この記事はCrowdWorks Advent Calendar 2016 の24日目の記事です。CrowdWorksのエンジニアが毎日なにかを書きます。
昨日の記事は @suzan2go による「ラーメン屋で考えるRailsのデータモデリング」でした。
はじめに
CrowdWorksは、2011年の創業以来、約5年間の開発を続けてきました。サービスの立ち上げ期においては、サービスの継続性・変更容易性を高めることよりも、サービスを成長させ、存続に繋がるフェースまで素早く立ち上げることが最重要な観点です。
一方で、サービス提供も5年が経過し、多くの方にご利用頂く「社会インフラ」に一歩ずつ近づいてきています。そういった環境の変化もあり、「日々改善し続ける」「日々変更し続ける」ことに重要視する観点が移り変わってきました。そのような価値観の変遷に取り組む過程で考えている「大規模で複雑な業務要件を担うRailsアプリケーションとの付き合い方」の一面を紹介します。
SQLアンチパターン: Polymorphic を使わない
Railsでは簡単に Polymorphic Association を作れてしまいますが、 SQLアンチパターン 6章 にも書かれているとおり使うべきではありません。使うべきでない理由をRailsの例を使って書いてみます。
BlogEntryとPressReleaseという2つのモデルに対して「複数のコメントを投稿できる」という機能を考えた時、以下のようなデータ構造を作ったとしましょう。
class BlogEntry
has_many :comments, as: :commentable
end
class PressRelease
has_many :comments, as: :commentable
end
class Comment
# commentable_type, commentable_id カラムを持っている
belongs_to :commentable, polymorphic: true
end
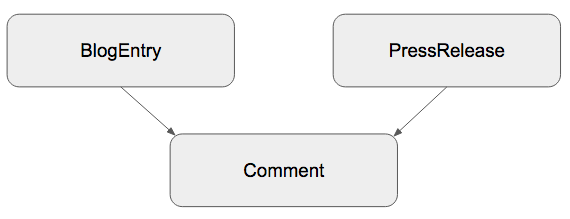
最初の段階では問題無いかもしれませんが、追加の要件として、
- PressRelease に対するコメントは、IR担当者の確認後に公開したい
- BlogEntry に対するコメントは、自動スパムフィルタを入れたい
- ...
といった内容が出てきた時に、 Comment モデル内に分岐が増え続けていくことになってしまいます。
class Comment
belongs_to :commentable, polymorphic: true
before_validates :set_published
# IR担当者が確認後に公開するときに使うメソッド
def publish!
update_attributes(published: true)
end
private
def set_published
case commentable_type
when BlogEntry.to_s
self.published = spam_check # BlogEntry の場合はスパム判定結果に応じて公開する
when PressRelease.to_s
self.published = false if new_record? # PressRelease の場合は最初は非公開にする
end
end
def spam_check
# なにかする
end
end
... サンプルコードを書いてみるだけでも疲れてきましたね。。
また、違う観点で考えてみても、
- BlogEntryのコメントは、BlogEntryに対する関心はあるが、PressReleaseに対する関心は無い
- PressReleaseのコメントは、PressReleaseに対する関心はあるが、BlogEntryに対する関心は無い
という、「関心の範囲」が異なるはずです。関心の範囲が異なるものは、別のモデルにするべきです。
似て非なるものは、同じような構造だとしても別モデルに分離しましょう。
Concern(頭痛の種)を避ける
肥大化したActiveRecordモデルをリファクタリングする7つの方法(翻訳)にも
“app/concerns ディレクトリを使っているようなアプリケーションって、だいたい後から頭痛の種になる(=concerning)んだよね”
と書かれていたりしますが、本当に頭痛の種ですね。一切使用禁止にしたい気持ちになっている今日このごろです。例を見てみましょう。
先程のBlogEntryとPressReleaseのコメントについて、引き続き考えてみます。各々のコメントを別のモデルに分けたけれど、同じような処理をまとめるためにConcernを使った...という状況を考えてみましょう。
class BlogEntry::Comment
include Commentable
belongs_to :blog_entry
end
class PressRelease::Comment
include Commentable
belongs_to :press_release
end
module Commentable
extend ActiveSupport::Concern
included do
after_create :notify_to_admin
end
private
def notify_to_admin
# サービス管理者あてにコメントが投稿されたことを通知する処理を書く
end
end
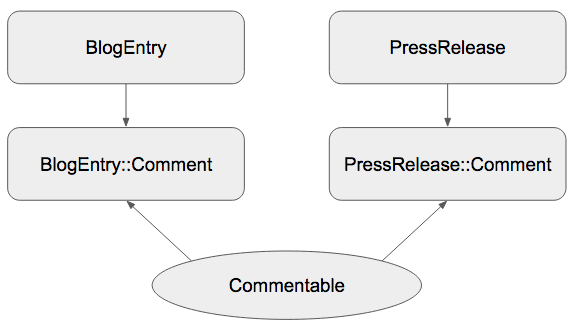
Concernを使うことで、実装そのものは別ファイルに切り出して共通化することができましたが、2つのコメントモデルの責務は増えてしまいました。「コメント投稿時に管理者あてに通知されること」のテストをどこに記述するかも悩ましい問題です。Concernをincludeしたモデルで網羅的にテストを書いていると冗長なテストが増えていきますし、Concernのモジュールを単体でテストするのも一工夫が必要で、積極的に選びたい感じではありません。
# (a) include先のモデルでテストする
describe BlogEntry::Comment do
context 'notify_to_admin' do
# ...
end
end
# (b) テスト用のクラスを作成し、そこにConcernを混ぜ込んでテストする。
describe Commentable do
let(:klass) do
Class.new do
# Commentable に必要ないろいろなメソッドたちを定義する
end.tap do |kls|
kls.include(Commentable)
end
end
context 'notify_to_admin' do
# ...
end
end
最近、私がコードレビュー等でConcernを使っているところ見かけた時には、「Concernを使って責務を混ぜ込むのではなく、独立したクラスを作って責務を移譲しよう」ということを言うようにしています。
例えば、以下のような感じでしょうか。
class BlogEntry::Comment
belongs_to :blog_entry
after_create -> { CommentCreateNotificationToAdmin.perform(self) }
end
class PressRelease::Comment
belongs_to :press_release
after_create -> { CommentCreateNotificationToAdmin.perform(self) }
end
class CommentCreateNotificationToAdmin
def self.perform(comment)
# サービス管理者あてにコメントが投稿されたことを通知する処理を書く
end
end
Concernを使わずに、素のRubyオブジェクトを作って処理を移譲することで、モデルの責務を整理し、テストも書きやすい実装になっていくでしょう。
まとめると、
- Concern を使うとテストが書きにくくなるから (ちょっとトリッキーなテストになりがち)
- 単一責務の原則に反するから (そのクラスの役割が増えすぎる)
というような理由で、Concernを使うべきでない、と考えるようになりました。
Callbackに使われない
RailsではCallbackが豊富な機能を持っており、便利に使うことができます。が、便利だからという理由で使いすぎると、見通し悪く責務の分離も曖昧になり...という悪循環になりかねません。
他のフレームワークではCallbackを使わずに複雑な処理を実現しているのです。Railsでも「Callbackに使われる」のではなくて、別の手段を見つければ良いのです。そうしないと、Callback地獄から抜け出せません。1
先程のBlogEntry::Commentについて、引き続き考えてみます。各々のコメントが作成・更新・削除された時の処理が増えていった...という状況を考えてみましょう。
class BlogEntry::Comment
belongs_to :blog_entry
# ユーザ自身による作成・更新の場合は管理者向けに通知
after_save -> { CommentUpdateNotificationToAdmin.perform(self) }, if: -> { by_user? }
# ユーザのコメント投稿数を更新する
after_save -> {
# 最初の公開時にだけインクリメントする (公開→非公開→公開、と変化したときにカウントしない)
if by_user? && first_published?
User.increment_counter(:blog_etnry_comment, user.id)
end
}
# ブログエントリの購読者にコメント投稿されたことを通知する
after_save -> {
self.blog_entry.watchers.each do |watcher|
BlogEntryCommentNotifier.create(blog_entry, watcher, comment)
end
}
end
このように、たくさんのコールバックが増えてしまった...という状況は案外あるのではないでしょうか。
この例ではうまく表現できていませんが、callback同士が依存し、実行順とデータの状態によってエラーが発生する...なんていう状況になってしまうと、デバッグの難易度もあがり、サービスを安定して開発し続けるのが難しくなってしまいます。
そうならないために、一連の処理を見通しよく記述することが大切でしょう。全ての場面で使える「銀の弾丸」は無いので、状況に応じて適切な手段を考えていく必要があります。PofEAAの言うところの「サービス層 (Service Layer)」は、その一つの手段です。まずはServiceの入れ物を作ってCallbackの処理を移動させてみましょう。
class BlogEntries::CommentsController
before_action :set_blog_entry
def create
BlogEntries::CommentCreationService.new(user: current_user, blog_entry: @blog_entry, comment_params: comment_params).perform!
head :created
rescue ActiveRecord::RecordInvalid => e
render json: { ... }, status: :unprocessable_entity
end
private
def set_blog_entry
@blog_entry = BlogEntry.find(params[:blog_entry_id])
end
def comment_params
params.require(...).permit(...)
end
end
# app/services/blog_entries/comment_creation_service.rb
class BlogEntries::CommentCreationService
def initialize(user:, blog_entry:, comment_params:)
@user = user
@blog_entry = blog_entry
@comment_params = comment_params
end
def perform!
create_comment
notify_to_admin
increment_user_counter
notify_to_blog_entry_watchers
end
private
attr_reader :user, :blog_entry, :comment_params
def create_comment
comment = blog_entry.comments.build(comment_params)
comment.user_id = user.id
comment.save!
end
def notify_to_admin
CommentUpdateNotificationToAdmin.perform(self)
end
def increment_user_counter
if comment.published?
User.increment_counter(:blog_etnry_comment, user.id)
end
end
def notify_to_blog_entry_watchers
blog_entry.watchers.each do |watcher|
BlogEntryCommentNotifier.create(blog_entry, watcher, comment)
end
end
end
BlogEntry::Comment のCallbackで、隣(BlogEntry)の隣(Watcher)の関連まで辿っていたのが無くなったり、処理順依存のあるCallback処理が明示的に順序が指定できるようになったり、と、一定のメリットはあるでしょう。しかし、オブジェクト指向設計に即しているかというと、まだまだ...ですね。オブジェクト指向プログラミングを実践できないまま積み重なっていくと、Service層のひとつひとつのクラスが肥大化していき、「俺が悪かった。素直に間違いを認めるから、もうサービスクラスとか作るのは止めてくれ by joker1007」というような状況になってしまいかねない気もします。この部分については、「オブジェクト指向を実践しよう」という掛け声だけでは足りず、幾つかのルールを明示するなど、継続して考えていかないといけない部分だと思っています。
まだ結論には至っていませんが、今考えている2つのアプローチについて簡単に紹介します。巨大で複雑なRailsアプリケーションをどのように設計・実装していくべきか、議論できると嬉しいです。
Service Layer の構造化
REST的な画面設計・UI/UX設計にできるならば、各Controllerでの処理はシンプルなものになるでしょう。現実にはそんなことはなく、1回のHTTPリクエストで複数のコンテキストに跨る処理を実行する必要が出てくることもあると思います。
例えば、
- 外部の決済APIを呼び出して決済処理を実行する
- 決済成功の情報を元に、自社サービスに反映する
- (決済成功後に使えるようになる機能を有効化したり、領収書を作ったり、etc...)
というような場合。それぞれは独立した処理・トランザクションになり、興味の対象範囲は異なりますが、1回のHTTPリクエストで処理実行したい...ということはあるでしょう。Serviceの興味の範囲を適切に狭めつつ、Controllerの責務も小さく保つために、その間を取り持つ「ServiceHandler」のような層を作ると良いのではないだろうか、というアイディアを持っています。
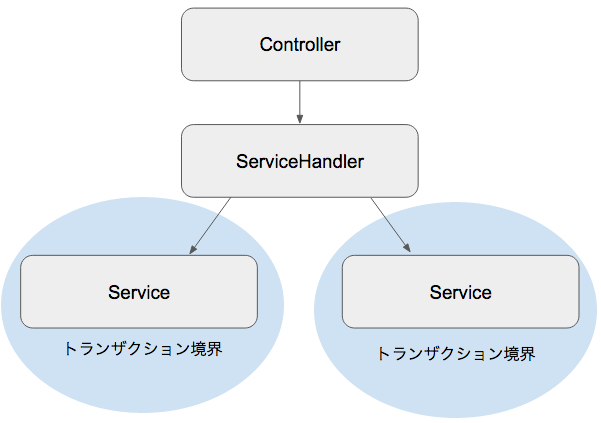
- Controller
- ユーザからのリクエストをハンドリングする
- ServiceHandlerを1つだけ呼び出す
- ServiceHandler
- Controllerから呼ばれる
- ServiceHandlerは一つまたは複数のServiceを呼び出す
- 他のServiceHandlerを呼んではいけない
- Service
- ServiceHandlerから呼ばれる
- 他のServiceを呼んではいけない
- トランザクションの境界を担う
- ActiveRecord::Baseを継承したモデルを操作する
こういったルール(パターン)を明示することで、アプリケーションで統一された設計が進んでいくのではないか、と考えています。
イベント駆動を取り入れる
イベントメッセージを publish / subscribe する構造を取り入れることが出来れば、ロジックの依存関係を分離できるようになるでしょう。雑なサンプルコードですが、以下のようなイメージでしょうか。
class BlogEntries::CommentCreationService
def initialize(user:, blog_entry:, comment_params:)
@user = user
@blog_entry = blog_entry
@comment_params = comment_params
end
def perform!
create_comment
publish_event
end
private
attr_reader :user, :blog_entry, :comment_params
def create_comment
comment = blog_entry.comments.build(comment_params)
comment.user_id = user.id
comment.save!
end
def publish_event
EventPublisher.blog_entry_comment_created(user: user, blog_entry: blog_entry, comment: comment)
end
end
module BlogEntries::CommentCreationEvent
class NotificationToAdminSubscriber
def self.perform(user:, blog_entry:, comment:)
# 管理者向けの通知処理
end
end
class UserSummaryUpdateSubscriber
def self.perform(user:, blog_entry:, comment:)
# ユーザのコメント投稿数を更新する
end
end
class WatcherNotificationSubscriber
def self.perform(user:, blog_entry:, comment:)
# ブログエントリの購読者にコメント投稿されたことを通知する
end
end
end
このようなアーキテクチャを取り入れることで、ロジック間の依存関係を排除し、トランザクション的にも分離することができます。さらに言えば、Subscribeするアプリケーションは場合によっては Ruby on Rails 以外の言語・フレームワークを選択できるようになり、サービス全体のスケーラビリティ確保にも繋がると考えています。
まだ本格的に取り組み始めたばかりではありますが、実際に導入してみてどうなったか、後々お知らせできればと思っています。
まとめ
この記事では、クラウドワークスで考えている「大規模で複雑な業務要件を担うRailsアプリケーションとの付き合い方」の一部をご紹介しました。最近、Railsを使ったアプリケーション設計・実装について考える中で思っていることは、
- Railsは複雑な機能を簡単に使えるように、便利な道具(Polymorphic、Concern、Callback、...)を用意してくれた
- 規模が小さい/シンプルなアプリケーションであれば、その便利な道具を使うことによって得られるメリットは凄く大きい
- けれども、規模が大きく/複雑なアプリケーションになった時には、「難しいことを簡単に実現する道具」の内部まで知る必要が出てきて辛くなる
というような事です。サービス立ち上げ時のRailsのメリットは十二分に理解できる一方で、その考えだけでは、大規模・複雑なアプリケーションを維持し続けることは難しいと感じています。そこに「銀の弾丸」は無く、いろいろなアプローチを考え続ける必要があると思っていて、その一端をこの記事ではご紹介しました。
クラウドワークスでは、サービスのアーキテクチャを考えながら、一緒に手を動かしてくれる仲間を募集しています。この記事や、アドベントカレンダーの他の記事を読んで興味が湧いたら、ぜひお話させてください。
気になるエンジニアと寿司ランチという企画もあるので、気になる記事を書いていたエンジニア指名もお待ちしています(時間帯は個別調整可能なので夜でもどうぞ)。
この記事はCrowdWorks Advent Calendar 2016 の24日目の記事でした。明日はクラウドワークス副社長の@shuzonaritaによる「非エンジニア副社長がゼロから歩む テクノロジー企業経営への道」の予定です。
-
本年のアドベントカレンダー21日目実録!!データ構造リファクタリング -- 僕とメッセージ機能の300日戦争参照 ↩