyama, Kentaro Inui, Yuji Matsumoto. Learning Sentiment of Nouns from Selectional Preferences of Verbs and Adjectives, Proceedings of the 14th Annual Meeting of the Association for Natural Language Processing, pp.584-587, 2008.
PN Table
- Hiroya Takamura, Takashi Inui, Manabu Okumura, "Extracting Semantic Orientations of Words using Spin Model", In Proceedings of the 43rd Annual Meeting of the Association for Computational Linguistics (ACL2005) , pages 133--140, 2005.