気がついたら年明けて1ヶ月経ってびっくり![]()
今日は、MySQLでSQLチューニングについて学ぶよ
お仕事でMySQLを使っているので、この書き方が良いらしい・・みたいなことは知っているのですが、
本当に有効なのかを検証していきたいと思います。
前書き
検証テーマ
1.SELECT文の書き方で速度はどれくらい変わるのか?←今回の記事
2.INDEXの貼り方で速度はどのくらい変わるのか←準備中
検証内容
下記に記載されているSQLチューニング方法のうち、気になったものを抜粋し、速度比較を実施。
参考ページ:https://style.potepan.com/articles/26070.html
参考ページ:https://qiita.com/ichi_zamurai/items/fdbe3872a505c22ee431
参考図書:達人に学ぶ SQL徹底指南書 (CodeZine BOOKS)
この記事ではなぜ速くなるのかなどの理由には触れていないので、気になった方は上記より!
検証環境
・Docker(20.10.7)
・MySQL(Server version: 8.0.27)
今回はSQLチューニングが目的なので、MySQLの環境設定は文字コード等の最低限設定しか行っていません。
速度の定義
SQLの実行にかかった時間=events_stages_history_long.TIMER_WAITの値(秒)として計測。
参考ページ:MySQL公式
検証用TBL
名前、年齢、血液型や誕生日といった個人情報が入ったTBLを、カラム数とデータ量に差をつけて準備。
1.users_13_s: カラム数多×データ量小(13×100行)
2.users_13_m: カラム数多×データ量中(13×5000行)
3.users_13_l: カラム数多×データ量多(13×1万行)
4.users_6_s: カラム数小×データ量小(6×100行)
5.users_6_m: カラム数小×データ量中(6×5000行)
6.users_6_l: カラム数小×データ量多(6×1万行)
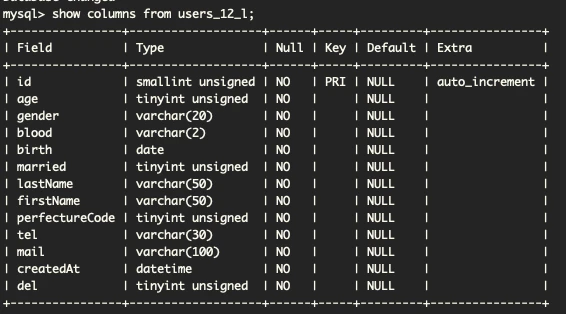
【カラム数 13(users_13_*)テーブル構成】
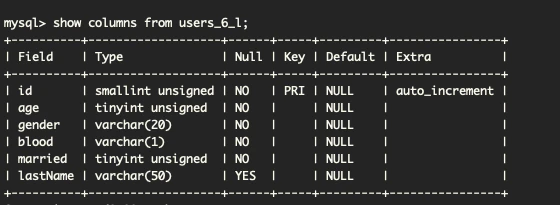
【カラム数6(users_6_*)テーブル構成】
カラム数12と6で試していたつもりが、今記事を書いている時に13だったことに気がついた![]()
実際のTBL名と違うけれど、記事上はusers_13~と書く![]()
【各カラムの値】
id : 整数型 連番 主キー
age : 整数型 0~69のランダム
gender: femaleかmale の文字列型 大体半々
blood: A ,B,O,AB いずれかの文字列型 A40%,B20%,O30%,AB10%となるように準備
birth:YYYY/MM/DDのDATE型
married: 1か0 の整数型 大体半々
lastName: 文字列型 漢字
firstName: 文字列型 漢字
prefectureCode: 整数型 1~47のランダム
tel:文字列型
mail:文字列型
createdAt: Datetime型
del: 1か0の整数型
*今回はprimaryKeyのみでINDEXは貼っていません。
はてさて前置き長くなったけれど、ここから検証結果を書いていくよー![]()
検証と結果
*結果は2種類の表を用いて説明しています。
【スコア】 各条件毎の結果
【比較】 同じSQLに対する速度が速い方のカラムに色付け&速度差を算出。
(3つで比較の場合は最大値と最小値の引き算)
疑問1 : 大文字SELECT vs 小文字select だと、SELECTのほうが早いってほんと?
: 大文字SELECT vs 小文字select だと、SELECTのほうが早いってほんと?
テスト内容: 下記4種類のSQLを10回実行し、各平均値を算出。大文字、小文字での違いをテーブルサイズごとの比較を実施。
1.SELECT * FROM users_XXX WHERE 1 = 1
2.SELECT * FROM users_XXX WHERE gender = 'male'
3.SELECT * FROM users_12_s WHERE married = 1
4.SELECT * FROM users_XXX WHERE age > 40
--小文字の例
1. select * from users_XXX where 1 = 1
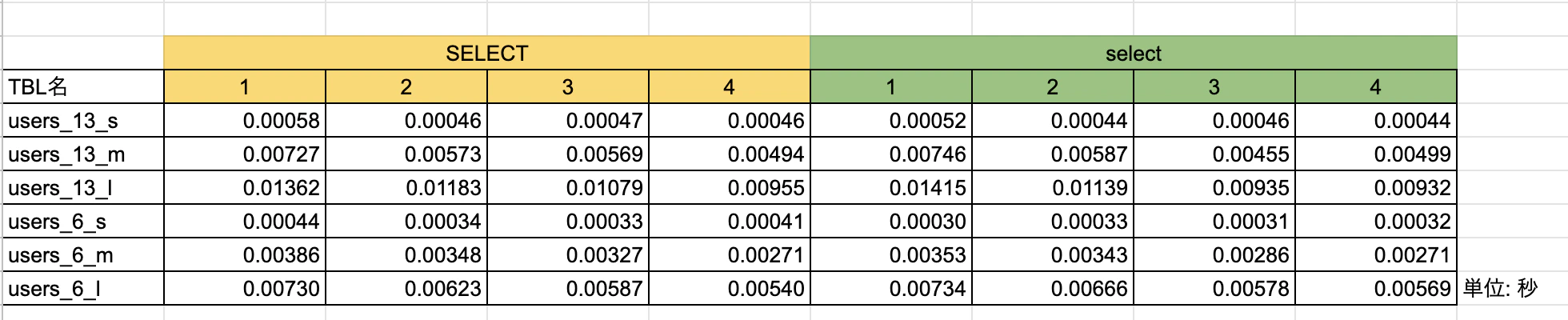
【スコア】
【比較】
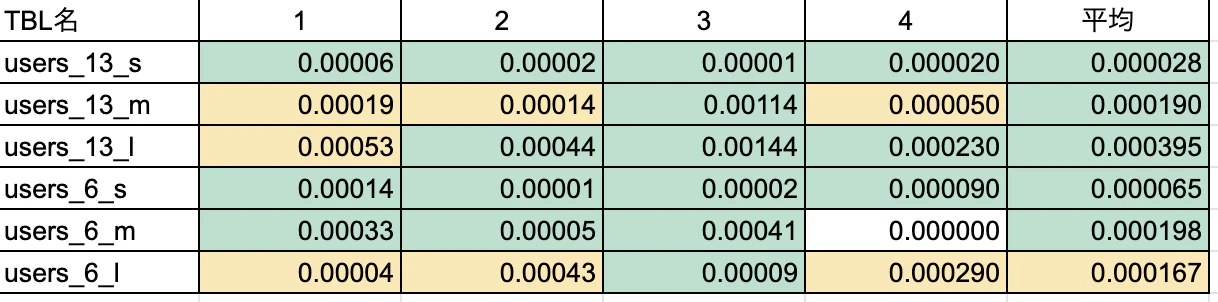
あれ・・・?selectのほうが早い・・?
よくよく記事を参照すると、「大文字で書くことでキャッシュを使う確率が上がる」との記載があり、
mysql8.0のようにクエリキャッシュが廃止されている場合は、効果が得られないのかなと推測。
そもそも、クエリキャッシュは場合によっては遅くなる可能性もあり、
5.7でも非推奨となっているくらいなので、わざわざこの速度のためにキャッシュをONにするのは正しくないのかな。
mysql公式
結論 : クエリキャッシュが廃止されたmysql8.0で試したところ、selectのほうが速いかも。
: クエリキャッシュが廃止されたmysql8.0で試したところ、selectのほうが速いかも。
疑問2 : TBL名.カラム名 vs カラム名 だと、TBL名.カラム名のほうが早いってほんと?
テスト内容:SELECT句をすべてのカラム、半分のカラム、1つのカラムの3パターンで実施。下記4種類のSQLを10回実行した平均値で、テーブルサイズ×カラム数ごとの比較を実施。
1.SELECT X-テスト毎-X FROM users_XXX WHERE 1 = 1
2.SELECT X-テスト毎-X FROM users_XXX WHERE gender = 'male'
3.SELECT X-テスト毎-X FROM users_XXX WHERE married = 1
4.SELECT X-テスト毎-X FROM users_XXX WHERE age > 40
【スコア】

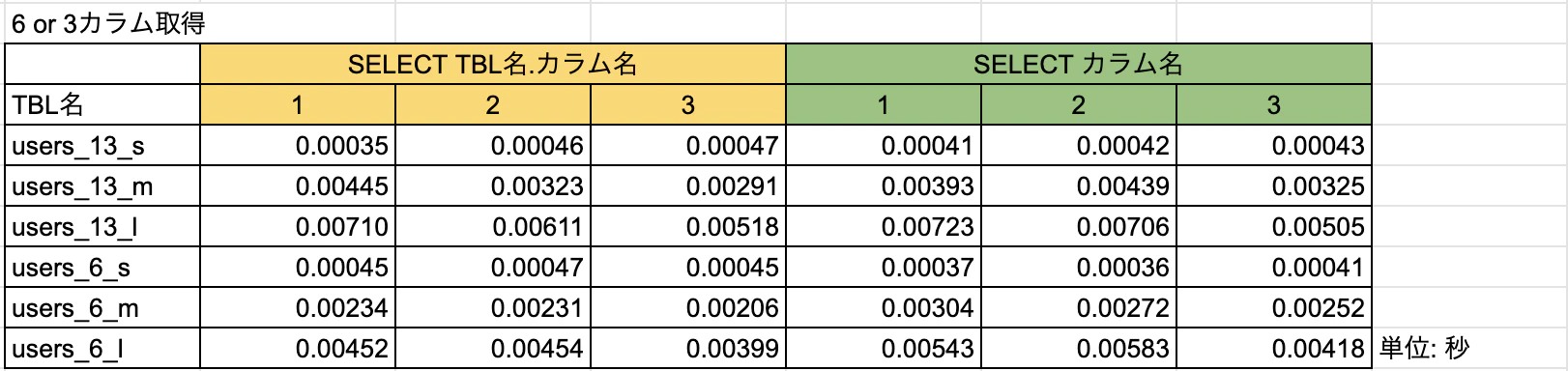
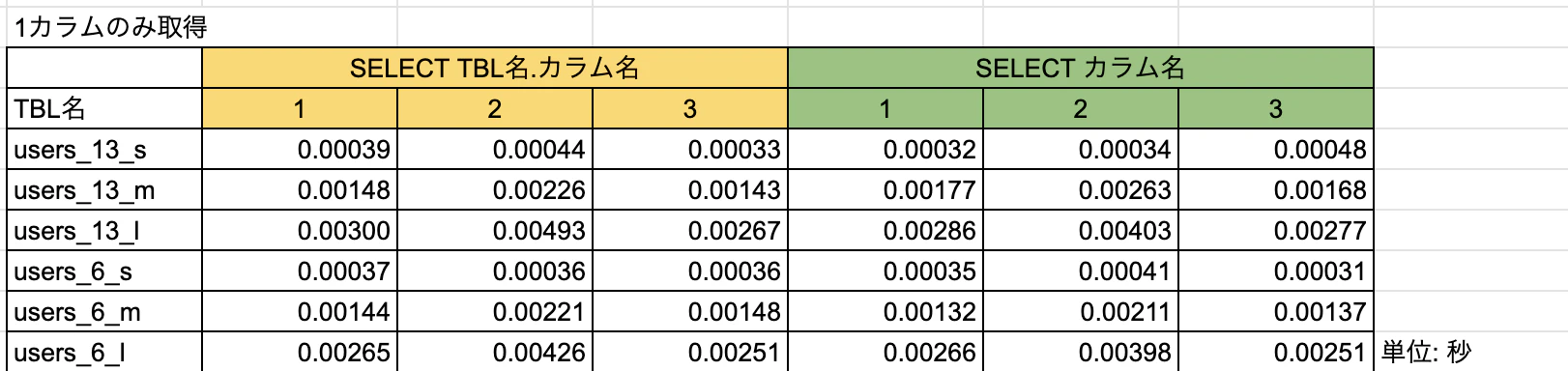
【比較】
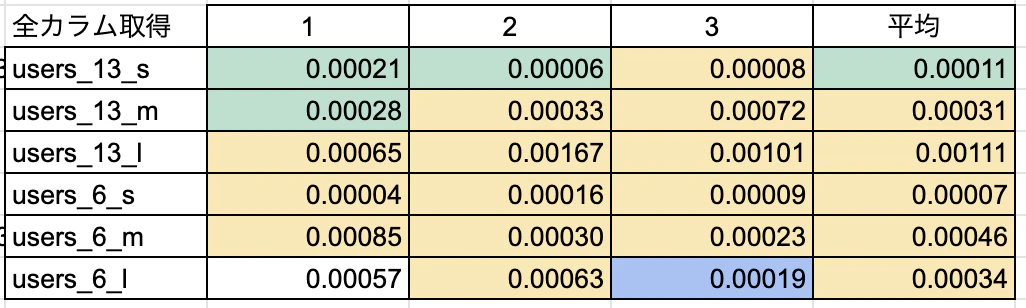
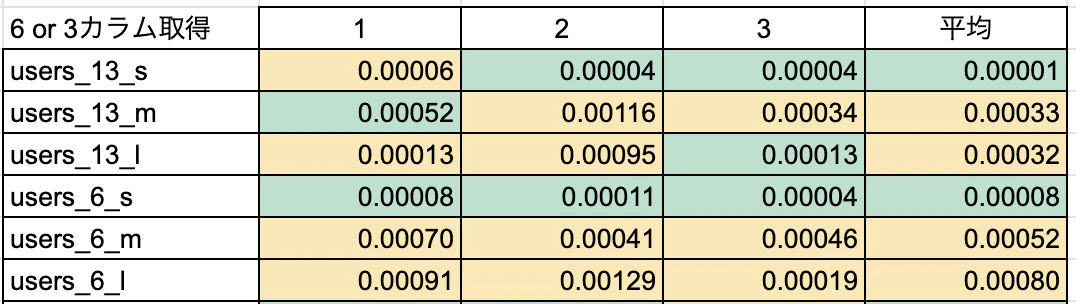
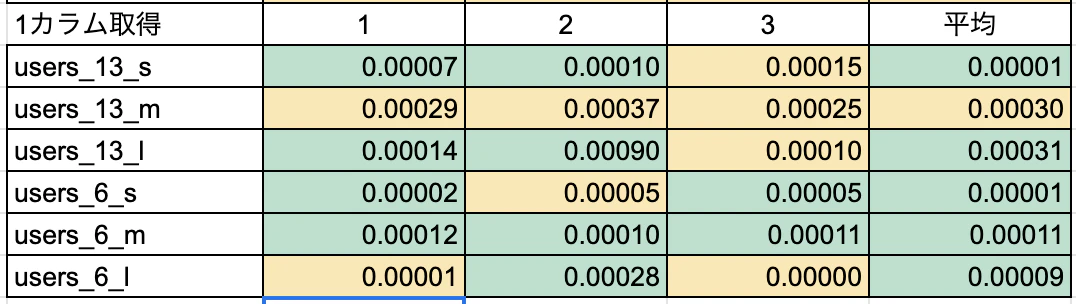
結論 : 全項目取得の場合は*よりも圧倒的にカラム名指定の方が早い!取得するカラム数やテーブルサイズが大きければ大きいほど、TBL名.カラム名のほうが有効かも。
疑問3 :データ型が正しいWHERE文 vs データ型が正しくないWHERE文だと、正しいほうが早いってほんと?
テスト内容: 整数型のカラムに対し、WHERE句を整数型と文字列型の2パターン実施。下記3種類のSQLをそれぞれ10回実行した平均値で比較。
1.SELECT * FROM users_XXX WHERE married = 1 / '1'
2.SELECT * FROM users_XXX WHERE age = 73 / '73'
3.SELECT * FROM users_XXX WHERE id = 9 /'9'
【スコア】
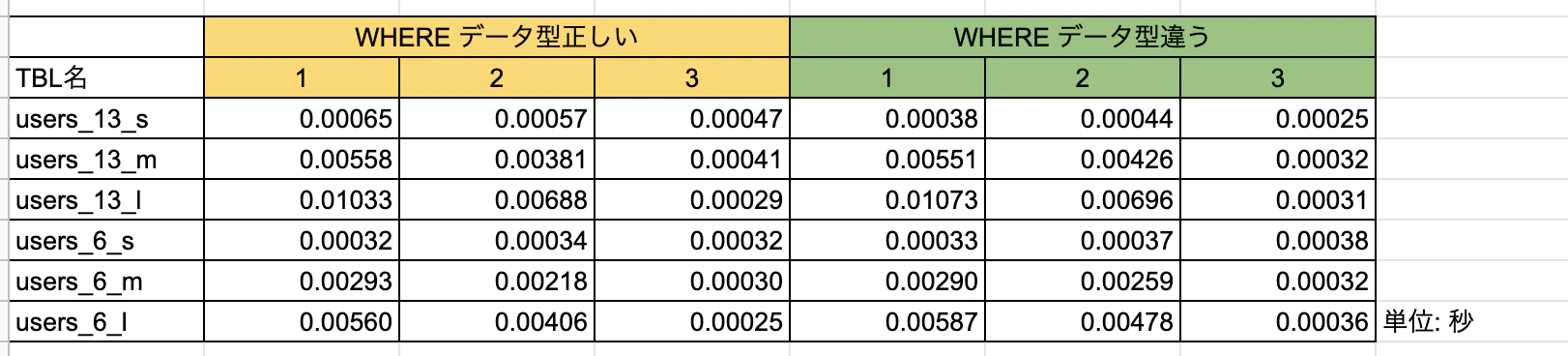
【比較】
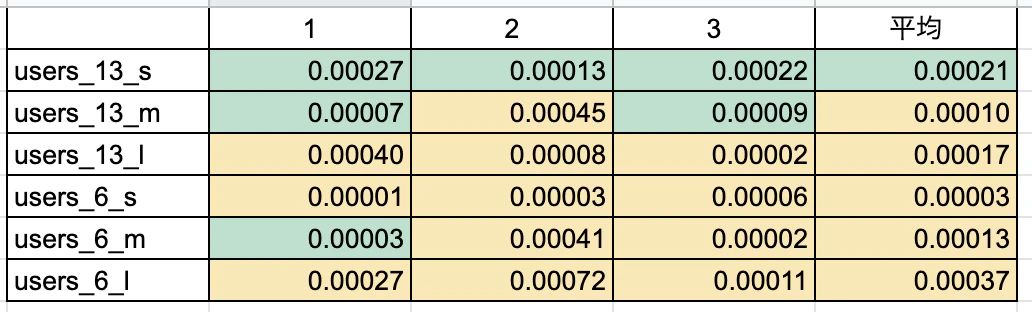
結論 :users_13_sだけ速度がなぜかかなり遅いが、それ以外はデータ型が正しいWHERE文の方が早いことが多い。
疑問4 :WHERE XXX IN(多い順) vs WHERE XXX IN (適当)だと、多い順のほうが早いってほんと?
テスト内容: A40%,O30%,B20%,AB10%で設定されたblood項目に対し、下記4種類のSQLをそれぞれ10回実行した平均で速度を比較。
1.SELECT * FROM users_XXX WHERE blood IN ('A','AB') / ('AB','A')
2.SELECT * FROM users_XXX WHERE blood IN ('O','B') / ('B','O')
3.SELECT * FROM users_XXX WHERE blood IN ('O','B','AB') / ('AB','O','B')
3.SELECT * FROM users_XXX WHERE blood IN ('A','O','AB') / ('O','AB','A')
【スコア】

【比較】
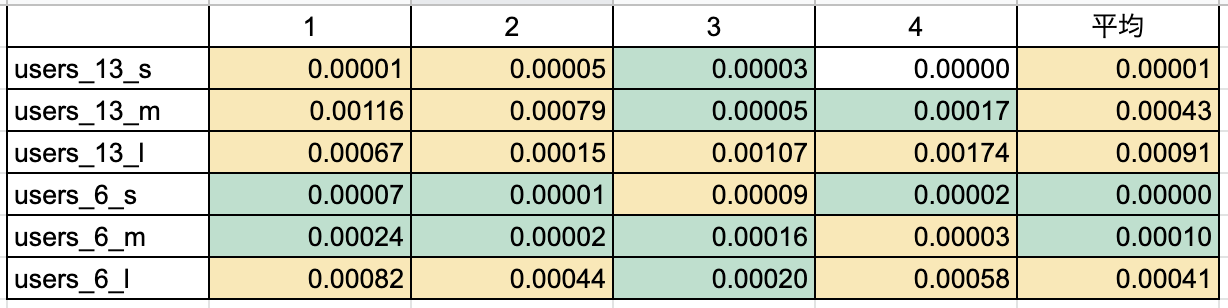
結論 データ量とカラム数が小さいとあまり違いがないが、カラム数13×データ量大だと順序が正しい方が全体的に早くなった。
疑問5 :BETWEEN vs <> だとBETWEENの方が早いってほんと?
1.SELECT * FROM users_XXX WHERE age BETWEEN 10 AND 35 / age >= 10 AND age <= 35
2.SELECT * FROM users_XXX WHERE id BETWEEN 340 AND 350 / id >= 340 AND id <= 350
3.SELECT * FROM users_XXX WHERE age BETWEEN 50 AND 100 / age >= 50 AND age <= 100
4.SELECT * FROM users_XXX WHERE id BETWEEN 50 AND 450 / id >= 50 AND id <= 450
【スコア】

【比較】
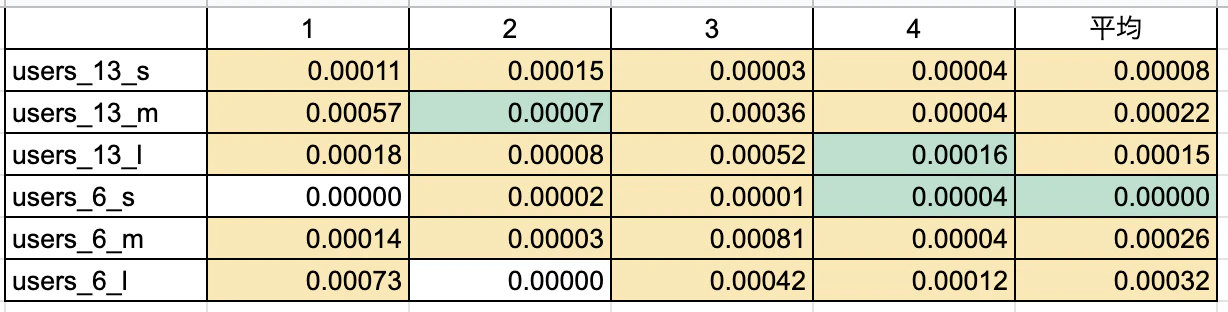
おお、これは綺麗な結果が出た・・
結論5 :ほぼ全てのパターンで効果がありそう。
疑問6 :EXISTS vs IN vs INNER JOIN だとEXISTSが早いってほんと?
テスト内容: 顧客のオーダー情報的なTBLを連結用に用意。下記4種類のSQLを10回実行した平均で、それぞれの記載方法の速度を比較。
連結用TBL:orders / orders.userId = users_XXX.id
--- EXISTS
1.SELECT * FROM users_XXX AS main WHERE EXISTS (SELECT 1 FROM orders WHERE orders.userId = main.id AND paymentType = 1)
2.SELECT * FROM users_XXX AS main WHERE EXISTS (SELECT 1 FROM orders WHERE orders.userId = main.id AND orderDate BETWEEN '2000-01-01' AND '2020-01-01')
3.SELECT * FROM users_XXX AS main WHERE EXISTS (SELECT 1 FROM orders WHERE orders.userId = main.id AND id > 40)
4.SELECT * FROM users_XXX AS main WHERE EXISTS (SELECT 1 FROM orders WHERE orders.userId = main.id AND paymentType IN ('0','1'))
-- INの場合は下記のような形式
SELECT * FROM users_XXX AS main WHERE id IN (SELECT userId FROM orders WHERE paymentType = 1)
-- INNER JOINの場合は下記のような形式
SELECT * FROM users_XXX AS main INNER JOIN (SELECT DISTINCT userId FROM orders WHERE paymentType = 1) AS tmp ON tmp.userId = main.id
【スコア】

【比較】
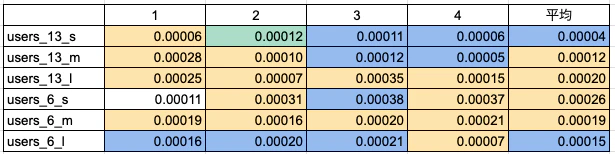
結論6 : 平均を見るとEXISTSが良さそう。INNER JOINの方が速度が出るパターンもあるので、使い方によるのかも。
疑問7 : ORDER BY カラム名 vs ORDER BY カラム番号 だと、カラム名指定のほうが早いってほんと?
1.SELECT * FROM users_XXX WHERE age > 50 ORDER BY id / ORDER BY 1
2.SELECT * FROM users_XXX WHERE married = 0 ORDER BY age / ORDER BY 2
3.SELECT * FROM users_XXX WHERE blood = 'A' ORDER BY id,age / ORDER BY 1,2
4.SELECT * FROM users_XXX WHERE gender = 'female' ORDER BY id,age /ORDER BY 1,2
【スコア】

【比較】
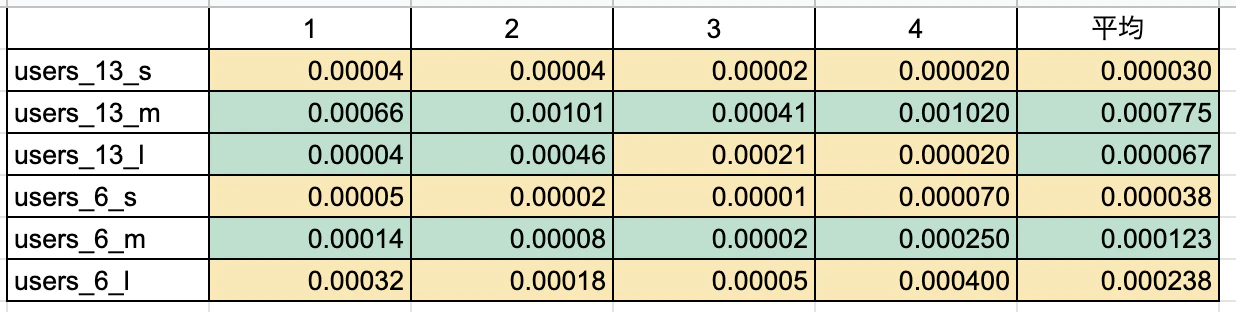
こ、これは・・・。
列名への読み替えが発生しているから遅くなるはずなのに・・違いが出なかった・・。
ORDER BY で指定する数を増やしたらもっと変わるのかしら・・
結論7: relaxed: :違いを捕捉できなかった 
まとめ
今回はよく聞くけれど実際どのくらい効果あるかわからないものと、ちょっと疑わしい・・と勝手に思っていたものを抜粋して検証しました。次回はINDEX編と題して、同じように試していきます。
今回の検証も、INDEX有無で変わるものもあるのかもしれないので、その辺りも絡めて見ていきたいと思います。
計測方法や、内容に誤りやアドバイスがあれば、ご連絡いただけると嬉しいです!
参考
https://style.potepan.com/articles/26070.html
https://qiita.com/ichi_zamurai/items/fdbe3872a505c22ee431
【テストデータ】
こちらのツールで作成したデータに必要な加工を加えて準備しました↓
参考:テストデータ生成