ここまでの話
前編からの続きです。
プロキシ環境下でOllamaとOpenWebUIを使用してローカルLLM環境を構築したものの,
- DockerコンテナをrunしてからOpen WebUIのページにアクセスできるようになるまで長い時間がかかる。
- LLMでのWeb検索機能がプロキシにブロックされて使えない。
という問題があったのでこれらを解決していきます。
Step 5 起動が遅い問題への対処
DockerコンテナをrunしてからウェブブラウザでOpen WebUIのページにアクセスできるようになるまで,長いと10分くらいのラグが発生していました。内部で何をしているかを知るために,Dockerコンテナのリアルタイムログを以下のコマンドから見てみます。
docker logs open-webui -f
すると,次のような表示が大量に出ていました。
{"timestamp":"2025-06-11T02:27:20.953078Z","level":"WARN","fields":{"message":"Retry attempt #0. Sleeping 356.191ms before the next attempt"},"filename":"/root/.cargo/registry/src/index.crates.io-1949cf8c6b5b557f/reqwest-retry-0.6.1/src/middleware.rs","line_number":166}
しばらく時間が経過しOpen WebUIのページにアクセスできるようになる直前には次のエラー表示がありました。
RuntimeError: Data processing error: CAS service error : Reqwest Error: HTTP status client error (429 Too Many Requests), domain: https://cas-server.xethub.hf.co/reconstruction/f6041cb139310735d267939642554a0199a828a08edc37b0ddaf3b035eea5df4
このエラーは,Open WebUIコンテナからHugging Faceのサーバー(hf.co)に通信しているが,サーバー側から「あなたのネットワークからのアクセスが多すぎるため一時的にリクエストを制限します」と応答されている状態です。
つまり,起動時にHugging Faceのサーバーにアクセスを試しては失敗するということをエラー判定が出るまでひたすら繰り返していたことが,起動が遅い原因でした。
そもそもローカルで動かす前提のWebUIがなぜHugging Faceと通信しようとしているか?という問題ですが,これは,Open WebUIのドキュメント検索(RAG)機能のための「埋め込みモデル」のデフォルト設定がHugging Faceに保管されているものであり,そのモデルを初回起動時にダウンロードしようとするためです。
つまり埋め込みモデルもローカルに用意してしまえば通信は不要になるので,起動は高速になり,LLM環境も完全にローカルで完結させることができます。埋め込みモデルの導入方法は前編のStep 3-2で行ったggufファイルをダウンロードして行う方法と同じなので割愛します。私はnomic-embed-text-v1.5.Q4_K_Mを採用しました。
モデルをローカルに用意したら一度コンテナを起動し,Open WebUIの管理者パネルの設定から「ドキュメント」を開きます。ここに,Enbeddingという項目があるので以下を記入します。
- 埋め込みモデルエンジンはOllama
- APIベースURLはOllamaのURL(接続の設定と同じもの)
- 埋め込みモデルには用意したモデル名
この設定を保存することで,ローカルの埋め込みモデルが参照されるようになります。
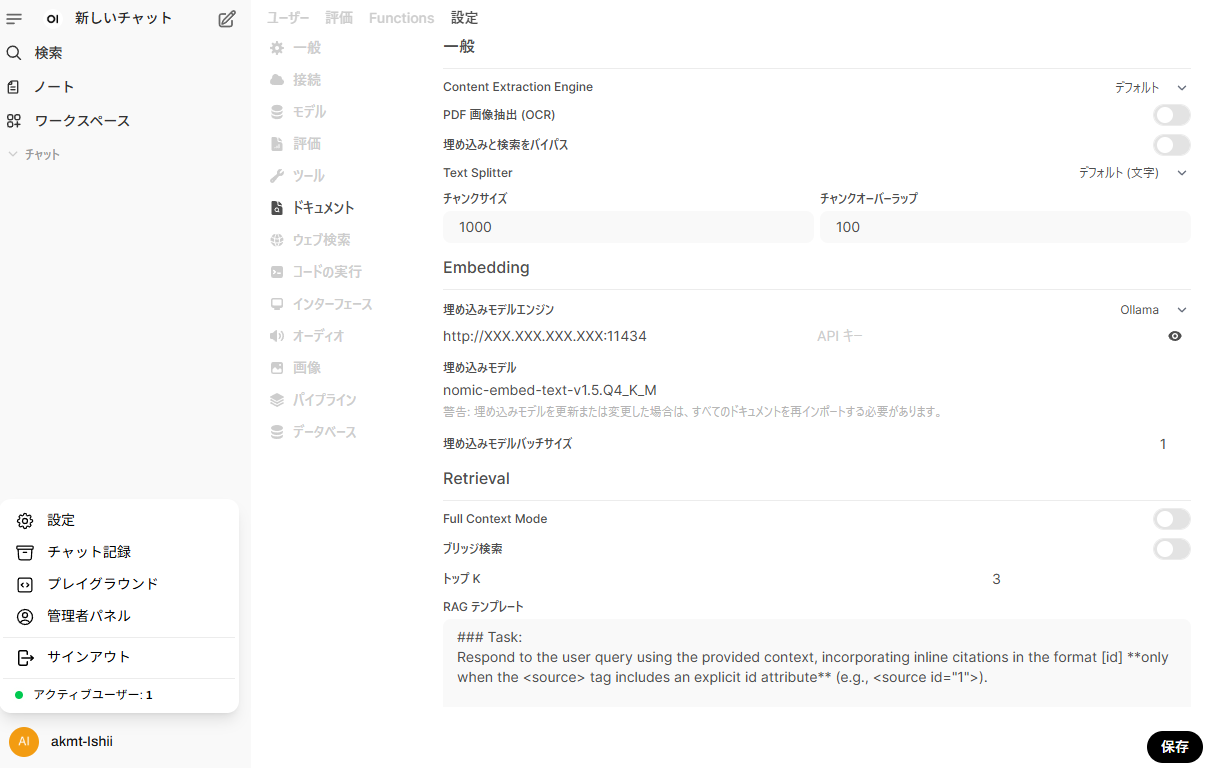
この埋め込みモデルはチャットには使えないものの,チャット用のモデル選択の選択肢には出てきてしまうので,管理者パネルの設定から「モデル」の画面から埋め込みモデルは無効にしておくのが良いでしょう(無効にしても選択肢に出なくなるだけなので裏では動作します。)

Step 6 Web検索機能が使えない問題への対処
Open WebUIではLLMにウェブ上の情報を検索しながら回答させる「ウェブ検索」機能がありますが,この機能を使うためには基本的に検索エンジンのAPIキー(多くが有料)が必要です。Open WebUIに対応している検索エンジンの中でDuckDuckGoは唯一APIキーを必要としませんが,これが当方のプロキシ環境と相性が悪く通信がどうしてもできませんでした。
また,SearXNGという無料のメタ検索エンジンの公開サーバーを使うことも考えましたが,LLMから要求されるjson形式での検索が許可されていないため検索に失敗してしまい問題解決には至りませんでした。
そこで,手元のLinuxマシンで非公開のSearXNGサーバーを建てる方針としました。
まずプロジェクトディレクトリ(searxng-docker)を作成し,その中でsearxng-dockerをクローンします。
git clone https://github.com/searxng/searxng-docker
この中のdocker-compose.yamlの内容を次のように編集します。
services:
searxng:
image: searxng/searxng:latest
container_name: searxng
restart: unless-stopped
ports:
- "8080:8080"
environment:
- SEARXNG_BASE_URL=http://localhost:8080/
- HTTP_PROXY=http://your-proxy-address:port
- HTTPS_PROXY=http://your-proxy-address:port
- NO_PROXY=redis,localhost,127.0.0.1,.example.com
depends_on:
- redis
networks:
- searxng-network
volumes:
- ./searxng/settings.yml:/etc/searxng/settings.yml:ro
- ./searxng-certs:/etc/ssl/custom_certs:ro
redis:
image: redis:alpine
container_name: redis
restart: unless-stopped
volumes:
- ./redis-data:/data
networks:
- searxng-network
networks:
searxng-network:
driver: bridge
また,searxngディレクトリにあるsettings.ymlも編集します。
use_default_settings: true
server:
secret_key: <自身で生成したランダムな文字列>
redis:
host: redis
port: 6379
db: 0
outgoing:
proxies:
http: http://your-proxy-address:port
https: http://your-proxy-address:port
verify: /etc/ssl/custom_certs/proxy-ca.crt
search:
formats:
- html
- json
searchの設定のformatsでhtml形式やjson形式の検索を許可することを明示します。
ランダムな文字列は以下のコマンドで生成可能です。
openssl rand -hex 32
最後に,searxng-dockerの中にsearxng-certsというディレクトリを作成し,その中にプロキシ証明書(proxy-ca.crt)を置いてください。
以上の準備が出来たら,searxng-dockerの中で以下のコマンドを入力することで起動します。
docker compose up -d
初回はイメージのダウンロードに少し時間がかかります。起動後,ウェブブラウザでhttp://localhost:8080にアクセスするとSearXNGの検索画面が表示されるはずです。適当な語句を検索して検索結果が出れば成功です。
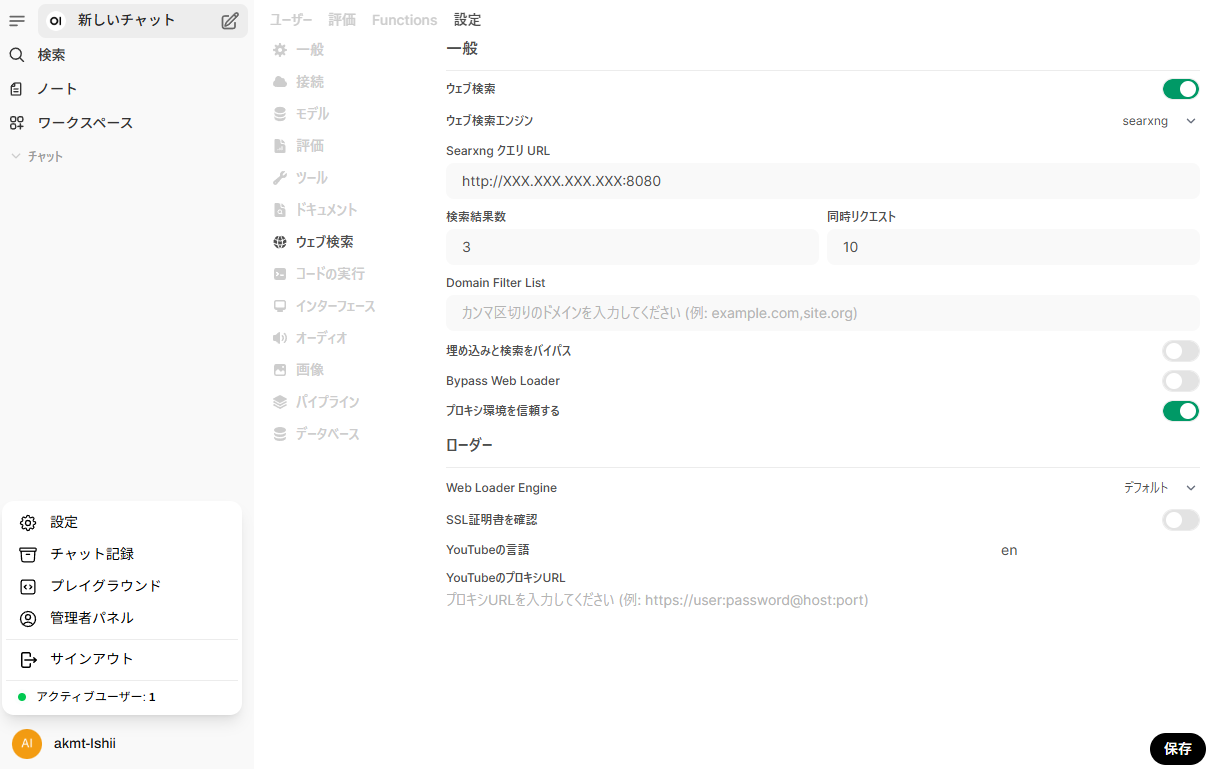
最後に,例によってOpen WebUIの管理者パネルの設定の「ウェブ検索」に設定を書き込みます。
- 検索エンジンはsearxng
- SearxngクエリURLは
http://<ホストIP>:8080 - プロキシ環境を信頼するをオン
以上の設定を保存した後,チャット画面で「ウェブ検索」をオンにした状態で「今日の天気」のようなLLM自体が学習していない情報を聞いて,正しい答えが返ってくれば成功です。
最後に
さらっとまとめましたが邪悪なプロキシに散々苦しめられ環境が出来上がるまでに丸二日かかりました。このメモが誰かの役に立てば幸いです.