この記事の目的
Amazon DynamoDB(以下DynamoDBと記載)の可用性や書き込みのスループットの高さには大変魅力を感じています。
しかしながら、RDBとは全く異なる発想での設計が必要な点や、検索処理の自由度の低さに対しての有効な手立てを持ち合わせていない(スキルの問題)などがあり、なかなか実案件で採用するに至っていません。
そんな折に、とあるセミナーでDynamoDBの設計ノウハウを学ぶことが出来ましたので、その内容を自分なりに整理するためにこの記事を書きました。
(なお、セミナー主催者には本内容を記事で公開してよい旨の了解をいただいています。)
試したこと
試したことは大きく2つあります。
-
転置インデックスを用いて、ある程度複雑なデータモデルを1テーブルで処理する
-
パーティションキーの属性で前方一致検索をする方法を模索する
表記ルール
DynamoDBの用語については、文末の公式サイトに合わせています。
一部、略記をしている箇所を補足します。
- パーティションキー [PK] と略記
- ソートキー [SK] と略記
- グローバルセカンダリーインデックス [GSI] と略記
本編
1. 転置インデックスを用いて、ある程度複雑なデータモデルを1テーブルで処理する
データモデル
まず表現したいデータモデルを説明します。
一般的なECサイトをイメージしてもらえばわかりやすいと思います。
Userが買い物(Order)をして、そこに商品(Item)が含まれるというイメージです。
UserとOrderは、1対Nの関係になります。
また、OrderとItemはM対N(多対多)の関係になります。

DynamoDBでのデータ保有方法
DynamoDBのベストプラクティスの⼀つに、1システムあたり(なるべく)1テーブルにするというのがあります。(キャパシティーの管理などを単純化するためと理解しています)
参考
また、DynamoDBはRDBと異なりスキーマレスなので、上記のデータモデルを1テーブルに保有する場合には、以下のようなデータの持ち方が可能となります。
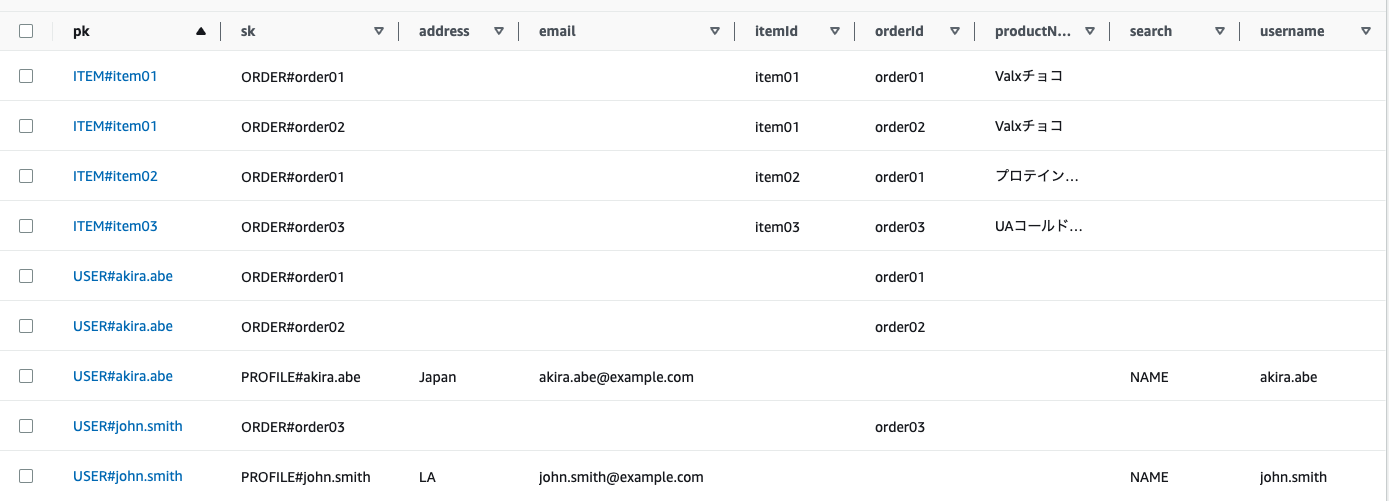
ポイント
3つのモデルを1テーブルで表現しますので、PKやSKに、UserId、OrderIdといったモデル固有の名前を与えることが出来ません。従って、ここでは、それぞれ、属性名に'pk','sk'という汎用的な名前を与えています。
属性の中身がどのモデルを表すのか?という部分は、データの中身に'USER#'、'ITEM#'のようなプレフィックスを与えることで表現しています。
データを検索してみる
上記の状態で、シナリオに沿ってデータを検索してみます。
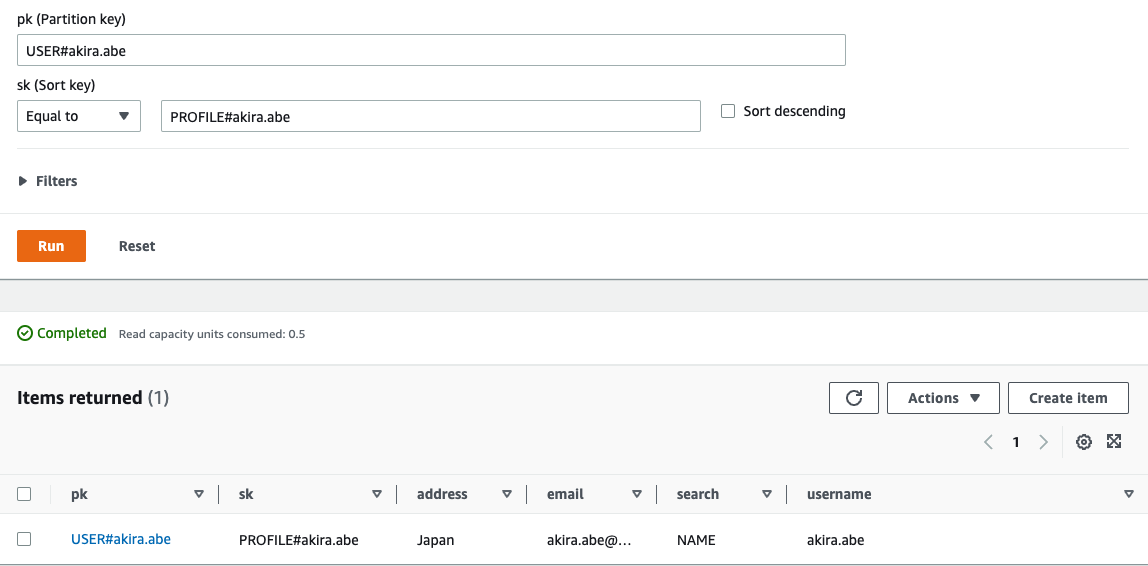
シナリオその1
User='akira.abe'のプロフィールを見る
これは、PKとSKを指定して以下のようなクエリーにより可能となります。
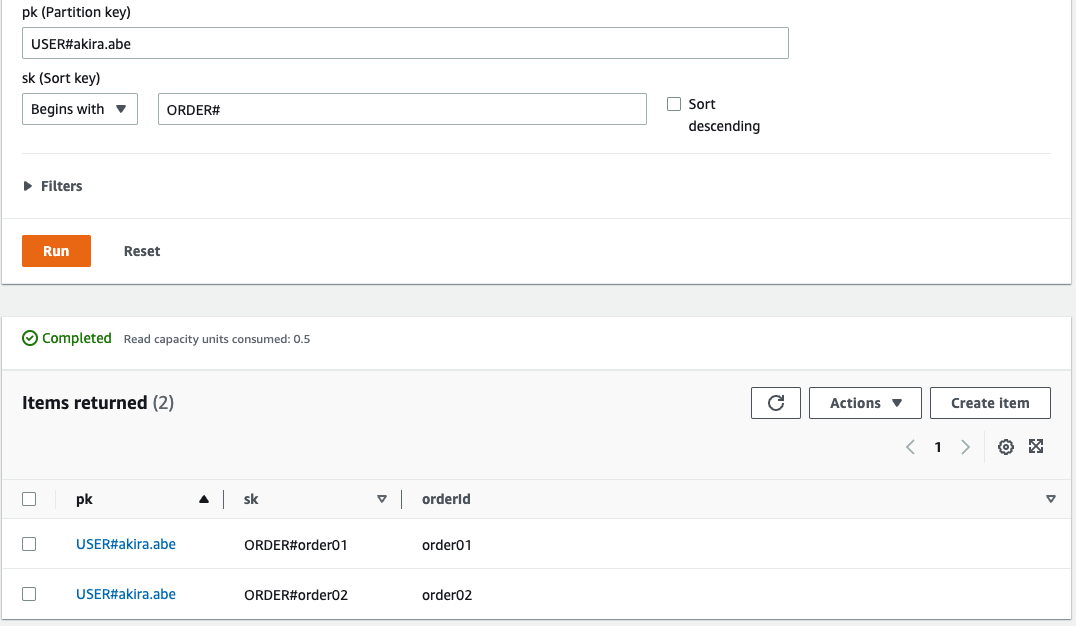
シナリオその2
User='akira.abe'のOrderを見る
これも、シナリオ1と考え方は一緒です。
シナリオその3
ここまでで、User='akira.abe'が、Orderを2回していることがわかりました。
次に、Single Tableとして⼊っている他のorder01のデータを検索(ただし、スキャン&フィルターではなくクエリーで!)してみたいと思います。
しかし、スキャン&フィルターではなくクエリーでということになると、テーブルだけでは実現ができません。
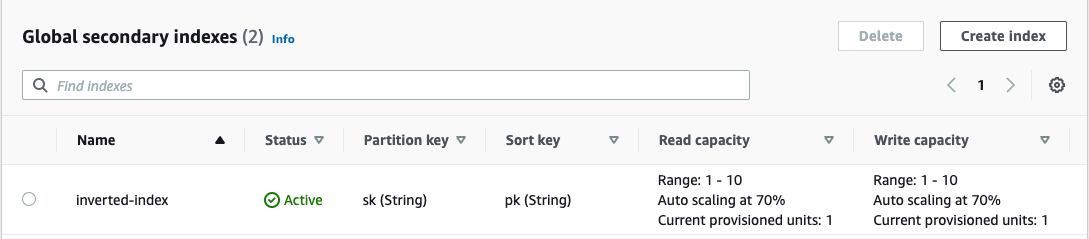
そこで、インデックスを作成します。(この場合には、PKが別項目なので、GSIを作成することになります。)
作成したGSIは以下のような内容です。
注目すべき点は、PKにテーブルのskという属性を、SKにテーブルのpkという属性をセットする部分です。
このようなインデックスを転置インデックスというそうです。
ちなみに、転置インデックスというのは、DynamoDBに限った用語ではなく、古くから存在する技法のようです。
転置インデックスについてのWikiPediaの説明
転置インデックスを用いた検索
転置インデックスを用いることにより以下のようにItemの検索が可能となります。
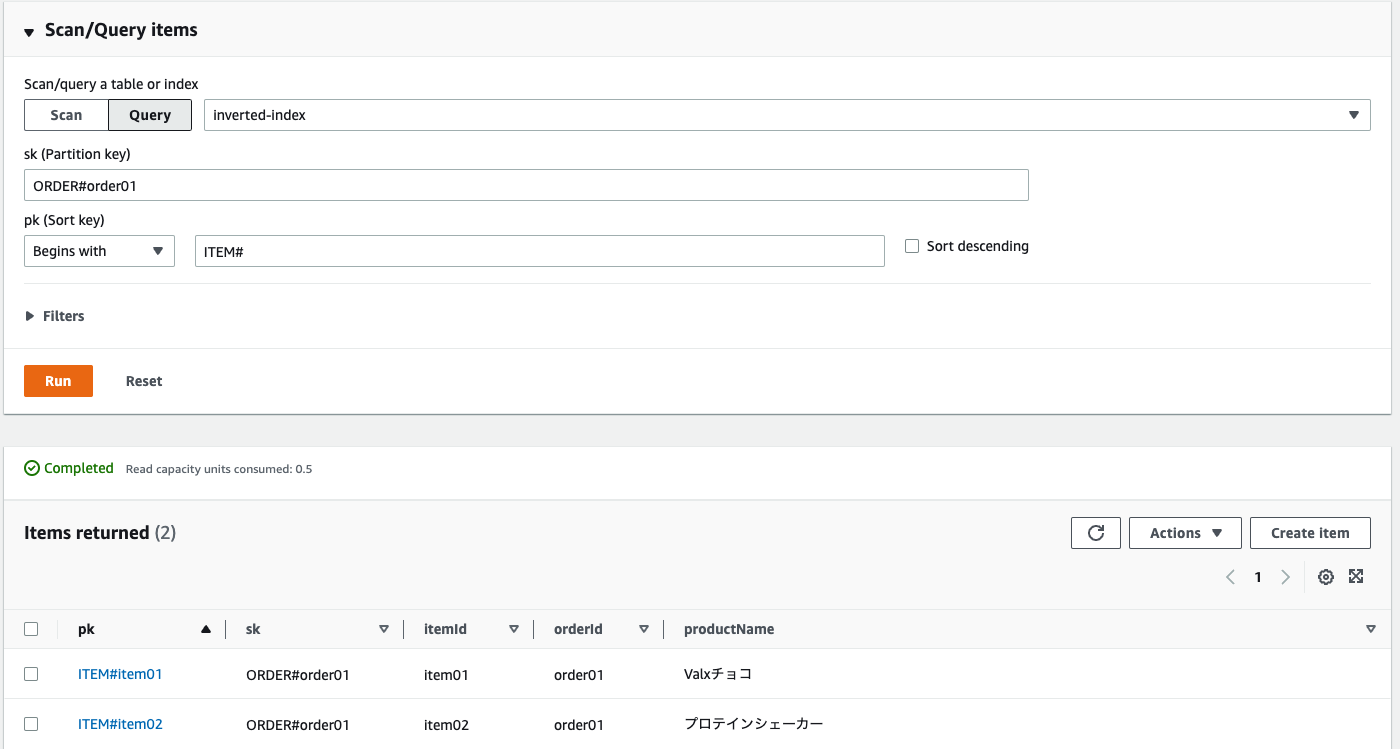
ここまでが、「転置インデックスを用いて、ある程度複雑なデータモデルを1テーブルで処理する」でした。
インデックスをうまく活用することにより柔軟な検索が可能となりました!
なお、この実装であれば、Item自体も単一で検索(item01というキーのみで他のOrderも横断的に検索)できます。
2. パーティションキーの属性で前方一致検索をする方法を模索する
補足: 2. の内容はセミナーでの内容ではなく独自に考えたものです。
ここまでの例では、起点となるUserのPKがわかっている(完全一致検索できる)というのが大前提となっていました。
しかしながら、現実のユースケースでは、前方一致検索ならできるが完全一致検索はむずかしいという状況が多々あります。(特に人名検索などは典型的だと思います)
こういった場合にも、スキャン&フィルターではなくクエリーで実現したいと考えましたが、残念ながら、DynamoDBはPKの前方一致検索を許してくれません。
参考:クエリーのキー条件式
GSIを作成する
従って、この場合にもインデックスを利用します。
ここでは、以下のようなインデックスを作成しました。

User名の前方一致検索を行う
上記のGSIにより、以下のような前方一致検索が可能となります。
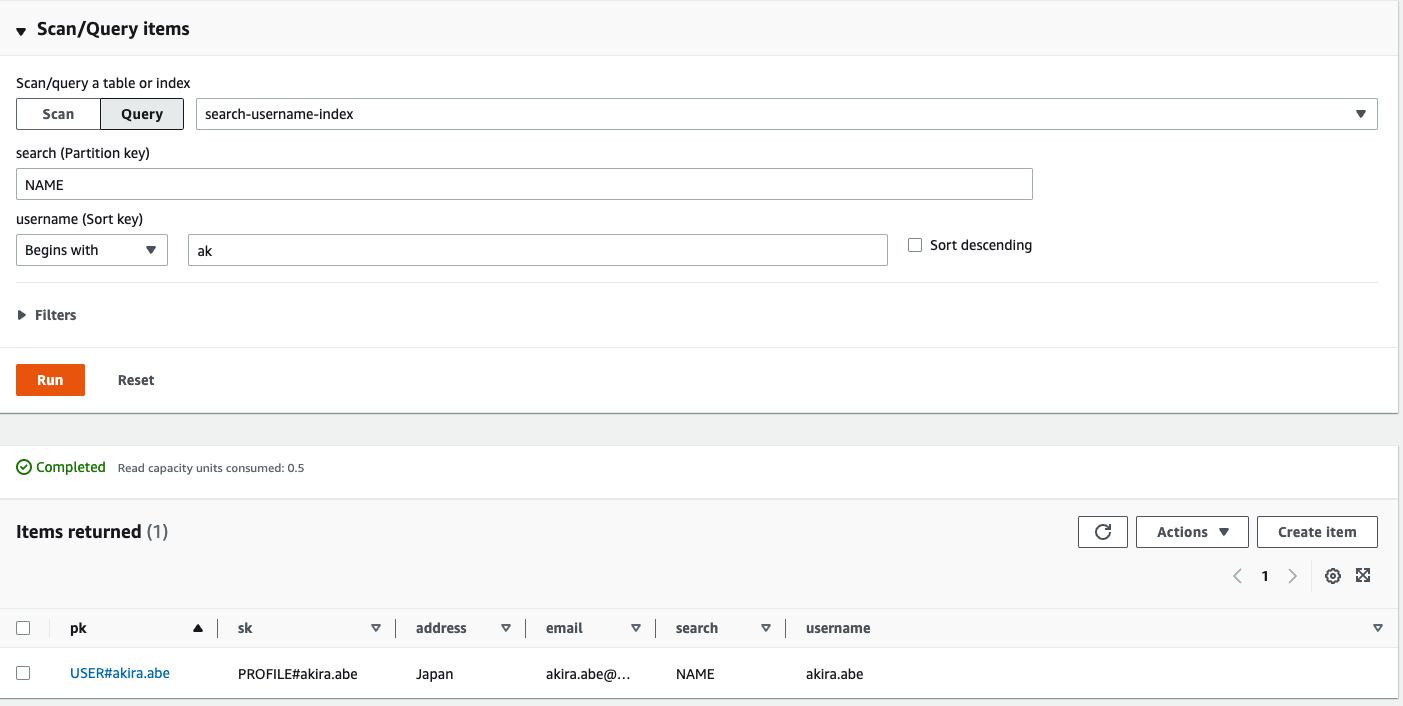
なお、この検索に使うPKの'search'という属性には、ここでは固定値(ここでは'NAME')をセットしています。
しかし、これは低カーディナリティによるGSI back pressure[参考]を誘発する可能性があるので、必要であれば⼈為的な分割をする必要があります。
Artificial shardingについては以下をご覧下さい。
https://docs.aws.amazon.com/ja_jp/amazondynamodb/latest/developerguide/bp-partition-key-sharding.html
https://docs.aws.amazon.com/ja_jp/amazondynamodb/latest/developerguide/bp-indexes-gsi-sharding.html
PKに相当する属性で前方一致検索をする方法については、これ以外にもいくつかの方法があると思います。
- コストが許容できるならば、割り切ってスキャン&フィルターを使う(ある程度他の条件クエリーで絞った後で最終的にフィルターで絞り込むことも可能です)
- 全文検索系サービスを使う
- DynamoDB Streams経由でRDSを作成してRDSを検索する(RDSを検索してDynamoDBのPK,SKを取得する)
しかしながら、どの方法も一長一短があります。
この属性での前方一致検索は絶対要るよね!というアクセスパターンが分析フェーズで識別出来ていれば、今回のようにGSIを作って前方一致検索に備えるというのは、アリかなぁと思っています。
今後も実際のユースケースに当てはめて検証していきたいと思います。
参考にしたサイト
公式 https://docs.aws.amazon.com/ja_jp/amazondynamodb/latest/developerguide/Introduction.html