やあ ![]() だよ。
だよ。
突然だけど、有吉の壁が好きだよ。
水曜の夜ってあと二日働くのか・・と絶望するけれど、有吉の壁を見て、元気を出して頑張っているよ。
Twitterにも同じような呟きがたくさんあったので、皆さんのご意見を使って、
有吉の壁の「おもしろいとは?」「すきとは?」をword2vecのお勉強を兼ねて、見てみたいと思うよ。
有吉の壁とは?
日テレ公式:有吉の壁
『有吉の壁』は、日本テレビ系列で放送されているバラエティ番組。有吉弘行の冠番組。 2015年4月7日 - 2020年1月5日まで深夜帯を中心に不定期の特別番組として13回放送したのち、2020年4月8日より、毎週水曜日の19:00 - 19:56でレギュラー放送中。(Wikipedia参照)
word2vecとは?
自然言語処理の一つで、テキストデータを解析して単語同士の意味をベクトル表現する方法。
どんなことができるの?
・単語同士の関連性を表現できる。
・単語同士を足したり、引いたりして、別の単語を計算することができる。
この辺はわかりやすい記事がたくさんあるから、そちらを読んでね。
![]() には論理が難しすぎだよ・・。
には論理が難しすぎだよ・・。
手順
- 有吉の壁に関するTweetを集める。(TwitterAPI)
- データを綺麗にする。(Mecab)
- モデルを作成する。(word2Vec)
- モデルにいろいろ聞いてみる。
1.有吉の壁に関するTweetを集める。(TwitterAPI)
まずはモデルのものになるTweetを集めるよ。
import urllib3
import setting
import json
## TwitterAPIv2のBeaterToken方式で認証をしています。
## keyはpython-dotenvで管理していて、settingsで呼び出しています。
## お試しする場合は、直接指定してもらえればOKなはず。
def getTweetByText(http, key, searchFeild):
url = 'https://api.twitter.com/2/tweets/search/recent'
req = http.request('GET',
url,
headers= {'Authorization': 'Bearer '+key},
fields = searchFeild
)
result = json.loads(req.data)
if (req.status == 200):
if ('meta' in result):
print('検索結果は' + str(result['meta']['result_count']) + '件です')
return result
else:
print(req.status)
print(result['errors'])
def getTweet(fileName):
http = urllib3.PoolManager()
KEY = setting.TWITTER_BEARER_TOKEN
keyword = '(#有吉の壁 OR 有吉の壁) -is:retweet'
params = {
'query' : keyword,
'max_results' : 100,
'expansions' : 'author_id,attachments.media_keys',
'tweet.fields' : 'created_at,lang,entities',
'user.fields' : 'name'
}
with open( fileName + ".csv",'a') as f:
writer = csv.writer(f)
tweets = twitterApi.getTweetByText(http, KEY, params)
hasNextToken = True
while hasNextToken:
for tweet in tweets['data']:
l_tags, l_annotations = [], []
if ('entities' in tweet) :
##今回分析に使用しているのは本文ですが、ハッシュタグなども収集。何かにいつか使いたい!
if ('hashtags' in tweet['entities']) :
l_tags = [d.get('tag') for d in tweet['entities']['hashtags']]
if ('annotations' in tweet['entities']) :
l_annotations = [d.get('normalized_text') for d in tweet['entities']['annotations']]
writer.writerow([tweet['id'],tweet['author_id'], tweet['created_at'], tweet['text'],l_tags,l_annotations])
##API1回の実行で取得できる上限があるので、2回目以降はnext_tokenを引数に渡して、続きを取ってくるようにする。
if ('meta' in tweets):
if ('next_token' in tweets['meta']) :
params['next_token'] = tweets['meta']['next_token']
tweets = twitterApi.getTweetByText(http, KEY, params)
else :
hasNextToken = False
fileName = 'kabeModel' + str(datetime.date.today())
getTweet(fileName)
今回は#有吉の壁のハッシュタグつきか、文章に「有吉の壁」が入っているTweetを集めたよ。
期間は2020/09/22 ~ 2020/09/15 で全部で24295件を使用しました。
(詳しいAPIの使い方はこちらの記事
個人のTweetなので中身は掲載しないけれど、多彩なTweetが集まって、この時点でもうだいぶ楽しい![]()
2.データを綺麗にする。(Mecab)
はてさてTweetを集められたら次はデータを整形&不要なデータの削除をしていくよ。
まずはデータの整形! Mecabを使うよ。
Mecabとは?
公式:MeCab
オープンソースの形態素解析エンジンだよ。日本語を単語で区切って、品詞・活用を割り出すことができるよ。
今回はデフォルト辞書:mecab-ipadic-NEologdを使用したんだけれど、ここで1個気がついた・・

芸人さんのコンビ名など辞書に載っていないものは、固有名詞として認識されないんだね。
四千頭身さん、区切られすぎてて笑った。
そこで、WikipediaからMediaWikiAPIを使って、芸人さんのコンビ名を根こそぎ持ってきてユーザー辞書も用意。
組織名として準備したよ。(APIの使い方などは後日投稿します。)

アームストロングさん好きだったな・・![]()
これを適用するとこんな感じで四千頭身さんも「四千頭身」になります。

続いて、stopwordsの削除も実施。
stopwordとは「あれ」とか「これ」とか文章に頻出するけれど、意味をなさない言葉だよ。
こちらのサイトに公開されているstopwordの一覧を使って当てはまるものは削除するようにしたよ。
PGMは次でまとめて公開するよ。
3. モデルを作成する。(word2Vec)
2の内容をやりつつword2vecにデータを渡すよ。
import urllib3
import urllib
import json
import pandas as pd
import csv
import MeCab as mb
from gensim.models import word2vec
def getStopwords():
url = 'http://svn.sourceforge.jp/svnroot/slothlib/CSharp/Version1/SlothLib/NLP/Filter/StopWord/word/Japanese.txt'
res = urllib.request.urlopen(url)
slothlib_stopwords = [row.decode("utf-8").strip() for row in res]
slothlib_stopwords = [ss for ss in slothlib_stopwords if not ss==u'']
return slothlib_stopwords
def parseByMecab(text):
##辞書の場所は各自の環境に合わせて編集してね。
tagger = mb.Tagger('-d /usr/XX-それぞれの環境によって場所が違うよ-XX/mecab-ipadic-neologd -u /home/XX-ユーザー辞書をおいた場所だよ-XX/XX-ユーザー辞書の名前だよ-XX.dic')
word_list = []
node = tagger.parseToNode(text)
while node:
pos = node.feature.split(",")[0]
## 名詞・動詞・形容詞を取得するようにしたいよ。
if pos in ["名詞", "動詞", "形容詞"]:
word = node.surface; ##区切られたワードを取ってくる
word_list.append(word)
node = node.next
return "\n".join(word_list).strip()
def delStopwords(text,stopwords):
word = [word for word in text.split(" ") if not word in stopwords]
words = "\n".join(word).strip()
return words
def makeWord2VecModel(fileName):
stopwords = getStopwords();
## pandasでCSV取り込み dataFram型で返却されるので便利
tweet_df = pd.read_csv(fileName + '.csv', names=('id', 'author_id', 'created_at', 'text', 'tags', 'annotations'))
tweet_df['mecabText'] = tweet_df['text'].apply(lambda x: parseByMecab(x))
tweet_df['delStopWordText'] = tweet_df['mecabText'].apply(lambda x:delStopwords(x, stopwords))
sentence = [token.split("\n") for token in tweet_df['delStopWordText']]
## size 単語ベクトルの次元数 公式のサンプルが100だったので・・
## min_count X回以上でた単語を対象にする
## window 学習に使う前後の単語数 公式が5だったので・・
model = word2vec.Word2Vec(sentence, size = 100, min_count = 3, window = 5)
## モデルは名前をつけて保存
model.save(fileName+'.model' )
fileName = 'kabeModel' + str(datetime.date.today())
makeWord2VecModel(fileName)
はいモデルが完成!
ちなみに、モデル作成は1分もかからないくらいですぐできたよ。
4. モデルにいろいろ聞いてみる。
では、今作ったモデルを使って関連性が高いtop30を出してみよう。
def checkWordSimilar(fileName,word):
model = word2vec.Word2Vec.load(fileName)
try :
results = model.wv.most_similar(positive=word, topn = 30)
print("有吉の壁の[{}]とは..".format(word))
for i,result in enumerate(results):
print ( i+1 ,' [', result[0] ,'] : スコア=' , result[1])
except KeyError as error:
print(error);
fileName = 'kabeModel' + str(datetime.date.today())
checkWordSimilar(fileName+'.model', XX-調べたいワード-XX)
有吉の壁の「すき」とは・・
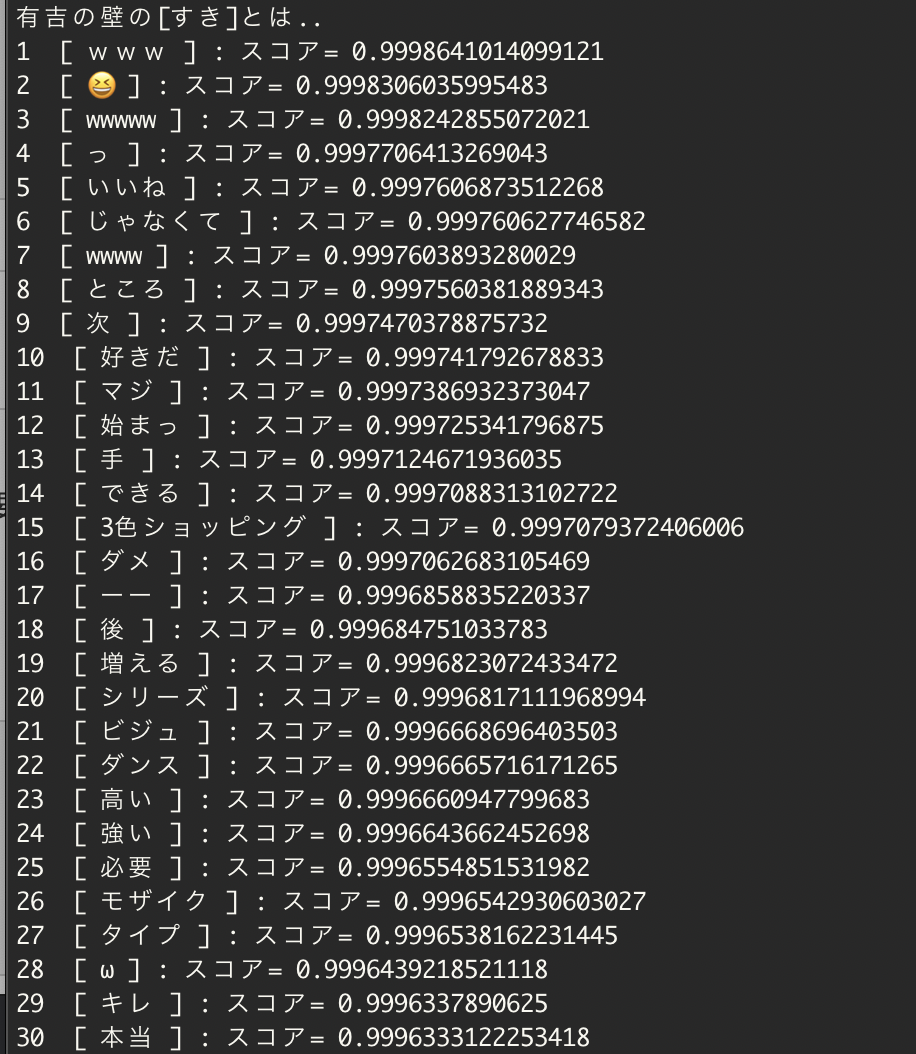
三色ショッピングは四千頭身さんだね。多分モザイクも・・。
ビジュとダンスはKOUGU維新と見た。
もっと顕著なのは、こちら
有吉の壁の「推し」とは・・

紙やすり人気ぽいね。
![]() 的にはかたまり氏のダンスのすっとこどっこい感がおもしろすぎて、GIFにして疲れた時にずっと見ていたいよ。
的にはかたまり氏のダンスのすっとこどっこい感がおもしろすぎて、GIFにして疲れた時にずっと見ていたいよ。
大本命 有吉の壁の「おもしろい」とは・・
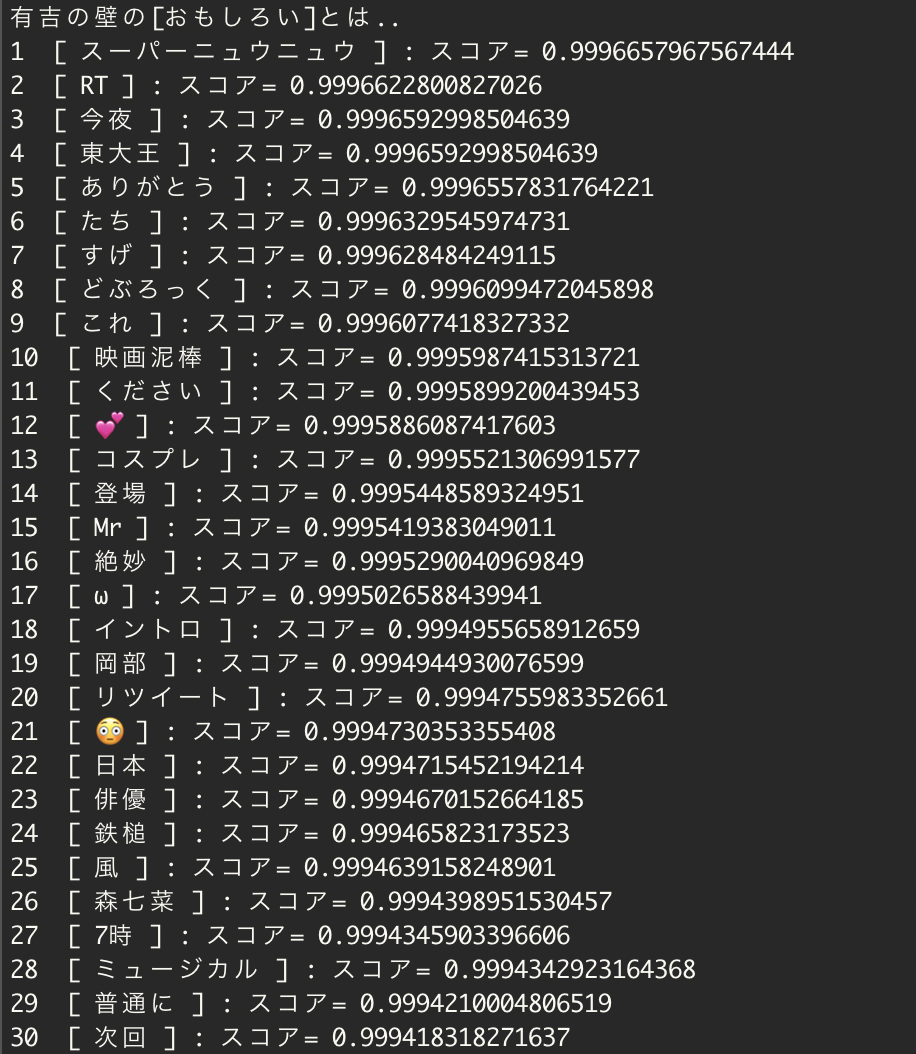
スーパーニュウニュウ !!!!!
どぶろっく
映画泥棒(トムブラウンさんのことかな)
ここまで綺麗に芸人さんの名前が出るとは思っていなかったよね・・。
データの取得の仕方やモデルのチューニングなど至らぬ点は多々あるとは思いますが、
それっぽい回答が返ってきて、テンションが上がったよ![]()
ちなみに、先週のツイートで試した時は、さらば青春の光から「森田」さんだけランクインしていたよ。
相方さんはどうしたんだろうね?
最後に、 有吉の壁にとって「壁」とは・・


よかったね安村さん![]()
最後に
word2vecを使ってTweetをもとにモデルを作成し、関連ワードを教えてもらったよ。
ちょうど前回の放送から一週間分のTweetをもとにしているので、先週の反響がそのまま影響してきたようだね。
来週も同じタイミングでデータを取得したらおもしろそうだな!と思っているよ。![]()
チューニングの仕方とか、データの前処理とか、見様見真似でやっているのでアドバイスいただけると嬉しいです。
誤りがあればご指摘ください。
参考にさせていただいたサイト
データの前処理パートも含め、すごく参考になりました。ありがとうございます。
B'zの歌詞をPythonと機械学習で分析してみた 〜Word 2 Vec編〜
ユーザー辞書の作成時+追加時にお世話になりました。
公式:Mecab