はじめに
こんにちは。先日、とある企業のとあるリードテックの方とお話しする機会がありました。今までにない切り口で質問いただいたり、すごく勉強にも気づきにもなって楽しくて、あの話もしたかったなとか、今までにない感情がわきました ![]()
あぁいうのって、話術っていうんですかね ![]() すごかったです
すごかったです ![]()
さて、今回はLambdaを使ってSeleniumによるスクレイピングを行っていこうと思います。
私は、GoogleAppsScriptをよく使うので、簡単はものはそれでいいのですが、ちゃんとしたテストをするには、Selenium等使うべきだとは思います ![]()
HerokuにLaravel入れてSelenium使おうとかも思ったのですが、せっかくなので、今まで触ったことないものに挑戦しようと、今回の運びになりました。
LambdaもPythonも使ったことないので、同じく初心者の方にやさしい記事になると思います。
参考になれば幸いです ![]()
前提条件
- Windows 10 Pro
- WSL2 (20.04.2 LTS (Focal Fossa))
- Python3 インストール済み
- pipインストール済み
方針
- 必要なライブラリをダウンロード
- Lambdaレイヤー用のzipファイル作成
- Lambdaレイヤーに2をアップロード
- Lambda関数作成
- Lambdaレイヤー追加
- 関数にプログラムを書く
- デプロイ
- 設定変更
- テスト
Lambda関数でPythonとSelenium使ってサーバレスでスクレイピングする
1. 必要なライブラリをダウンロード
ダウンロードするのは以下3つ。
ここで、chromiumとchromedriverは最新版を使用すると後続でLambdaレイヤーアップロード時にサイズがでかくてS3に置いてくれって怒られるので、あえて古めを採用![]()
- selenium
- chromium
- chromedriver
フォルダ構造はこんな感じ
$ tree -L 5
.
├── headless
│ └── python
│ └── bin
│ ├── chromedriver
│ └── headless-chromium
└── python
└── lib
└── python3.8
└── site-packages
├── selenium
├── selenium-3.141.0.dist-info
├── urllib3
└── urllib3-1.26.6.dist-info
1.1. selenium
$ pip install selenium -t python/lib/python3.8/site-packages
1.2. chromium
$ curl -SL https://github.com/adieuadieu/serverless-chrome/releases/download/v1.0.0-37/stable-headless-chromium-amazonlinux-2017-03.zip > headless-chromium.zip
$ unzip -o headless-chromium.zip -d .
$ rm headless-chromium.zip
1.3. chromedriver
$ curl -SL https://chromedriver.storage.googleapis.com/2.37/chromedriver_linux64.zip > chromedriver.zip
$ unzip -o chromedriver.zip -d .
$ rm chromedriver.zip
2. Lambdaレイヤー用のzipファイル作成
以下のようにheadlessフォルダとpythonフォルダをzip圧縮します。
$ tree-L 5
.
├── headless
│ └── python
│ └── bin
│ ├── chromedriver
│ └── headless-chromium
├── headless.zip
├── python
│ └── lib
│ └── python3.8
│ └── site-packages
│ ├── selenium
│ ├── selenium-3.141.0.dist-info
│ ├── urllib3
│ └── urllib3-1.26.6.dist-info
└── python.zip
3. Lambdaレイヤーに2をアップロード
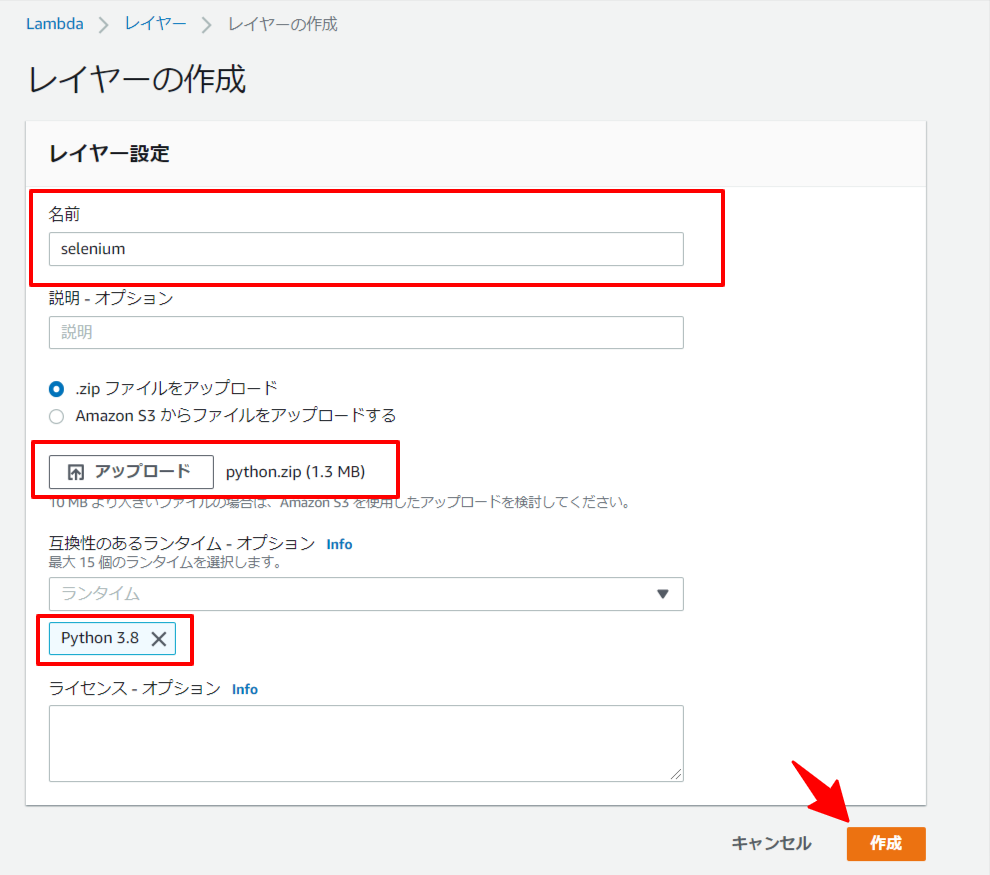
3.1. Selenium
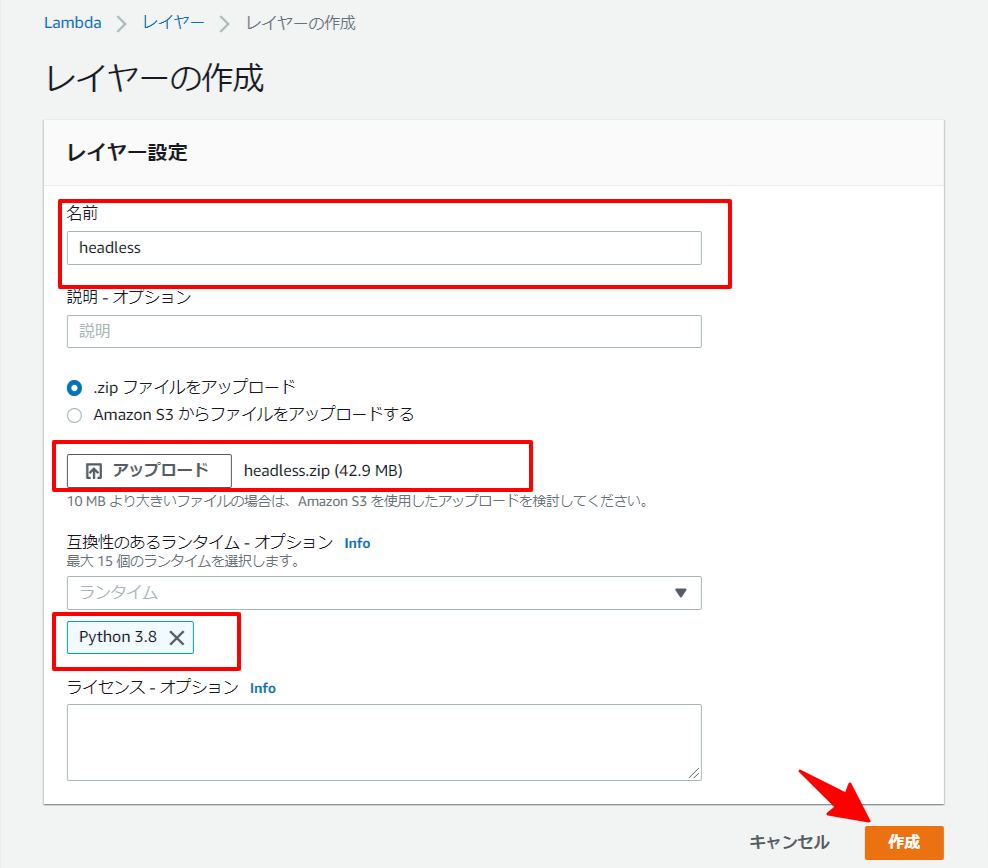
3.2. chromium, chromedriver
先にふれたとおり、ここで50MBを超えるとS3にアップロードしないとだめなので、旧バージョンを使用して乗り切ります ![]()
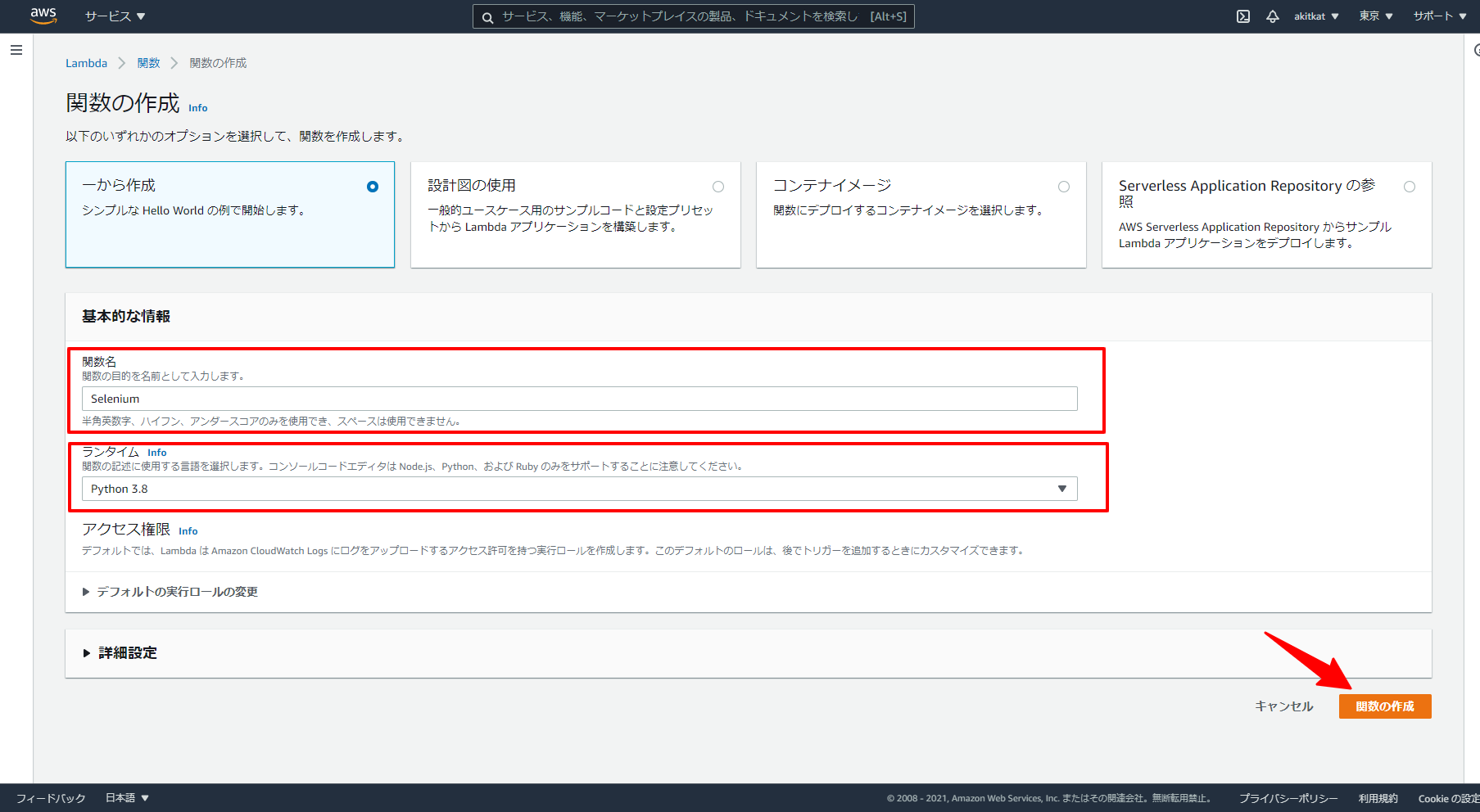
4. Lambda関数作成
5. Lambdaレイヤー追加
4で作成した関数のページ下部で追加できるので、追加します![]()
6. 関数にプログラムを書く
https://example.com/ のタイトルを取得しようと思います。
from selenium import webdriver
def lambda_handler(event, context):
URL = "https://example.com/"
options = webdriver.ChromeOptions()
options.binary_location = "/opt/headless/python/bin/headless-chromium"
options.add_argument("--headless")
options.add_argument("--disable-gpu")
options.add_argument("--hide-scrollbars")
options.add_argument("--single-process")
options.add_argument("--ignore-certificate-errors")
options.add_argument("--window-size=880x996")
options.add_argument("--no-sandbox")
options.add_argument("--homedir=/tmp")
browser = webdriver.Chrome(
executable_path="/opt/headless/python/bin/chromedriver",
options=options
)
browser.get(URL)
title = browser.title
browser.close()
return title
7. デプロイ
Deploy ボタンがあるのでそれを押下します。
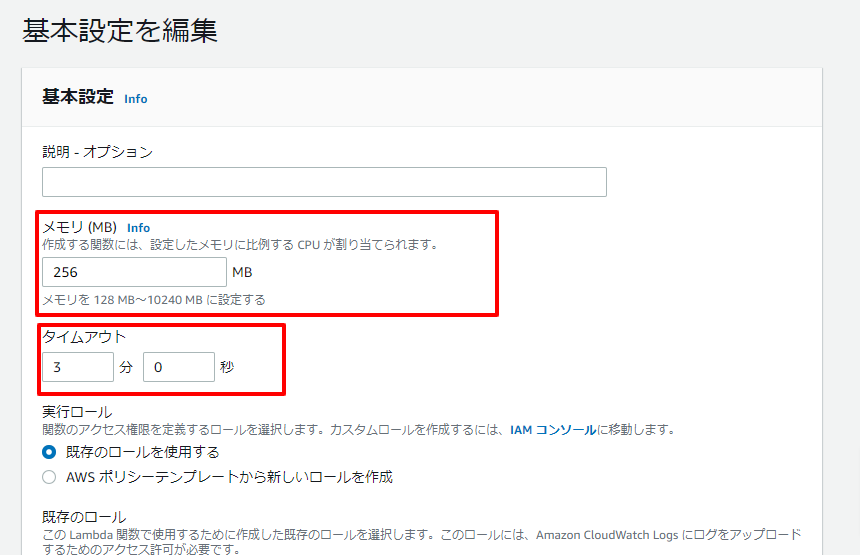
8. 設定変更
メモリが不足する場合があるらしいので256まで上げます。
あと、実行に時間がかかるため、タイムアウトの時間も増やします。
9. テスト
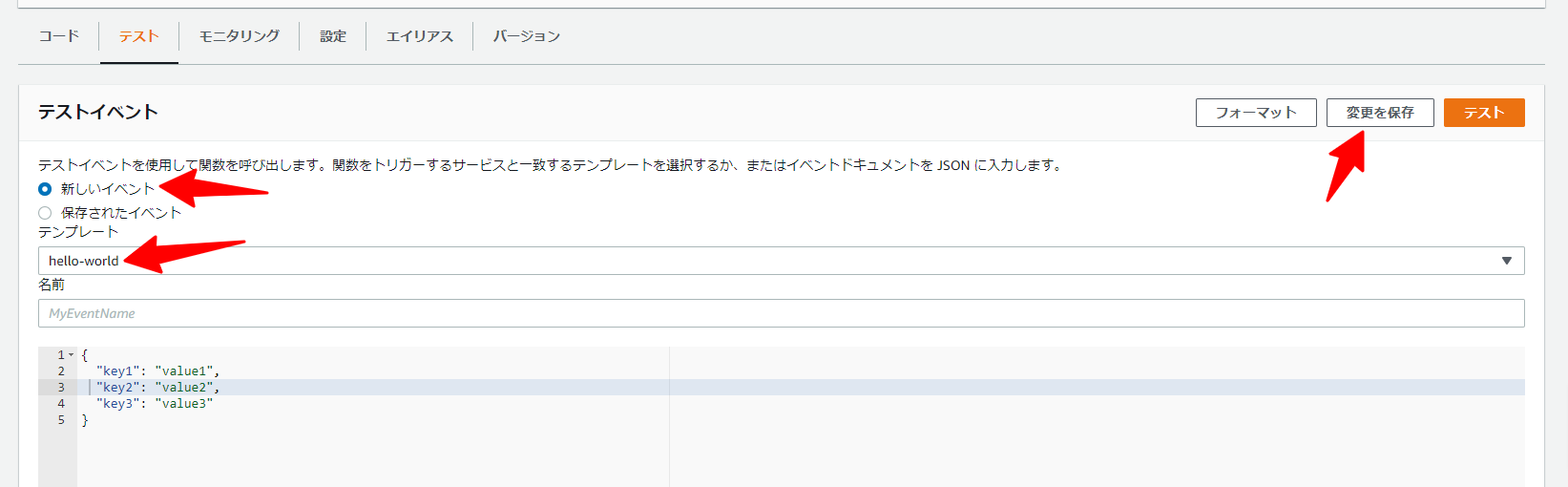
まず、テストイベントの作成を行います。
テストタブに移動し、新しいイベントでテンプレート: hello-worldを選択して保存します。
実行結果が以下と表示されればOKです ![]()
Response
"Example Domain"
おわりに
いろいろほかの方の記事とか見ながら進めていましたが、いかんせん一筋縄ではいかなかったです![]()
パスが通らなかったり、ファイルがでかかったり、デプロイしないとテストできなかったり、いろいろ記事読んでそちらに書いてない部分をこの記事で補えればと思います![]()
それでは![]()
参考にさせていただいた記事
以下記事を参考にさせていただきました。ありがとうございました![]()
トラブルシューティングの際はこちらも併せてご参照くださいませ![]()