はじめに
DWHとかデータレイクとか扱うお仕事でGlueを使うことになったので勉強もかねてまとめ。
※実装とかには触れないので、概念とかこんなもんか~を知りたい方向けです
Glueとは
データの分類、クリーニング、加工を優れたコスト効果で容易に行い、さまざまなデータストア間およびデータストリーム間でデータを確実に移動するための、完全マネージド型ETL (Extract/Transform/Load、抽出/変換/ロード) サービス
※参照:https://docs.aws.amazon.com/ja_jp/glue/latest/dg/what-is-glue.html
例えば、IFされるJSONデータをDBに入れたいんだけど、そのままの形式ではDBに入れられないからDBに入れるように加工してあげてロードまでやっちゃおうね、というイメージ。(ETL読んで字の如くではあるが)
S3、DynamoDB、Redshift、RDS等と連携可能で、用途としては、データウェアハウス・データレイク構築に向いている。
稼働イメージ
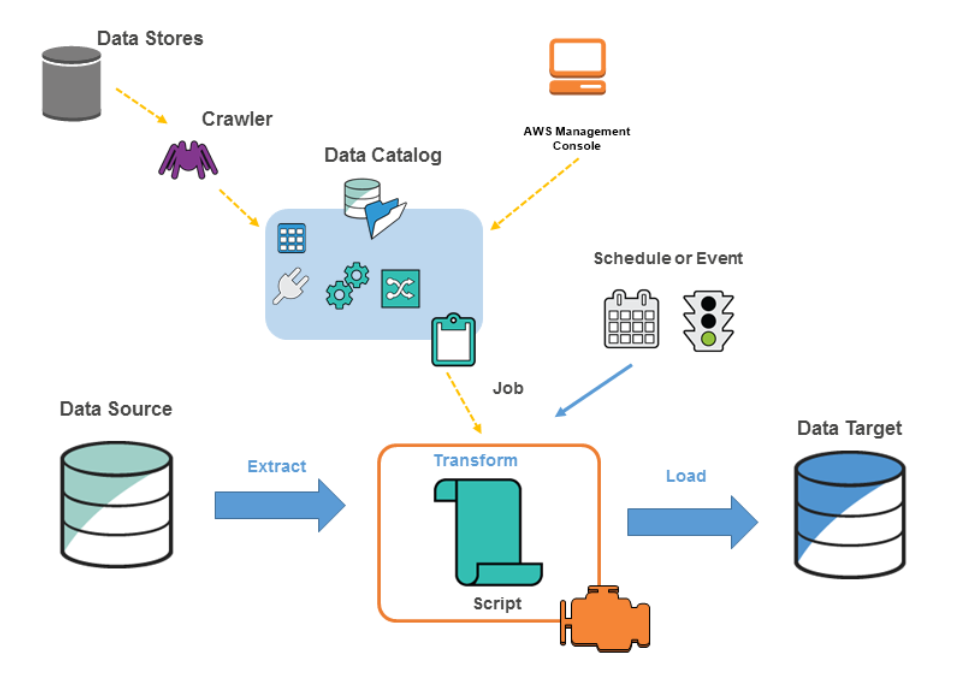
■図の用語について
・データストア:データを永続的に保存するリポジトリ(S3、RDBなど)
・クローラ:データストアに接続し、データカタログにメタデータテーブルを作成するプログラム
・データカタログ:テーブル定義、ジョブ定義などのメタデータが集約されたもの
・ジョブ:ETL作業のビジネスロジック。オンデマンド、スケジュール、イベントトリガーで実行可能。
・データソース:インプット(加工対象データ)
・データターゲット:アウトプット(データのロード先)
クローラって、データカタログって、結局何なの、、、というのが初見での感想 (技術系公式ドキュメント読むとだいたいこうなる)
先ほどの例で考えてみると、JSONを加工する用のジョブのスクリプトだったり、加工したあとにアウトプットになるDBの情報(テーブル、カラム、型など)だったり、要するに処理に必要な情報をため込んでいる箱のようなものかなと。で、クローラは、そのDBのテーブル情報を作ってくれる担当というイメージ。
なんとなく、わかった気がする、、、!
まとめ
Glueの基礎の基礎くらいは認識できた気がしています。
実装部分については、まだ触っていないのでよくわからないですが、また知識が増えたら投稿しようかなあと思います。