はじめに
業務で回帰予測とその分析が必要となったため、調べた結果を記録しようと思います。
今回はGoogle Colaboratory上でXGBoostを用いて回帰予測を行い、Plotlyというグラフライブラリを用いて予測結果をグラフ化することを目的とします。
データセットの準備
今回はKaggleのHouse Pricesデータセットを使用します。
Dataタブからtrain.csvをダウンロードし、自身のGoogle Driveの Dataset/HousePrices/に置きます。
ソースコード
ライブラリのインストールとGoogle Driveのマウント
!pip install plotly
!pip install xgboost
from google.colab import drive
drive.mount("/content/drive")
PlotlyとXGBoostをインストールした後、Google Driveを/content/drive にマウントします。
実行するとGoogle Driveへのアクセス認証を求められるので、リンクをクリックして認証コードをコピペします。
ライブラリのインポート
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
import xgboost as xgb
import plotly.express as px
from sklearn.metrics import mean_squared_error
前処理
# csv読み込み
df = pd.read_csv("/content/drive/MyDrive/Dataset/HousePrices/train.csv")
# ダミー変数化
df = pd.get_dummies(df, drop_first=True)
# SalePrice(住宅価格)を目的変数に設定
y = df["SalePrice"].values
# その他の変数を説明変数に設定
X = df.drop("SalePrice", axis=1).values
# データセットを訓練用と評価用に分割
X_train,X_val,y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=2434)
# xbg用にデータを変換
train_data = xgb.DMatrix(X_train, label=y_train)
valid_data = xgb.DMatrix(X_val, label=y_val)
csvを読み込んでからダミー変数化します。
※ダミー変数化 : 文字列などで表現されるカテゴリ変数をone-hot表現に変換すること
その後、説明変数Xと目的変数yに分割したあと、訓練用データと評価用データに分割します。
最後にXGBoostで扱える形式にデータを変換します。
モデルの設定と学習
# 設定
params = {
'objective': 'reg:squarederror', #最適化指標は二乗誤差
'random_state':2434,
'eval_metric': 'rmse', #評価指標はRMSE(平均二乗誤差)
}
num_round = 500
watchlist = [(train_data, 'train'), (valid_data, 'eval')]
# 学習
model = xgb.train(
params,
train_data, #訓練用データ
num_round, #学習回数
early_stopping_rounds=20,#Early Stoppingのラウンド数
evals=watchlist,
)
モデルの設定を行い学習します。
XGBoostにはEarly Stopping機能というものがあり、early_stopping_roundsのラウンド数以降に評価データで改善が見られなかったら学習が停止するようです。したがってこの機能を使用する際は評価用データを設定する必要があります。
実行すると下記の通り学習が進んでいる様子が表示されます。
実行結果
[0] train-rmse:141228 eval-rmse:141685
Multiple eval metrics have been passed: 'eval-rmse' will be used for early stopping.
Will train until eval-rmse hasn't improved in 20 rounds.
[1] train-rmse:101813 eval-rmse:102151
[2] train-rmse:74027.4 eval-rmse:76227.1
[3] train-rmse:54432.6 eval-rmse:58662.4
[4] train-rmse:40782.2 eval-rmse:47039.5
[5] train-rmse:31041.5 eval-rmse:39315.5
...
[52] train-rmse:3745.88 eval-rmse:27971
[53] train-rmse:3663.9 eval-rmse:27959.4
Stopping. Best iteration:
[33] train-rmse:5461.96 eval-rmse:27927.7
予測とグラフ表示
# 評価データの予測
y_pred = model.predict(valid_data,ntree_limit = model.best_ntree_limit)
# 予測結果の平均二乗誤差を求める
rmse = np.sqrt(mean_squared_error(y_val,y_pred))
# 散布図グラフの設定
fig = px.scatter(
x=y_val, #x方向のデータ(真値)
y=y_pred, #y方向のデータ(予測値)
labels={
'x': 'ground truth',
'y': 'prediction'
}
)
# x=yの直線を引く
fig.add_shape(
type="line", line=dict(dash='dash'),
x0=y.min(), y0=y.min(),
x1=y.max(), y1=y.max()
)
# 予測結果の誤差をテキストで表示
fig.add_annotation(
text=f"rmse={rmse:.4}",
xref="paper", yref="paper",
x=0.1, y=0.8,
showarrow=False,
)
# デフォルトでドラッグしたときにグラフの移動するように設定
fig.update_layout(
dragmode="pan",
)
# グラフの表示
fig.show(config=dict({"scrollZoom":True}))
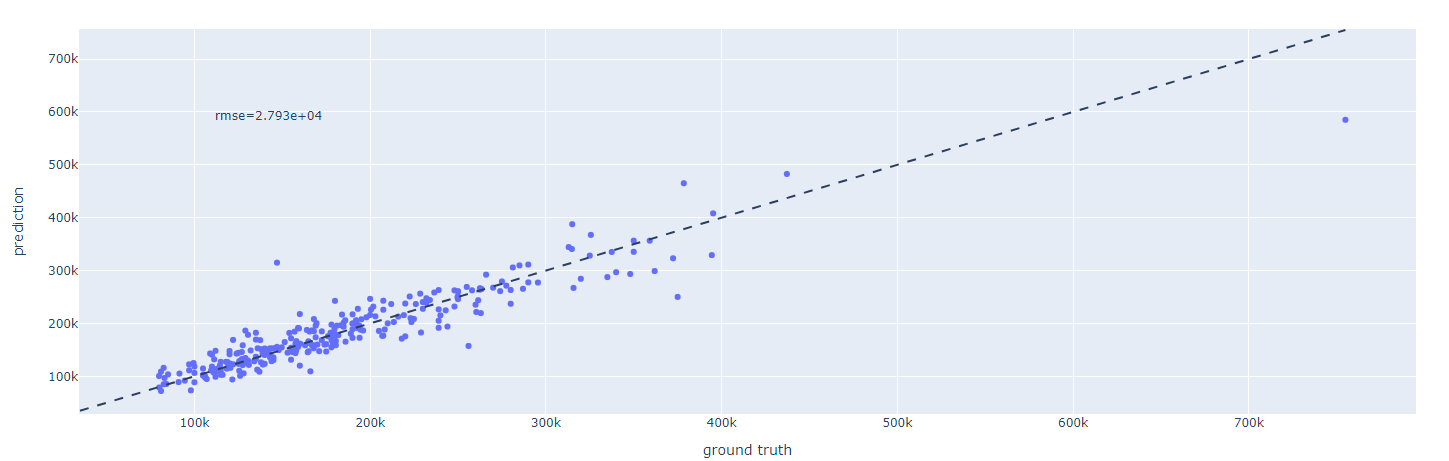
Plotlyでグラフを表示します。
Google Colaboratory上で実行するとセルの実行結果の場所にグラフが下記のように表示されます。
Plotlyではグラフをズームしたり移動したりとインタラクティブに操作ができるので便利です。
ソースコード全文
!pip install plotly
!pip install xgboost
from google.colab import drive
drive.mount("/content/drive")
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
import xgboost as xgb
import plotly.express as px
from sklearn.metrics import mean_squared_error
# csv読み込み
df = pd.read_csv("/content/drive/MyDrive/Dataset/HousePrices/train.csv")
# ダミー変数化
df = pd.get_dummies(df, drop_first=True)
# SalePrice(住宅価格)を目的変数に設定
y = df["SalePrice"].values
# その他の変数を説明変数に設定
X = df.drop("SalePrice", axis=1).values
# データセットを訓練用と評価用に分割
X_train,X_val,y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=2434)
# xbg用にデータを変換
train_data = xgb.DMatrix(X_train, label=y_train)
valid_data = xgb.DMatrix(X_val, label=y_val)
# 設定
params = {
'objective': 'reg:squarederror', #最適化指標は二乗誤差
'random_state':2434,
'eval_metric': 'rmse', #評価指標はRMSE(平均二乗誤差)
}
num_round = 500
watchlist = [(train_data, 'train'), (valid_data, 'eval')]
# 学習
model = xgb.train(
params,
train_data, #訓練用データ
num_round, #学習回数
early_stopping_rounds=20,#Early Stoppingのラウンド数
evals=watchlist,
)
# 評価データの予測
y_pred = model.predict(valid_data,ntree_limit = model.best_ntree_limit)
# 予測結果の平均二乗誤差を求める
rmse = np.sqrt(mean_squared_error(y_val,y_pred))
# 散布図グラフの設定
fig = px.scatter(
x=y_val, #x方向のデータ(真値)
y=y_pred, #y方向のデータ(予測値)
labels={
'x': 'ground truth',
'y': 'prediction'
}
)
# x=yの直線を引く
fig.add_shape(
type="line", line=dict(dash='dash'),
x0=y.min(), y0=y.min(),
x1=y.max(), y1=y.max()
)
# 予測結果の誤差をテキストで表示
fig.add_annotation(
text=f"rmse={rmse:.4}",
xref="paper", yref="paper",
x=0.1, y=0.8,
showarrow=False,
)
# デフォルトでドラッグしたときにグラフの移動をするように設定
fig.update_layout(
dragmode="pan",
)
# グラフの表示
fig.show(config=dict({"scrollZoom":True}))