subprocessが使えると何が嬉しい?
subprocess -- サブプロセス管理(python, 3.11.11)によると、サブプロセスを使うことによって外部処理ができるようになるようです。どう言うことかと言いますと、python経由でshellスクリプトや外部コマンドを実行できるのです。
まずは使ってみる (subprocess.call(), subprocess.run())
言葉だけだと良くわからないので、動かしてみます。
こんな感じでシェルスクリプトを入力してみます。
ディレクトリを作成したり、ファイルを生成したり。
import subprocess
# 適当なディレクトリを作成
subprocess.call('mkdir test', shell=True)
# ランダムなファイルを生成
for i in range(5):
subprocess.call(f'touch test/file_{i}.txt', shell=True)
# ファイル一覧を表示
result = subprocess.call('ls -l test', shell=True)
print(result)
すると、こんな感じの出力が出てきます。
akirakawai$ python subprocess_intro.py
total 0
-rw-r--r-- 1 akirakawai staff 0 1 27 22:51 file_0.txt
-rw-r--r-- 1 akirakawai staff 0 1 27 22:51 file_1.txt
-rw-r--r-- 1 akirakawai staff 0 1 27 22:51 file_2.txt
-rw-r--r-- 1 akirakawai staff 0 1 27 22:51 file_3.txt
-rw-r--r-- 1 akirakawai staff 0 1 27 22:51 file_4.txt
0
ドキュメントによると、
returncode
子プロセスの終了コード。一般に、終了ステータス 0 はプロセスが正常に終了したことを示します。
最後の0は終了コードを示すようです。
また、subprocess.call()とsubprocess.run()は同じような使い方ができるようです。
DIR_NAME = 'test_run'
subprocess.run(f'mkdir -p {DIR_NAME}', shell=True)
for i in range(5):
subprocess.run(f'touch {DIR_NAME}/file_{i}.txt', shell=True)
result = subprocess.run(f'ls -l {DIR_NAME}', shell=True)
subprocess.run(f'sudo rm -rf {DIR_NAME}', shell=True)
sudo権限も使えるようです。pass入力を求められます。
# check=Trueを指定すると、コマンドが失敗した場合に例外を発生させる
try:
result = subprocess.run('ls -l not_exist_folder', shell=True, check=True)
except subprocess.CalledProcessError as e:
print(e)
print('Failed to execute command')
エラーキャッチもできるようです。
ls: not_exist_folder: No such file or directory
Command 'ls -l not_exist_folder' returned non-zero exit status 1.
Failed to execute command
しかし、今の所、「シェルスクリプトを普通に書けば良くない?」と思いつつあります。
画像処理のコードを書いているときに、FFMPEGなどの外部ツールを使用したくなった場合には便利かもしれません。
subprocess.popen()で真価を発揮
リアルタイムの情報を取得したい場合は、subprocess.run()だと不十分な場合があります。
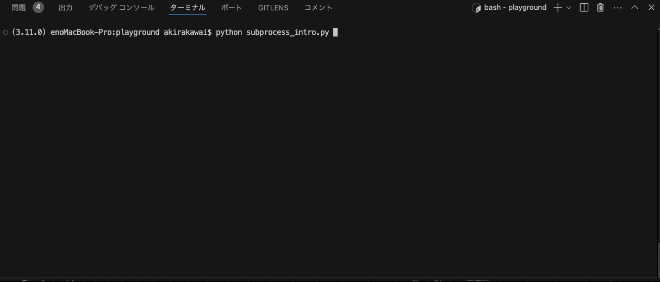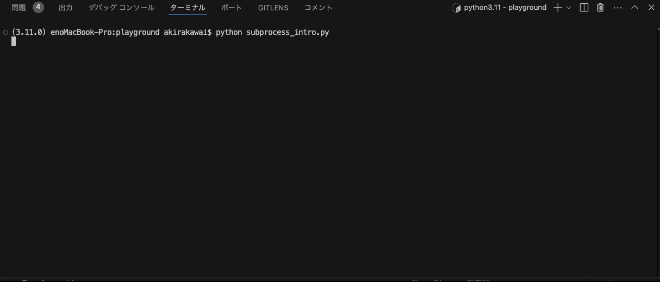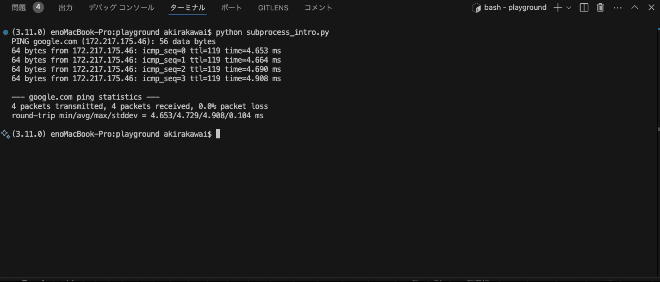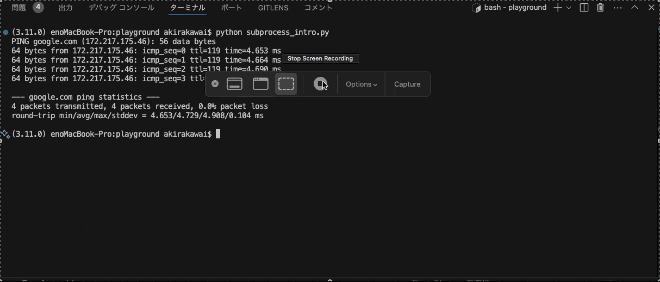
result = subprocess.run(['ping', '-c', '4', 'google.com'], stdout=subprocess.PIPE, text=True)
print(result.stdout)
結果は、4秒後にprintされます。
subprocess.Popen()を使用すると、
import subprocess
process = subprocess.Popen(['ping', '-c', '4', 'google.com'], stdout=subprocess.PIPE, text=True)
# 出力をリアルタイムで読み込む
for line in process.stdout:
print(line, end='')
process.wait() # プロセス終了を待つ
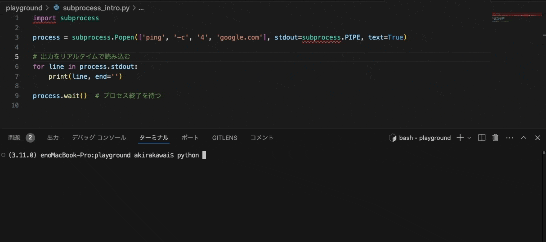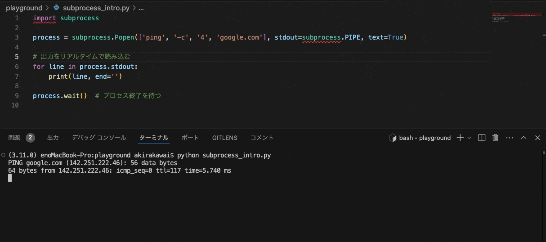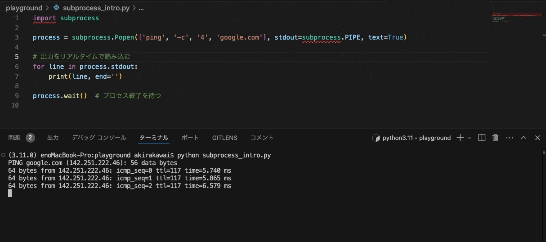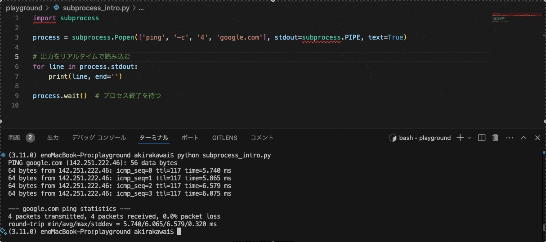
このようにリアルタイムの情報を取得することができます。
これは、時系列系のリアルタイム情報を引っ張ってくるのに良いかもしれませんね。
例えばですが、株価や気象情報などの速報値を加工して表示する際に便利かもしれません。
Popen()は、プロセスの開始、定義、初期化を担当します。
| 処理名 | 概要 |
|---|---|
| Popen() | プロセスの初期化、実行 |
| Popen.wait() | プロセスの終了を待機 |
| Popen.poll() | 非同期的にプロセスの出力を取得 |
| Popen.communicate() | 標準入力を渡し、標準出力と標準エラーを取得する |
| (stdout, stderr) | プロセスの標準出力や標準エラーを取得 |
プロセスの進捗状況 (Popen.poll(), None もしくは 0)
Popen.poll()
子プロセスが終了しているかどうかを調べます。 returncode 属性を設定して返します。そうでなければ None を返します。
Popen.communicate()
Popen.poll()
import subprocess
import time
process = subprocess.Popen(["sleep", "5"])
for i in range(5):
time.sleep(1)
print(f"{i+1}秒経過... process.poll():", process.poll())
こんな感じで処理を書きますと、
python subprocess_intro.py
1秒経過... process.poll(): None
2秒経過... process.poll(): None
3秒経過... process.poll(): None
4秒経過... process.poll(): None
5秒経過... process.poll(): 0
と出力されます。
return == 0のタイミングで処理が終了したとわかります。
Popen.communicate()
Popen.communicate()は、任意の入力をプロセスに投入するのシチュエーションで便利ということでした。
import subprocess
import time
process = subprocess.Popen(
["grep", ".*\.txt"],
stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
text=True,
)
INPUT = "file_0.txt\nfile_1.txt\nfile_2.txt\nimg_1.jpg\nimg_2.jpg\nimg_3.jpg\n"
stdout, stderr = process.communicate(input=INPUT)
print("STDOUT:", stdout)
print("STDERR:", stderr)
subprocess.Popen()を使って大量の画像をコピーしてみる
こんな感じのコードを書いてみます。「以下のコードを読んでリスクについて指摘しなさい」という問題に出てきそうなダメコードですが、重大なリスクに気づきますでしょうか。こちらのコードは実行しても失敗します。
import os
import subprocess
from tqdm import tqdm
def copy_files_asynchronously(src_dir, dst_dir):
# コピー先ディレクトリを作成(存在しない場合のみ)
os.makedirs(dst_dir, exist_ok=True)
# コピー元ディレクトリ内のすべての画像ファイルを取得
image_files = [f for f in os.listdir(src_dir) if f.lower().endswith(('.png', '.jpg', '.jpeg', '.gif', '.bmp'))]
processes = [] # プロセスを保存するリスト
# 各画像を非同期でコピー
for image in tqdm(image_files):
src_path = os.path.join(src_dir, image)
dst_path = os.path.join(dst_dir, image)
# subprocessを使って非同期コピー
# print(f"Starting copy: {src_path} to {dst_path}...")
process = subprocess.Popen(['cp', src_path, dst_path]) # 非同期実行
processes.append(process)
# 全てのプロセスの終了を待機
for process in processes:
process.wait()
print(f"Copy finished with exit code {process.returncode}")
print("All copies are complete!")
if __name__ == "__main__":
src_dir = "./coco_data/val2017"
dst_dir = "./coco_data/val2017_copy"
copy_files_asynchronously(src_dir, dst_dir)
そうです。
process = subprocess.Popen(['cp', src_path, dst_path]) # 非同期実行
こちらのコードによって、プロセスが短時間で大量に生成されてしまい、システムの負荷が急激に増加します。恐ろしい処理ですね。実際、実行してみると、以下のようなエラーが出ました。
, line 21, in copy_files_asynchronously
process = subprocess.Popen(['cp', src_path, dst_path]) # 非同期実行
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/akirakawai/.pyenv/versions/3.11.0/lib/python3.11/subprocess.py", line 1022, in __init__
self._execute_child(args, executable, preexec_fn, close_fds,
File "/Users/akirakawai/.pyenv/versions/3.11.0/lib/python3.11/subprocess.py", line 1832, in _execute_child
self.pid = _fork_exec(
^^^^^^^^^^^
BlockingIOError: [Errno 35] Resource temporarily unavailable
これらのエラーを解決するには、Thread数を制限するためのconcurrent.futures.ThreadPoolExecutorまたはProcessPoolExecutorを使用する必要がありそうですが、そちらは別記事にまとめたいと思います。
まとめ
subprocessは、Python環境と他のコマンドおよびツールと連携させる便利な標準装備の関数です。非同期処理ができることによって、使い方を誤るとシステム負荷を増大させたり、リソース制限に引っかかったりするリスクもあるようです。ThreadPoolExecutorなどを次のステップで学んでいきたいですn