こんにちは。![]() だよ。
だよ。
夏も終わるねー。朝晩が涼しくて、気持ちがいいよね。
さてさて今日は新しくなった(らしい)TwitterAPIのSearchを使ってみるよ。
TwitterAPI v2で変わったことは?
詳しくは公式を読んでね。 ![]() がおっと思ったところだけ載せると・・
がおっと思ったところだけ載せると・・
-
v1では、スタンダード・プレミアム・エンタープライズの3つのプランごと、別々のAPIが提供されていた。
→v2では1つのAPIに対して、Basic・Elevate・Customのアクセスレベルを設定するようになった。
プランの切り替え時にAPIの変更が不要になり、移行が容易に! -
デフォルトのレスポンスはコンパクトになり、必要なデータフィールドをAPIのparameterで指定することで、必要な情報だけを取得できるようになった。
しかも、取得できるデータフィールドもより詳細になったらしい!以前よりもデータの活用度が上がりそうだね!
実際のフィールドは、お試ししながら説明するよ。 -
レスポンスとしてconversation_idを取得できるように!
誰かの呟きに対して、返信、それのまた返信、など会話が続いた場合に、一致するIDを持っているため、会話の流れを追いやすくなったみたいだよ!
間違っていたらごめんね。
実際に使ってみよう.
- 環境:
- Python3.8.5
- 使用したライブラリ:
- urllib3
- json
- 前準備:
- Twitter API 利用申請
- Twitter APIを使うためには、利用申請が必要なんだけれど、こちらはいろいろわかりやすい記事が多いので、今回は割愛するよ。
今回、認証はOAuth 2.0 Bearer tokenを使って行うよ。
このKeyはTwitterのDeveloperPortalにログインし、
「Project」→「今回使用するプロジェクト」→「Keys and tokens」の画面から、発行ができるよ。
API:Tweet lookup
Tweetごとの固有Idを指定して探す方法だよ。
https://api.twitter.com/2/tweets/ + XXXXXX
XXXXはWeb画面でツイートを開いた時のURLの最後の部分(多分数字)が入るよ。
pythonではこんなコードを書いたよ。
1.デフォルトの項目だけ取得する場合。
2.項目を選択して取得する場合 の2パターンを試してみるよ。
import urllib3
import setting #Key項目を設定しているファイルだよ。別で管理していない人は、KEY=直書きしてね。
import json
http = urllib3.PoolManager()
KEY = setting.TWITTER_BEARER_TOKEN ## DeveloperPortalで取得したBearer Token。お試し時は、直書きでもOK。
def getTweetById(http, key, searchId, searchFeild={}):
url = 'https://api.twitter.com/2/tweets/' + searchId
req = http.request('GET',
url,
headers= {'Authorization': 'Bearer '+key},
fields = searchFeild
)
result = json.loads(req.data)
if (req.status == 200):
print(result)
else:
print(req.status)
print(result['errors'])
# 1. デフォルトの項目を取ってくる場合
getTweetById(http,KEY, "XX-TweetID-XX")
# 2. 項目を選んで取ってくる場合
params = {"expansions" :'author_id,attachments.media_keys',
'media.fields' : 'preview_image_url,type',
'place.fields' : 'country,country_code',
'tweet.fields' : 'created_at,lang',
'user.fields' : 'created_at,description,id,name'
}
getTweetById(http,KEY, "XX-TweetID-XX",params)
1.デフォルトの項目を取ってくる場合で試してみよう。
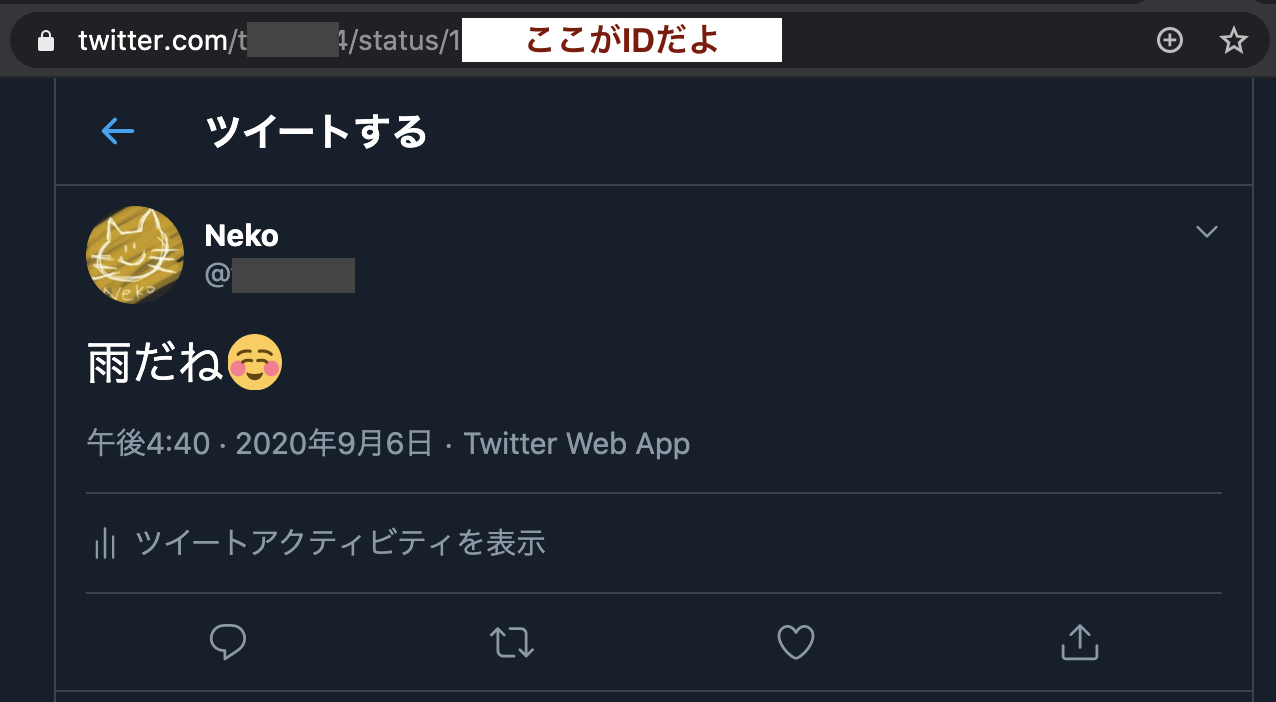
実行すると・・

こんな感じ。
2. 項目を選んで取ってくる場合を試してみよう。

なるほど、さっきよりいろいろな情報がとってきているね。
でも、よーくみると、指定したのに入っていないフィールドもあるね。
唐突にフィールドのお勉強
フィールドは5つあって、
| 戻り値 | フィールド名 | 内容 |
|---|---|---|
| Tweet | tweet.fields | ツイート本体に関する情報 |
| User | user.fields | ツイートしたユーザーに関する情報 |
| Media | media.fields | ツイートに添付されたファイルの情報。添付あった場合のみ表示される。 |
| Poll | poll.fields | 投票形式のツイートに関する情報。投票の場合のみ表示される。 |
| Place | place.fields | Tweetした場所に関する情報。ロケーション情報が含まれている場合のみ表示される。 |
となっているよ。
今回はただのテキストなので、TweetとUserの情報しかとってこなかったんだね。
上記を踏まえて、画像付きのURLを2のパターンで取得するとどうなるかな?
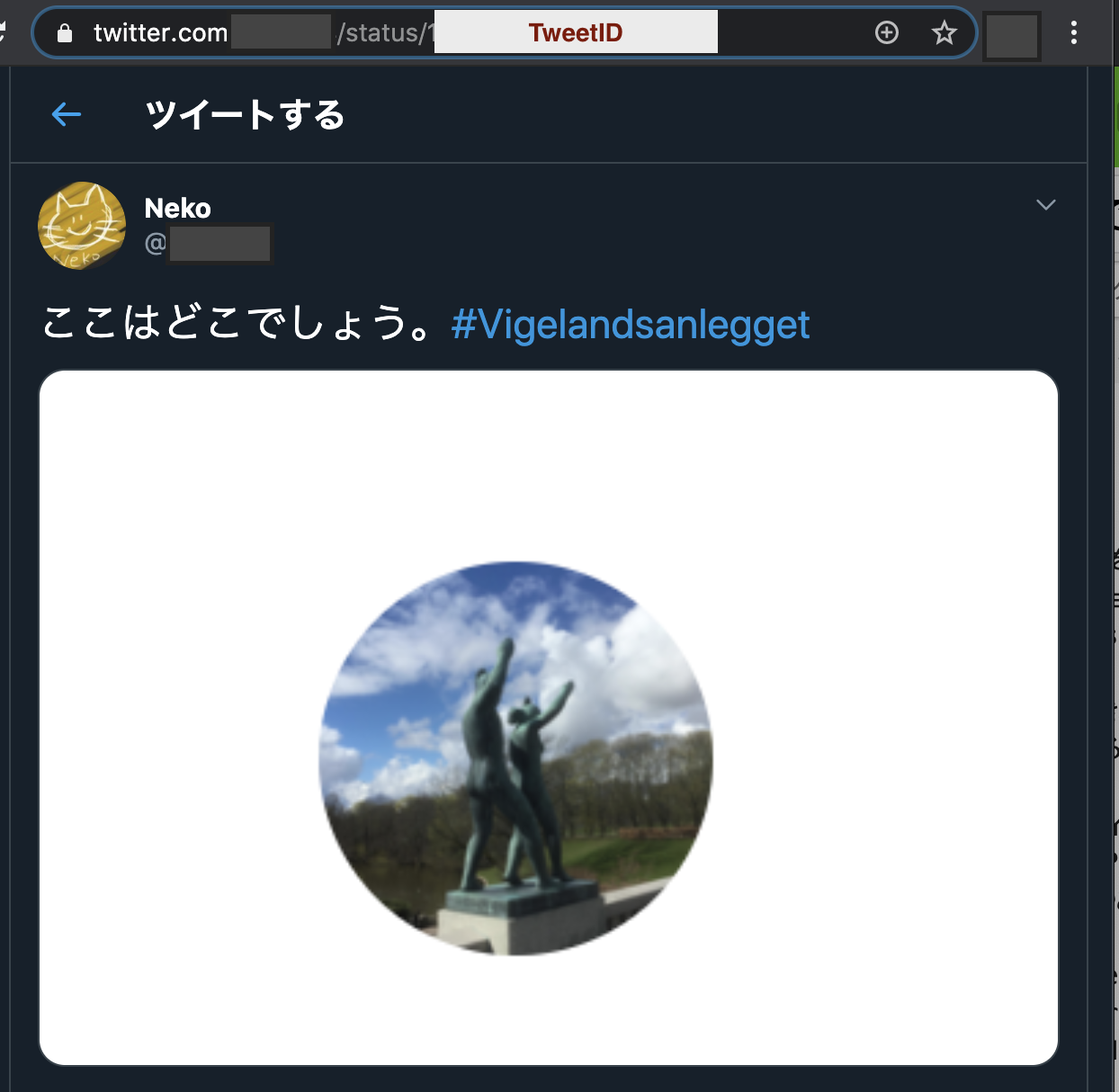

おお、メディア情報が含まれるようになったね。
API:Tweet recent search
Tweetの内容で探す方法だよ。
https://api.twitter.com/2/tweets/search/recent
searchの名前の通り、Tweetの内容や誰が書いたかで検索してデータをとってくることができるよ。
過去7日間のデータが対象だよ。
pythonではこんなコードを書いたよ。
paramsによって1〜5の内容を調べられるよ。
1.Tweetの内容で検索をしてみよう
2.Tweetをした人で検索してみよう
3.AND条件で検索してみよう
4.OR条件で検索してみよう
5.もっと詳細も調べてみよう
import urllib3
import setting #別で管理していない人は、KEY=直書きしてね。
import json
http = urllib3.PoolManager()
KEY = setting.TWITTER_BEARER_TOKEN ## DeveloperPortalで取得したBearer Token。お試し時は直書きでもOK。
def getTweetByText(http,key,searchFeild):
url = 'https://api.twitter.com/2/tweets/search/recent'
req = http.request('GET',
url,
headers= {'Authorization': 'Bearer '+key},
fields = searchFeild
)
result = json.loads(req.data)
if (req.status == 200):
if ('meta' in result):
print('検索結果は' + str(result['meta']['result_count']) + '件でした')
if ('data' in result):
for tweet in result['data']:
print(tweet)
else:
print(req.status)
print(result['errors'])
# 1.Tweetの内容で検索をしてみよう。
params1 = {'query' : 'ねこ'}
# 2.Tweetをした人で検索してみよう。
params2 = {'query' : 'from:tokyo_bousai'}
# 3.AND条件で検索してみよう
params3 = {'query' : 'from:tokyo_bousai #防災の日'}
# 4.OR条件で検索してみよう
params4 = {'query' : 'from:tokyo_bousai OR from:KanagawaPref_PR'}
# 5.もっと詳細も調べてみよう
params5 = {
'query' : 'from:tokyo_bousai',
'max_results' : 100,
'expansions' : 'author_id,attachments.media_keys',
'media.fields' : 'preview_image_url,type',
'place.fields' : 'country,country_code',
'tweet.fields' : 'created_at,lang',
'user.fields' : 'created_at,description,id,name'
}
getTweetByText(http, KEY, XX-調べたいparams-XX)
実行結果をかくと長くなるので、実際は動かしてみて欲しいな![]()
簡単に解説すると、検索の条件をqueryに書くよ。
・このワードに引っかかるツイートを検索したい! → 1
・この人のTweetを検索したい! →2 fromの後ろは「@XXXX」のXXXか、userIDが使えるよ。
・AND条件→3 条件同士の間をスペースで繋ぐよ。
・OR条件→4 条件同士をORで繋ぐよ。
5のように、ID検索で使ったFiled選択も使えるし、デフォルトの取得件数は10件なので、
'max_results' : XXX(~100)でもっと多くのデータを取得したい時もOKだよ。
もちろんもっと複雑な検索もできて、それは公式のここを参考にするとわかりやすいよ。
まとめ
v1を使ったことがないので、比較がうまくできないけれど、簡単にTweetを取得できたよ。
また今回は手っ取り早く、OAuth 2.0 Bearer token方式で認証をしたけれど、分析などに使用されるメトリック(という言い方であっているのかな?)を取得するにはOAuth 1.0方式でuserAccessTokenを渡す必要があるみたいだよ。
実はTweetを取得してそれを分析に使いたくてここまで準備を進めてきたので、次回はそっちの話ができると良いな。