「Google Cloud Platform その2 Advent Calendar 2018 - Qiita」の20日目の記事です。
はじめに
Google App Engine (GAE) は、 Google Cloud で提供されている PaaS (Platform as a Service) です。Webアプリケーションを実装する上でのサポートが手厚く、日々の無料枠も一定度あることから、様々な場面で利用しています。
今回は、異なるクラウドストレージ間 (Google Drive と Google Cloud Storage) で大容量ファイルを転送する処理をGoogle App Engineで実現する際にハマったことと、その対策例を紹介します。
Google Drive から大容量のファイルをダウンロードする
Google Drive から大容量ファイルをダウンロードする際には、Download Files | Drive REST API | Google Developersに記載されている、 googleapiclient.http.MediaIoBaseDownload - GitHub などを利用することで、チャンク単位で順次ダウンロードを行うことができます。
file_id = '1ZdR3L3qP4Bkq8noWLJHSr_iBau0DNT4Kli4SxNc2YEo'
request = drive_service.files().export_media(fileId=file_id,
mimeType='application/pdf')
fh = io.BytesIO()
downloader = MediaIoBaseDownload(fh, request)
done = False
while done is False:
status, done = downloader.next_chunk()
print "Download %d%%." % int(status.progress() * 100)
MediaIoBaseDownload は、ダウンロード対象ファイルを chunk_size ごとに分割して順次ダウンロードを行います。ダウンロードした内容は、 fd (File Descriptor) に順に追記していくことで、メモリ使用量を抑える仕組みとなっています。
一般的な仮想マシン環境であれば、この方法で問題なく動作しますが、 Google App Engine の 2nd generation で利用可能なファイルシステムはメモリ上に配置されるため、書き込み可能なファイルサイズは、インスタンスのメモリサイズに依存することになります。GAEの F1 インスタンスであれば利用可能なメモリは128MBに限定されます。アプリケーション本体が必要とするメモリもあるため、100MBを超えるファイルのダウンロードは難しいでしょう。
Python 3 Runtime Environment | App Engine standard environment for Python 3 docs | Google Cloud
The runtime includes a full filesystem. The filesystem is read-only except for the location /tmp, which is a virtual disk storing data in your App Engine instance's RAM.
Google App Engine で クラウドストレージ間でのファイルコピーを実現する
Google App Engine のインスタンスには、大容量のファイルを保存できないことを説明しました。この制約の中で、Google App Engine を使ってクラウドストレージ間のファイルコピーを実現するためのアプローチを説明します。
google-api-python-client に実装されている MediaIoBaseDownload は、単一ファイルに順次追記しながらダウンロードを行います。チャンクごとにダウンロードを行うアプローチはそのままに、チャンク単位で書き出すファイルを分割することで、同時に利用するメモリ容量を削減するアプローチを取りました。
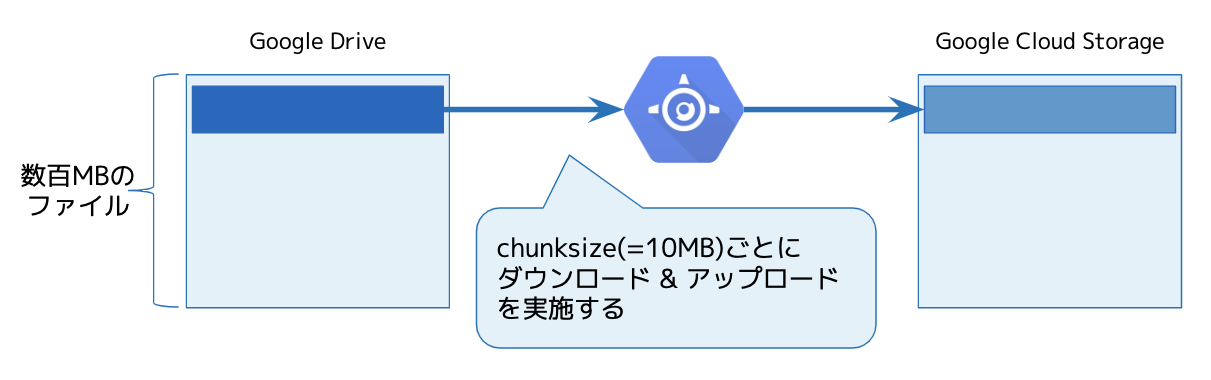
この時の処理イメージは以下のようなコードになります。
downloader = ... # Google Drive 上のファイル・コンテンツのダウンロード処理を担うオブジェクト
uploader = ... # Google Cloud Storage に対してファイル・コンテンツのアップロード処理を担うオブジェクト
done = False
# downloader がファイル末尾に達するまで繰り返す
while done is False:
# チャンク毎に、ダウンロードした内容を書き出す temporary file を作成する
with tempfile.NamedTemporaryFile() as fd:
# 次のチャンクをダウンロードして、 fd に書き込む
progress = downloader.fetch_next_chunk(fd=fd)
done = progress.done
# fd の先頭に巻き戻して、ダウンロードした内容を読み込む
fd.seek(0)
payload = fd.read()
# uploader にダウンロードしたチャンクを渡して、続きをアップロードする
uploader.upload_next_chunk(
payload=payload,
chunk_size=len(payload)
)
このように、あるタイミングでGoogle App Engineのインスタンス上に記録されるデータ量を任意のチャンクサイズに制限することによって、インスタンスのメモリ容量による制限を受けない形に実現できました。
ハマったところ
Google Cloud Storage の Resumable Upload は、 256KB 単位で書き込む必要があります。
JSON API: Performing a Resumable Upload | Cloud Storage | Google Cloud
Add the chunk's data to the request body. Create chunks in multiples of 256 KB (256 x 1024 bytes) in size, except for the final chunk that completes the upload. Keep the chunk size as large as possible so that the upload is efficient.
256KBよりも1バイト余分に書き込みをすると、 256KBブロック2つ分書き進むことになって、ファイルサイズ・内容の不一致状態になってしまいます。
参考コード
今回の課題を解決するにあたって実装したコード(を一部抜粋したもの)はGitHub akiray03/gdrive-to-gcs-streaming-copy-pyにありますので、よければ参考にしてください ![]()