本記事は OpenAI活用法 Advent Calendar 2023 by ナレコム の9日目の記事です。
OpenAI活用法 Advent Calendar 2023 by ナレコム ではGPTsを含めた最新のOpenAIの活用法について紹介します。
はじめに
前回の記事「Azure OpenAI Studioを活用した効率的なチャットアシスタント構築」では、Azure OpenAI Studioを使ってデータソースを追加し、チャットアシスタントをセットアップする方法を解説しました。今回の記事では、その続きとして、ベクター化した大量データの実用性と注意点に焦点を当てます。特に、文章の引用と検索性能の最適化、Azure AI Searchでのチューニングの難易度、およびキーワード検索の挙動に関して詳しく掘り下げていきます。この情報を活用し、より精度の高いAIベースのアシスタントを構築しましょう。
準備
前回の記事を参考にお願いします
OpenAIでベクター化したデータを利用する
-
Azure OpenAI Studio にアクセスし、左メニュー「チャット」を選び、 アシスタントのセットアップ の「データの追加(プレビュー)」をクリックします。
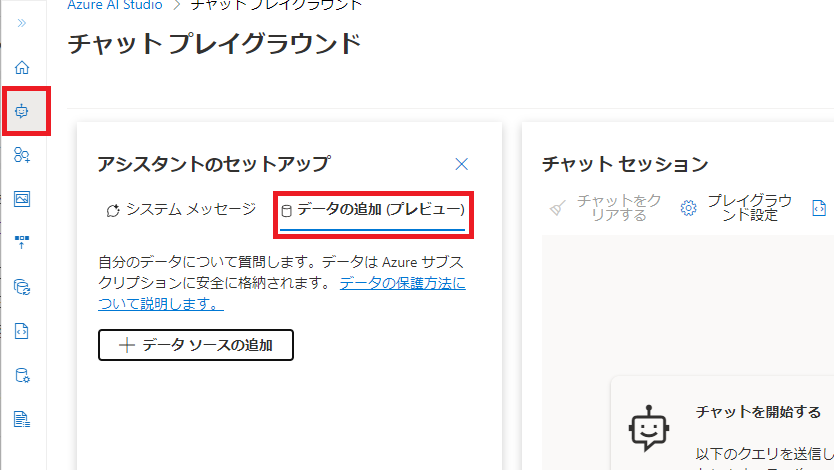
- 「データソースの追加」をクリックし、データ追加ウィンドウを立ち上げます。
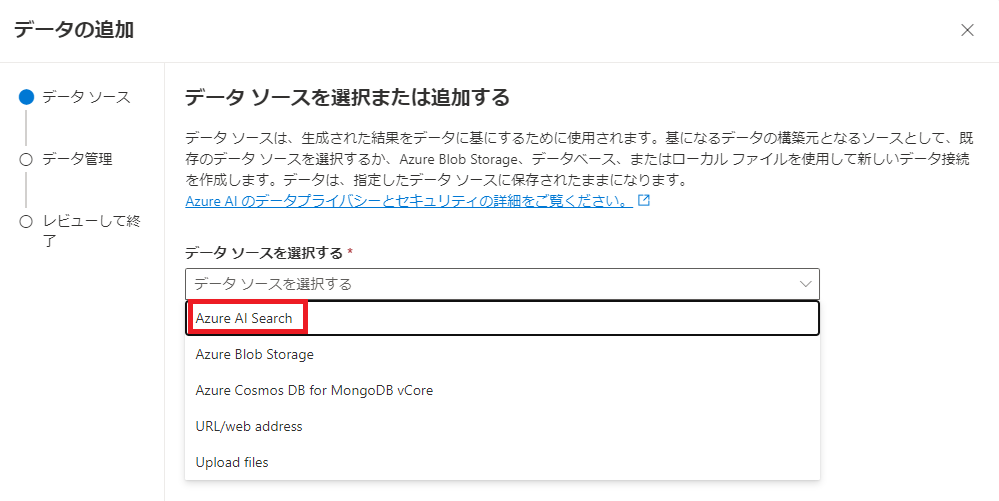
- 以下のように選択します。
データ ソースを選択する⇒Azure AI Search
サブスクリプション⇒前記事でベクター化を実行したサブスクリプション
Azure AI Search Service⇒前記事でベクター化を実行したAzure AI Search
Azure AI Search インデックス⇒前記事でベクター化したインデックス
ベクトル検索をこの検索リソースに追加します。⇒チェック
埋め込みモデルを選択する⇒前記事で準備したOpenAIの埋め込み(embedding)モデル
Azure AI Searchアカウントに接続すると、アカウントが使用されるようになることに同意します。⇒チェック - 「インデックス データ フィールドのマッピング」では以下のように選択します。
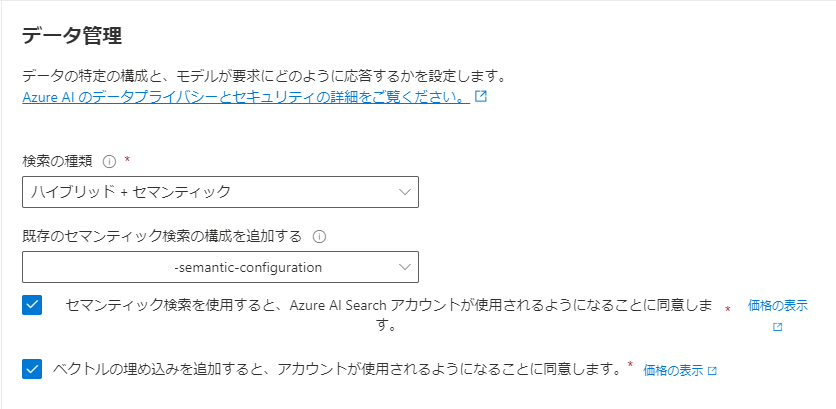
コンテンツデータ⇒chunkにチェック - 「データ管理」では以下のように選択します。
検索の種類⇒ハイブリッド+セマンティック(ベクトル、ハイブリッド(ベクトル+ハイブリッド)でも可だが、性能が異なる)
既存のセマンティック検索の構成を追加する⇒前記事でベクターに自動的に下図のようなものが追加されているので選択
両方の項目にチェック
- 確認画面が表示されるので「保存して閉じる」
完了すると以下のようにアシスタントにデータソースに選択したソースが表示されます。
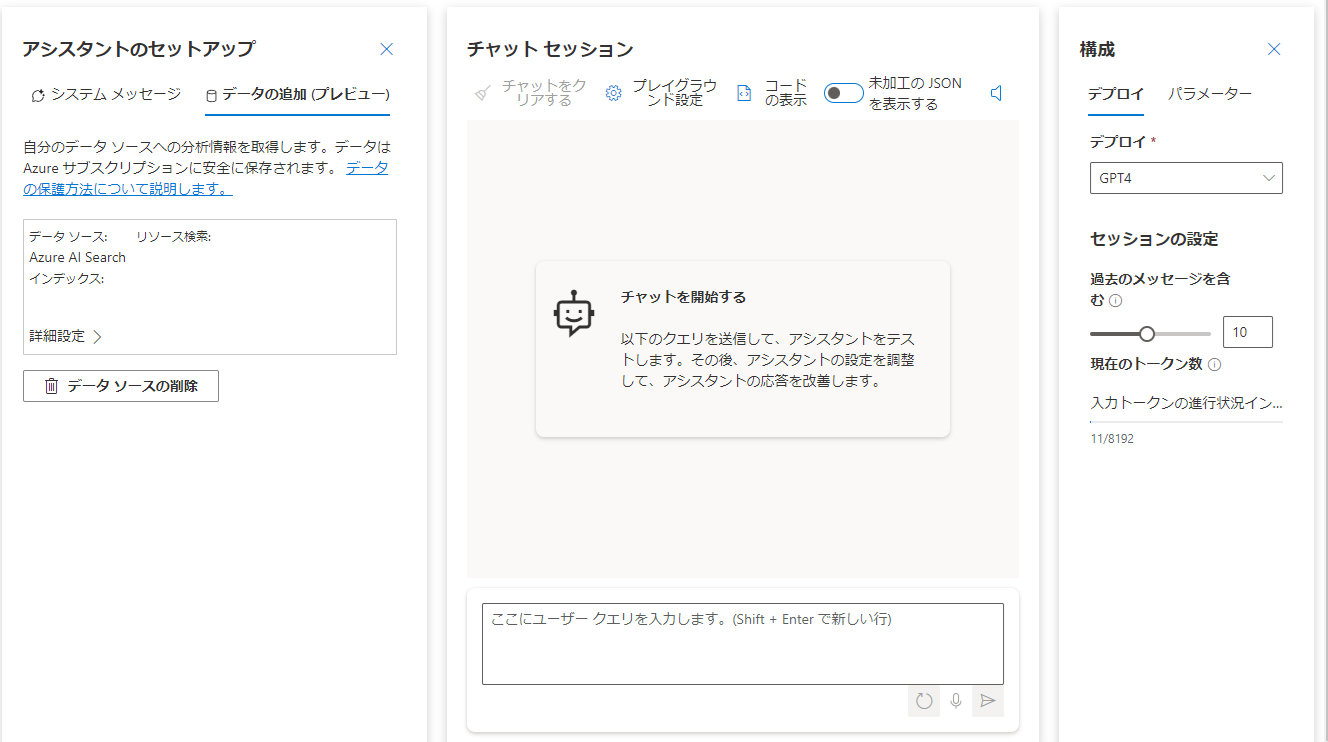
実行すると以下のようにAI Searchに登録したデータを参照した回答を返してくれます。
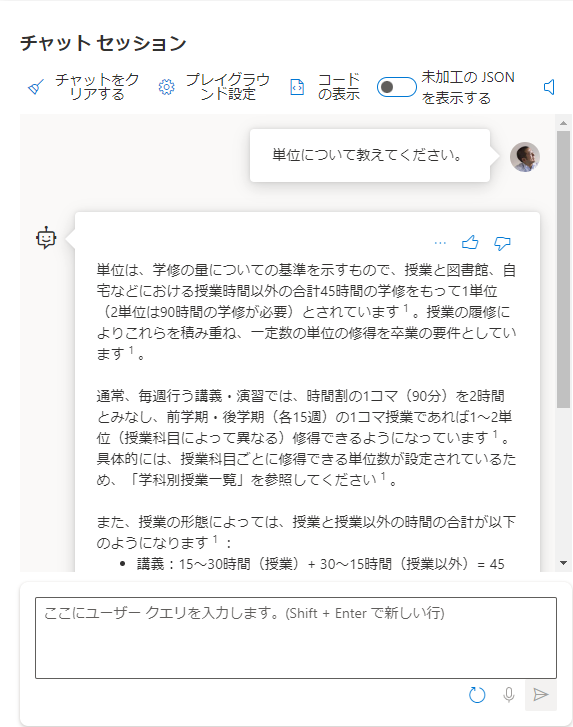
ベクター化した大量データを利用することは魅力ですが、現時点での注意事項としては、
- 主に文章の引用に依存し、複雑な文章の再構成や要約には限界があります。例えば、全体の文章からいい感じに必要な情報をまとめて欲しい、などは出来ないと思ったほうが良い
- 検索性能は主にAzure AI Searchに依存し、望む回答を得るためには高度なチューニングが必要です
- 『「〇〇」と検索して』など特定のキーワードでの検索を指示しない限り、AIがどのようなキーワードで検索するか予測するのは困難です
- キーワードに複数の回答が存在する場合、回答は検索のヒットスコア順で表示され、文脈に適した部分を特定するのは難しい場合があります。対応策としては人間の問い合わせ文章を変える必要がある
まとめ
本記事では、Azure OpenAI Studioを利用してチャットアシスタントにデータソースを追加し、ベクター化したデータを活用する方法を探求しました。重要な点として、文章の引用の限界、検索性能に関するAzure AI Searchの依存性、およびキーワード検索の挙動について説明しました。これらの知見は、AIアシスタントの構築と最適化において役立つでしょう。
また、ナレッジコミュニケーションでは 「Musubite」 というエンジニア同士のカジュアルトークサービスを利用しています!この記事にあるような生成AI 技術を使ったプロジェクトに携わるメンバーと直接話せるサービスですので興味がある方は是非利用を検討してください!