Summary
- arXivのAPIのRustラッパーを実装しました
- 既存のライブラリはいくつか存在しますが,今回の用途に合わせてがっつり車輪を再発明します
- XMLのパースは最終的に
quick_xmlが楽
- GiHub -> https://github.com/akitenkrad/rsrpp
- crates.io
- rsrpp -> https://crates.io/crates/rsrpp
- arxiv-tools -> https://crates.io/crates/arxiv-tools
前回までのあらすじ
arXiv論文収集システムの全体像と簡単な要件の確認を行いました.
今回は①arXivからの論文スクレイピングに着手します.
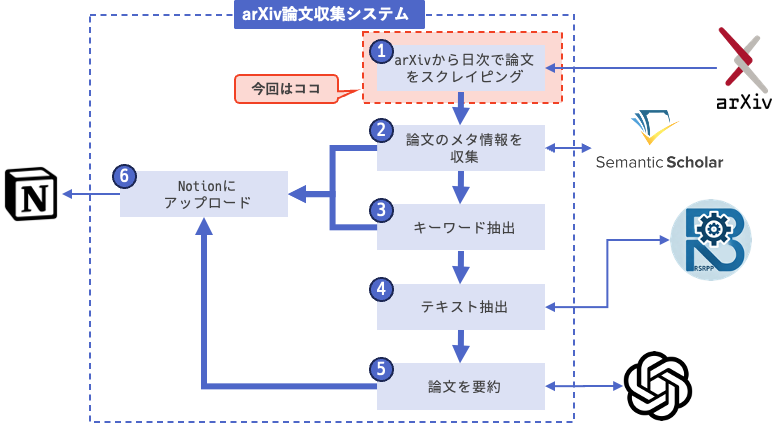
実装すること
まずは,arXivから論文の情報を取得するためのAPIのラッパーを実装します.
arXivはAPIが整備されており,特定のパラメータを持たせてURLを叩くだけで論文の情報を簡単に取得できるようになっています ( arXiv API Access ).
例えば,2024年12月13日にアップロードされた cs.AI カテゴリの論文を検索する場合は以下のようなURLを叩くことになります.
https://export.arxiv.org/api/query?search_query=cat:cs.AI&submittedDate=[202412120000To202412122359]
リクエストの結果は下記のようにAtom-1.0形式のXMLで返ってきます.
<?xml version="1.0" encoding="UTF-8"?>
<feed xmlns="http://www.w3.org/2005/Atom">
<link href="http://arxiv.org/api/query?search_query%3Dcat%3Acs.AI%26id_list%3D%26start%3D0%26max_results%3D10" rel="self" type="application/atom+xml"/>
<title type="html">ArXiv Query: search_query=cat:cs.AI&id_list=&start=0&max_results=10</title>
<id>http://arxiv.org/api/xn611ryeCDnDvmVYOJ6SWZuh1qk</id>
<updated>2024-12-13T00:00:00-05:00</updated>
<opensearch:totalResults xmlns:opensearch="http://a9.com/-/spec/opensearch/1.1/">109616</opensearch:totalResults>
<opensearch:startIndex xmlns:opensearch="http://a9.com/-/spec/opensearch/1.1/">0</opensearch:startIndex>
<opensearch:itemsPerPage xmlns:opensearch="http://a9.com/-/spec/opensearch/1.1/">10</opensearch:itemsPerPage>
<entry>
<id>http://arxiv.org/abs/cs/9308101v1</id>
<updated>1993-08-01T00:00:00Z</updated>
<published>1993-08-01T00:00:00Z</published>
<title>Dynamic Backtracking</title>
<summary> Because of their occasional need to return to shallow points in a search
tree, existing backtracking methods can sometimes erase meaningful progress
toward solving a search problem. In this paper, we present a method by which
backtrack points can be moved deeper in the search space, thereby avoiding this
difficulty. The technique developed is a variant of dependency-directed
backtracking that uses only polynomial space while still providing useful
control information and retaining the completeness guarantees provided by
earlier approaches.
</summary>
<author>
<name>M. L. Ginsberg</name>
</author>
<arxiv:comment xmlns:arxiv="http://arxiv.org/schemas/atom">See http://www.jair.org/ for an online appendix and other files
accompanying this article</arxiv:comment>
<arxiv:journal_ref xmlns:arxiv="http://arxiv.org/schemas/atom">Journal of Artificial Intelligence Research, Vol 1, (1993), 25-46</arxiv:journal_ref>
<link href="http://arxiv.org/abs/cs/9308101v1" rel="alternate" type="text/html"/>
<link title="pdf" href="http://arxiv.org/pdf/cs/9308101v1" rel="related" type="application/pdf"/>
<arxiv:primary_category xmlns:arxiv="http://arxiv.org/schemas/atom" term="cs.AI" scheme="http://arxiv.org/schemas/atom"/>
<category term="cs.AI" scheme="http://arxiv.org/schemas/atom"/>
</entry>
<entry>
<id>http://arxiv.org/abs/cs/9308102v1</id>
<updated>1993-08-01T00:00:00Z</updated>
<published>1993-08-01T00:00:00Z</published>
<title>A Market-Oriented Programming Environment and its Application to
Distributed Multicommodity Flow Problems</title>
<summary> Market price systems constitute a well-understood class of mechanisms that
under certain conditions provide effective decentralization of decision making
with minimal communication overhead. In a market-oriented programming approach
to distributed problem solving, we derive the activities and resource
allocations for a set of computational agents by computing the competitive
equilibrium of an artificial economy. WALRAS provides basic constructs for
defining computational market structures, and protocols for deriving their
corresponding price equilibria. In a particular realization of this approach
for a form of multicommodity flow problem, we see that careful construction of
the decision process according to economic principles can lead to efficient
distributed resource allocation, and that the behavior of the system can be
meaningfully analyzed in economic terms.
</summary>
<author>
<name>M. P. Wellman</name>
</author>
<arxiv:comment xmlns:arxiv="http://arxiv.org/schemas/atom">See http://www.jair.org/ for any accompanying files</arxiv:comment>
<arxiv:journal_ref xmlns:arxiv="http://arxiv.org/schemas/atom">Journal of Artificial Intelligence Research, Vol 1, (1993), 1-23</arxiv:journal_ref>
<link href="http://arxiv.org/abs/cs/9308102v1" rel="alternate" type="text/html"/>
<link title="pdf" href="http://arxiv.org/pdf/cs/9308102v1" rel="related" type="application/pdf"/>
<arxiv:primary_category xmlns:arxiv="http://arxiv.org/schemas/atom" term="cs.AI" scheme="http://arxiv.org/schemas/atom"/>
<category term="cs.AI" scheme="http://arxiv.org/schemas/atom"/>
</entry>
...
</feed>
今回は,このAPIをRustから簡単に叩けるようにするためのラッパーライブラリの土台を実装します.
完成系としては,以下のような形で簡単にクエリを組み立てて実行できるようにしたいです.
let mut arxiv = ArXiv::new();
arxiv
.subject_category("cs.AI")
.or()
.subject_category("cs.LG")
.submitted_date("202412120000", "202412122359");
// execute
let response = arxiv.query().await;
実は,arXiv APIのラッパーライブラリはすでにいくつかクレートが存在していて,デファクトっぽいものもあるのですが,今回は自分専用のクレートを実装することにします.
理由は単純に車輪の再発明を楽しみたいということと,既存のクレートはすでに長期間手が入っておらず,今後も依存して良いものかどうか判断しかねたためです.
arxiv-tools → クレート / GitHub
今回中心になるのはarXivのクエリを組み立てるためのArXiv構造体です.
pub struct ArXiv {
pub url: String,
pub base_url: String,
pub args: Vec<ArXivArgs>,
}
impl ArXiv {
pub fn new() -> Self {
return ArXiv {
base_url: "http://export.arxiv.org/api/query?search_query=".to_string(),
url: "".to_string(),
args: Vec::new(),
};
}
}
パラメータの実装
argsにユーザが指定したパラメータを格納するようにし,最終的なリクエスト用のURLをurlに格納します.
ユーザが指定できるパラメータはArXivArgsに定義しています.
pub enum ArXivArgs {
Title(String),
Author(String),
Abstract(String),
Comment(String),
JournalRef(String),
SubjectCategory(String),
ReportNumber(String),
SubmittedDate(String),
Id(String),
All(String),
And(String),
Or(String),
AndNot(String),
GroupStart(String),
GroupEnd(String),
}
enumを使って実装してみました.ユーザが指定できるのは,タイトルや著者等のテキストと,条件を組み合わせるための演算子,あとは期間を指定するためのSubmittedDateです.
resultなど一度に取得する件数を指定するパラメータもあるので,今後アップデートします.
Title(String)のようになっているのは,Stringにパラメータの文字列を格納するためです.Rustのenumは各要素に指定した型のデータを渡すことができるので,今回はそれを利用しました.
オブジェクトを生成するときは,以下のようにコンストラクタを経由します.
impl ArXivArgs {
pub fn title(arg: String) -> Self {
return ArXivArgs::Title(encode(&format!("ti:\"{}\"", arg)));
}
}
arXivのAPIではタイトルは ti:XXXXX のように指定する仕様になっているので,コンストラクタで内部的にパラメータの文字列を保持するようにしています.
encode() は文字列をURLエンコードする関数で,以下のようなエンコードを実行します.
| symbol | encoding |
|---|---|
| () | %28%29 |
| double quotes | %22%22 |
| space | + |
このコンストラクタをパラメータの数の分だけ実装しています.
impl ArXivArgs {
pub fn title(arg: String) -> Self {
return ArXivArgs::Title(encode(&format!("ti:\"{}\"", arg)));
}
pub fn author(arg: String) -> Self {
return ArXivArgs::Author(encode(&format!("au:\"{}\"", arg)));
}
pub fn abstract_text(arg: String) -> Self {
return ArXivArgs::Abstract(encode(&format!("abs:\"{}\"", arg)));
}
pub fn comment(arg: String) -> Self {
return ArXivArgs::Comment(encode(&format!("co:\"{}\"", arg)));
}
pub fn journal_ref(arg: String) -> Self {
return ArXivArgs::JournalRef(encode(&format!("jr:\"{}\"", arg)));
}
pub fn subject_category(arg: String) -> Self {
return ArXivArgs::SubjectCategory(encode(&format!("cat:\"{}\"", arg)));
}
pub fn report_number(arg: String) -> Self {
return ArXivArgs::ReportNumber(encode(&format!("rn:\"{}\"", arg)));
}
pub fn id(id: String) -> Self {
return ArXivArgs::Id(encode(&format!("id:\"{}\"", id)));
}
pub fn all(arg: String) -> Self {
return ArXivArgs::All(encode(&format!("all:\"{}\"", arg)));
}
pub fn submitted_date(arg_from: String, arg_to: String) -> Self {
return ArXivArgs::SubmittedDate(format!("&submittedDate:[{}+TO+{}]", arg_from, arg_to));
}
pub fn and() -> Self {
return ArXivArgs::And(encode(" AND "));
}
pub fn or() -> Self {
return ArXivArgs::Or(encode(" OR "));
}
pub fn and_not() -> Self {
return ArXivArgs::AndNot(encode(" ANDNOT "));
}
pub fn group_start() -> Self {
return ArXivArgs::GroupStart(encode("("));
}
pub fn group_end() -> Self {
return ArXivArgs::GroupEnd(encode(")"));
}
}
ArXiv構造体からは,同じようにArXiv::title()関数を呼び出すことによってargsにパラメータを追加するようにし,関数の戻り値として自分自身を返すことによって関数をチェインできるようにしています.
impl ArXiv {
...
pub fn title(&mut self, title: &str) -> &mut Self {
self.args.push(ArXivArgs::title(title.to_string()));
return self;
}
...
}
レスポンスの実装
クエリの結果はXMLで返ってくるので,XMLをパースして論文の情報を保持する構造体 ArXivResponse を定義します.
#[derive(Debug, Clone, Serialize, Deserialize)]
pub struct ArXivResponse {
pub id: String,
pub title: String,
pub authors: Vec<String>,
#[serde(rename = "abstract")]
pub abstract_text: String,
pub published: String,
pub updated: String,
pub doi: String,
pub comment: Vec<String>,
pub journal_ref: String,
pub pdf_url: String,
pub primary_category: String,
pub categories: Vec<String>,
}
こちらはJSONにシリアライズできるようにしておきます.
abstractは予約語になっているので,内部では別の名前で保持しておき,JSONにシリアライズ/JSONからデシリアライズするときに名称を変更するように設定しておきます.
XMLのパースは quick_xml を使用しました.
初めは scraperを使って簡単に処理する方針だったのですが,categoryやprimary_categoryなど一部のXML要素が謎の入れ子になっていたりして scraperでは扱いきれなかったので,quick_xmlの低レイヤの処理で全て済ませる方針に転換しました.
コードは少々長くなってしまいましたが,結果的にこちらの方がスッキリして見えます (個人の感想です).
quick_xmlを使ったXMLのパースはコードが少々複雑になりがちですが,大きなXMLが流れてきても処理が高速であることと,低レイヤの処理であることから非常に自由度が高いことが良いところです.
fn parse_xml(&self, xml: String) -> Vec<ArXivResponse> {
let mut reader = Reader::from_str(&xml);
let mut buf = Vec::new();
let mut in_entry = false;
let mut in_id = false;
let mut in_title = false;
let mut in_author = false;
let mut in_name = false;
let mut in_abstract = false;
let mut in_published = false;
let mut in_updated = false;
let mut in_comment = false;
let mut in_journal_ref = false;
let mut responses: Vec<ArXivResponse> = Vec::new();
let mut res = ArXivResponse::default();
loop {
match reader.read_event_into(&mut buf) {
Ok(Event::Start(ref e)) => {
if e.name().as_ref() == b"entry" {
in_entry = true;
res = ArXivResponse::default();
} else if e.name().as_ref() == b"id" {
in_id = true;
} else if e.name().as_ref() == b"title" {
in_title = true;
} else if e.name().as_ref() == b"author" {
in_author = true;
} else if e.name().as_ref() == b"name" {
if in_author {
in_name = true;
}
} else if e.name().as_ref() == b"summary" {
in_abstract = true;
} else if e.name().as_ref() == b"published" {
in_published = true;
} else if e.name().as_ref() == b"updated" {
in_updated = true;
} else if e.name().as_ref() == b"arxiv:comment" {
in_comment = true;
} else if e.name().as_ref() == b"arxiv:journal_ref" {
in_journal_ref = true;
} else if e.name().as_ref() == b"link" && in_entry {
let mut is_pdf = false;
let mut is_doi = false;
e.attributes().for_each(|attr| {
if let Ok(attr) = attr {
if attr.key.as_ref() == b"title" && attr.value.as_ref() == b"pdf" {
is_pdf = true;
} else if attr.key.as_ref() == b"title"
&& attr.value.as_ref() == b"doi"
{
is_doi = true;
}
}
});
e.attributes().for_each(|attr| {
if let Ok(attr) = attr {
if attr.key.as_ref() == b"href" {
if is_pdf {
res.pdf_url = String::from_utf8_lossy(attr.value.as_ref())
.to_string();
} else if is_doi {
res.doi = String::from_utf8_lossy(attr.value.as_ref())
.to_string();
}
}
}
});
} else if e.name().as_ref() == b"arxiv:primary_category" {
e.attributes().for_each(|attr| {
if let Ok(attr) = attr {
if attr.key.as_ref() == b"term" {
res.primary_category =
String::from_utf8_lossy(attr.value.as_ref()).to_string();
}
}
});
} else if e.name().as_ref() == b"category" {
if let Some(attr) = e
.attributes()
.find(|attr| attr.as_ref().unwrap().key.as_ref() == b"term")
{
res.categories.push(
String::from_utf8_lossy(attr.unwrap().value.as_ref()).to_string(),
);
}
} else if e.name().as_ref() == b"category" {
if let Some(attr) = e
.attributes()
.find(|attr| attr.as_ref().unwrap().key.as_ref() == b"term")
{
res.categories.push(
String::from_utf8_lossy(attr.unwrap().value.as_ref()).to_string(),
);
}
}
}
Ok(Event::End(ref e)) => {
if e.name().as_ref() == b"entry" {
in_entry = false;
responses.push(res.clone());
res = ArXivResponse::default();
} else if e.name().as_ref() == b"id" {
in_id = false;
} else if e.name().as_ref() == b"title" {
in_title = false;
} else if e.name().as_ref() == b"author" {
in_author = false;
} else if e.name().as_ref() == b"name" {
if in_author {
in_name = false;
}
} else if e.name().as_ref() == b"summary" {
in_abstract = false;
} else if e.name().as_ref() == b"published" {
in_published = false;
} else if e.name().as_ref() == b"updated" {
in_updated = false;
} else if e.name().as_ref() == b"arxiv:comment" {
in_comment = false;
} else if e.name().as_ref() == b"arxiv:journal_ref" {
in_journal_ref = true;
}
}
Ok(Event::Text(e)) => {
if in_entry {
if in_id {
res.id = e.unescape().unwrap().to_string();
} else if in_title {
res.title = e.unescape().unwrap().to_string();
} else if in_author && in_name {
res.authors.push(e.unescape().unwrap().to_string());
} else if in_abstract {
res.abstract_text =
e.unescape().unwrap().to_string().trim().replace("\n", "");
} else if in_published {
res.published = e.unescape().unwrap().to_string();
} else if in_updated {
res.updated = e.unescape().unwrap().to_string();
} else if in_comment {
res.comment.push(e.unescape().unwrap().to_string());
} else if in_journal_ref {
res.journal_ref = e.unescape().unwrap().to_string();
}
}
}
Ok(Event::Empty(ref e)) => {
if e.name().as_ref() == b"link" && in_entry {
let mut is_pdf = false;
let mut is_doi = false;
e.attributes().for_each(|attr| {
if let Ok(attr) = attr {
if attr.key.as_ref() == b"title" && attr.value.as_ref() == b"pdf" {
is_pdf = true;
} else if attr.key.as_ref() == b"title"
&& attr.value.as_ref() == b"doi"
{
is_doi = true;
}
}
});
e.attributes().for_each(|attr| {
if let Ok(attr) = attr {
if attr.key.as_ref() == b"href" {
if is_pdf {
res.pdf_url = String::from_utf8_lossy(attr.value.as_ref())
.to_string();
} else if is_doi {
res.doi = String::from_utf8_lossy(attr.value.as_ref())
.to_string();
}
}
}
});
} else if e.name().as_ref() == b"arxiv:primary_category" && in_entry {
e.attributes().for_each(|attr| {
if let Ok(attr) = attr {
if attr.key.as_ref() == b"term" {
res.primary_category =
String::from_utf8_lossy(attr.value.as_ref()).to_string();
}
}
});
} else if e.name().as_ref() == b"category" && in_entry {
if let Some(attr) = e
.attributes()
.find(|attr| attr.as_ref().unwrap().key.as_ref() == b"term")
{
res.categories.push(
String::from_utf8_lossy(attr.unwrap().value.as_ref()).to_string(),
);
}
}
}
Ok(Event::Eof) => break,
Err(e) => panic!("Error at position {}: {:?}", reader.buffer_position(), e),
_ => (),
}
buf.clear();
}
return responses;
}
クエリの実行
クエリの実行自体はとてもシンプルです.
argsに格納されているパラメータから順に内部テキストを取り出して連結し,request::getするだけです.
(requestクレートは,本来はreqwestという名称なのですが,毎回タイポするので use reqwest as requestにして使っています)
pub async fn query(&mut self) -> Vec<ArXivResponse> {
let mut query = "".to_string();
for arg in &self.args {
match arg {
ArXivArgs::Title(arg) => query.push_str(&arg),
ArXivArgs::Author(arg) => query.push_str(&arg),
ArXivArgs::Abstract(arg) => query.push_str(&arg),
ArXivArgs::Comment(arg) => query.push_str(&arg),
ArXivArgs::JournalRef(arg) => query.push_str(&arg),
ArXivArgs::SubjectCategory(arg) => query.push_str(&arg),
ArXivArgs::ReportNumber(arg) => query.push_str(&arg),
ArXivArgs::SubmittedDate(arg) => query.push_str(&arg),
ArXivArgs::Id(arg) => query.push_str(&arg),
ArXivArgs::All(arg) => query.push_str(&arg),
ArXivArgs::And(arg) => query.push_str(&arg),
ArXivArgs::Or(arg) => query.push_str(&arg),
ArXivArgs::AndNot(arg) => query.push_str(&arg),
ArXivArgs::GroupStart(arg) => query.push_str(&arg),
ArXivArgs::GroupEnd(arg) => query.push_str(&arg),
}
}
self.url = format!(
"{}{}&sortBy=lastUpdatedDate&sortOrder=descending",
self.base_url, query,
);
self.url = self.url.replace("%20", "+");
let body = request::get(&self.url).await.unwrap().text().await.unwrap();
let responses = self.parse_xml(body);
return responses;
}
以上で,arXivの基礎的なAPIを叩くことができるようになります.
再掲ですが,以下のように簡単にパラメータを組み立ててクエリを投げることができるようになりました.
let mut arxiv = ArXiv::new();
arxiv
.subject_category("cs.AI")
.or()
.subject_category("cs.LG")
.submitted_date("202412120000", "202412122359");
// execute
let response = arxiv.query().await;
今回のシステムでは,日時を指定して特定のカテゴリの論文のリストをとってくる必要があるので,上記のコードをほぼそのまま使用することになります.
(というか,そうなるようにクレートを作りました)
これでarXiv APIの基本機能はつけるようになったので,あとは今後必要に応じてクレートを拡張していくことにします.
次回
次回は同じく論文情報を収集できるSemanticScholarのAPIラッパーを実装します.