概要
以下の記事を参考に,OllamaとOpen WebUIを使用してローカルLLMの環境を構築しました。
Gemma 3 で RAG 機能付きの安全なローカル AI チャット環境を構築する
ただし,計算機を置いている環境が厄介なプロキシ環境下で一筋縄ではいかなかったので,備忘録を残しておきます。
作業環境
Linux Ubuntu 24.04
Linux環境変数にはプロキシ設定とCA証明書を導入済み
Step 1 Ollamaの導入
Ollamaの公式サイトに書いてある通りOllamaをダウンロード&インストール
curl -fsSL https://ollama.com/install.sh | sh
インストール後,Ollamaが起動していることを確認します。
ollama --version
ollama version is 0.X.Xと出れば正常に起動しています。
また正常に動作していれば,ウェブブラウザでlocalhost:11434に接続してみると,「Ollama is running」という表示が出ます。
Step 2 Open WebUIの導入
Dockerを使ってOpen WebUIをインストールします。
docker pull ghcr.io/open-webui/open-webui:main
さてここでプロキシが邪魔をしました。
Error response from deamon: Get "https://ghcr.io/v2/": EOF
このエラーはDockerがpullでインターネット上のレジストリにアクセスする際に,プロキシを経由していないことが原因です。そこでDockerデーモンにプロキシの設定を追加します。
まずはDockerサービスの設定を上書きするためのディレクトリを作成します。
sudo mkdir -p /etc/systemd/system/docker.service.d
次に,作成したディレクトリ内にプロキシ設定用のファイルを新規作成します。
sudo nano /etc/systemd/system/docker.service.d/proxy_setting.conf
ファイル名はproxy_settingに限らず,わかりやすいもので構いません。
開いたファイルに,自身のプロキシ環境に合わせて以下の内容を記述します。
【認証無しの例】
[Service]
Environment="HTTP_PROXY=http://your-proxy-address:port"
Environment="HTTPS_PROXY=http://your-proxy-address:port"
Environment="NO_PROXY=localhost,127.0.0.1,.example.com"
【認証有りの例】
[Service]
Environment="HTTP_PROXY=http://user:password@your-proxy-address:port"
Environment="HTTPS_PROXY=http://user:password@your-proxy-address:port"
Environment="NO_PROXY=localhost,127.0.0.1,.example.com"
http://your-proxy-address:port の部分を自身のプロキシサーバーのアドレスとポート番号に置き換えてください。
ファイルを保存したらsystemdに設定の変更を認識させ,Dockerデーモンを再起動して設定を反映させます。
sudo systemctl daemon-reload
sudo systemctl restart docker
これでDockerのプロキシの設定は完了です。設定が反映されているかは以下のコマンドで確認できます。
docker info | grep -i proxy
設定したプロキシの情報が表示されれば設定は成功しています。
以上の設定によりdocker pull ghcr.io/open-webui/open-webui:mainの(プロキシに起因する)エラーは解消されるはずです。pullが完了してイメージを取得できたら,次はプロキシサーバーのCA証明書をインストールしたカスタムイメージを用意します。
作業用に適当なディレクトリ(例: ~/open-webui-docker)にプロキシ証明書を置き,同じディレクトリに Dockerfileという名前で以下の内容のファイルを作成します。
FROM ghcr.io/open-webui/open-webui:main
COPY ./proxy-ca.crt /usr/local/share/ca-certificates/proxy-ca.crt
RUN update-ca-certificates
RUN cp /etc/ssl/certs/ca-certificates.crt /usr/local/lib/python3.11/site-packages/certifi/cacert.pem
2行目のproxy-ca.crtは手元の証明書ファイル名に置き換えてください。
なお,Linux環境なので証明書の拡張子は.crtを使用してください。
(4行目は不要かもしれません。また,内部で使用されているPythonのバージョンが変わった場合は記述も変更する必要があります。)
Dockerfileとproxy-ca.crtがあるディレクトリで以下のコマンドを実行して,証明書がインストール済みの新しいDockerイメージを作成します。
docker build -t open-webui-proxy .
done.と表示されれば完了です。
カスタムイメージを起動します。
docker run -d -p 3000:8080 \
-e OLLAMA_API_URL="http://<ホストIP>:11434" \
-e HTTP_PROXY="http://your-proxy-address:port" \
-e HTTPS_PROXY="http://your-proxy-address:port" \
-e NO_PROXY="localhost,127.0.0.1,<ホストIP>" \
--add-host=host.docker.internal:host-gateway \
-v open-webui:/app/backend/data \
--name open-webui \
--restart always \
open-webui-proxy
Dockerコンテナにもプロキシの設定を追加して起動します。
特に,<ホストIP>(=自分のマシンのIPアドレス)をNO_PROXYで明示的に指定することで,OllamaとOpen WebUIの接続時のエラーを回避できます。なお,ハッシュを使った書き方(192.168.0.0/16のような書き方)は認識しないので注意してください。
Step 3-1 ollama経由でのLLMモデルの導入
ollama経由でLLMモデルをダウンロードしようとしました。
今回は例としてGoogleのGemma 3をダウンロードします。
ollama pull gemma3:27b
モデルの種類(4b,12b,27b)はマシンのスペックに合わせて適宜変更してください。
さて,ここでもプロキシが邪魔をしてError: pull model manifest: Get...となります。Dockerのときと同じように,Ollamaにもプロキシ設定を追加することでこのエラーは回避できますが,先に結論を言うと邪悪なプロキシ環境下ではollamaを経由してのモデル導入は無理でした。そのため,ollamaを経由せず直接モデルをダウンロードして導入します。
【補足】 Ollamaへのプロキシ設定の追加とその後何が起こったか
以下のコマンドを実行すると,Ollamaサービスの設定を上書きするためのファイルがエディタで開きます。
sudo systemctl edit ollama.service
開いたエディタにプロキシ環境に合わせた内容を記述します。
内容はDockerの時と全く同じなので割愛します。
ファイルを保存してエディタを終了したらsystemdに設定の変更を認識させ,Ollamaを再起動して設定を反映させます。
sudo systemctl daemon-reload
sudo systemctl restart ollama
これでプロキシは通るので,ollama pullを実行するとモデルのダウンロードは開始されます。
しかし私の環境では,ダウンロードの完了間際にError: digest mismatch, file must be downloaded again: want sha256:<文字列> got sha256:<別の文字列>というエラーが出ました。
Ollamaは、モデルのファイルをダウンロードした後,そのファイルの「ダイジェスト」(SHA256ハッシュ値という一種のデジタル指紋)を計算します。そして,サーバーから受け取った「本来あるべき正しい指紋」と照合します。この2つが一致しない場合に上記のようなエラーが発生する用です。
はっきりとした原因は特定できていないものの,どうやらプロキシサーバーを通る際にセキュリティ関連の何かが悪さをして,一部のファイルが置き換わってしまっているようです(邪悪な挙動...)。
Step 3-2 モデルデータファイルからのLLMモデルの導入
Hugging FaceというプラットフォームからLLMのモデルデータ(ggufファイル)を直接ダウンロードして手動でOllamaに導入します。Hugging FaceにはGoogleの公式リポジトリもありますがggufファイルは提供されていなさそうなので,有志がggufにフォーマット変換したものをダウンロードします。
ダウンロードが完了したらModelfileを作成します。
nano Modelfile
モデルファイルの中身は以下の通り。
FROM ./<ダウンロードしたモデル名>.gguf
TEMPLATE"""{{ ~~~略~~~
{{end}}"""
PARAMETER ~~~略~~~
TEMPLATEとPARAMETERの中身はモデル毎に適宜書き込む必要があります。
有名どころのローカルLLMモデルについてのTEMPLATEとPARAMETERの書き方はOllamaの公式ページからも参照することができます。
ダウンロードしたggufファイルと作成したModelfileを同じディレクトリに置き,そのディレクトリ内で次のコマンドを実行します。
ollama create <好きな名前> -f Modelfile
successと表示されればモデルの導入は完了です。
Step 4 Open WebUIでLLMを使う
ウェブブラウザでhttp://localhost:3000にアクセスすると,Open WebUIが開きます。
初回アクセス時にはアカウントの作成が必要です。
ログイン後,左下のユーザーの設定画面から「管理者パネル」を開き,「設定」の「接続」の画面を開きます。
Ollama API接続の管理の項目に,localhostではなく<ホストIP>を使ってhttp://<ホストIP>:11434を入力し,「保存」を押せば設定は完了です。
(Dockerコンテナの中から見たlocalhost(または127.0.0.1)はコンテナ自身を指してしまい,PC本体(ホストOS)で動いているOllamaに到達できないらしいです。)
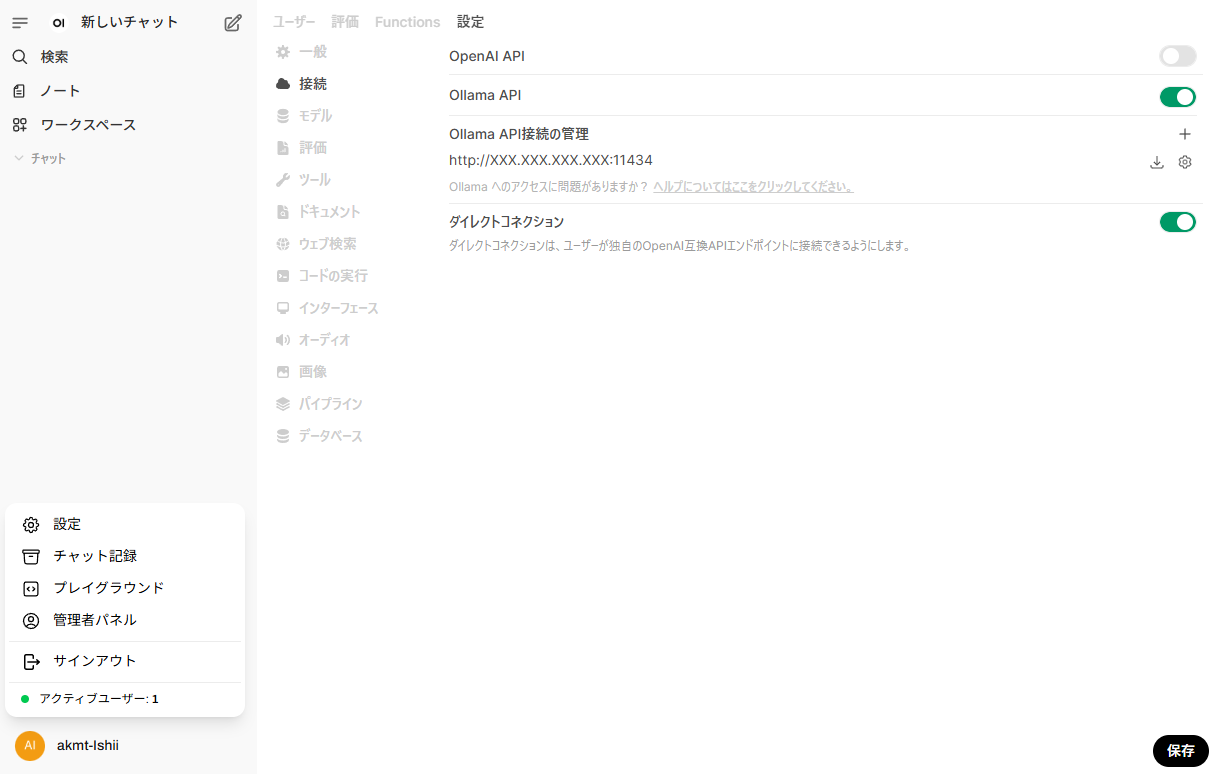
これで用意したモデルが選択できるようになり,チャットが開始できるはずです。
問題点
- Dockerコンテナをrunしてからアクセスできるようになるまで長い時間がかかる。
- LLMでのWeb検索機能がプロキシにブロックされて使えない。
これらの問題点への対処は後編で説明します。