マーケティングした!というのはやや言い過ぎですが🙇
Bedrockを実業務で使った事例として参考になれば幸いです!
1. サマリー
この記事では、以下の内容を記載します。
- 技術的視点
- LangChain, Streamlit, Amazon Bedrock(以下Bedrock)が登場します。(各々の技術要素についての説明は割愛します。)
- 業務的視点
- この記事はマーケティング業務でBedrockを利用した実経験をもとにしています。なお、実業務の内容そのままは掲載できないため、内容はかなりモデファイしています。
2. マーケティングでどのように利用したか?
マーケティングというと話が広いですが、やったことは、ユーザーに対して行ったアンケートをもとに、Bedrockを使ってユーザーをラベリング(ペルソナへの分類)し、ペルソナに最適な「情報発信」を行うというものです。
実際に、Streamlitで作った画面でBedrockによる分析が動く様子をアニメーションで表示します。
3. 実際のプロセスの紹介
プロセスの流れをPlantUMLで書いてみました。
生成AIに書いてもらったので細かい点が微妙ですが、大きくは間違っていないので、説明用には十分かと思います。
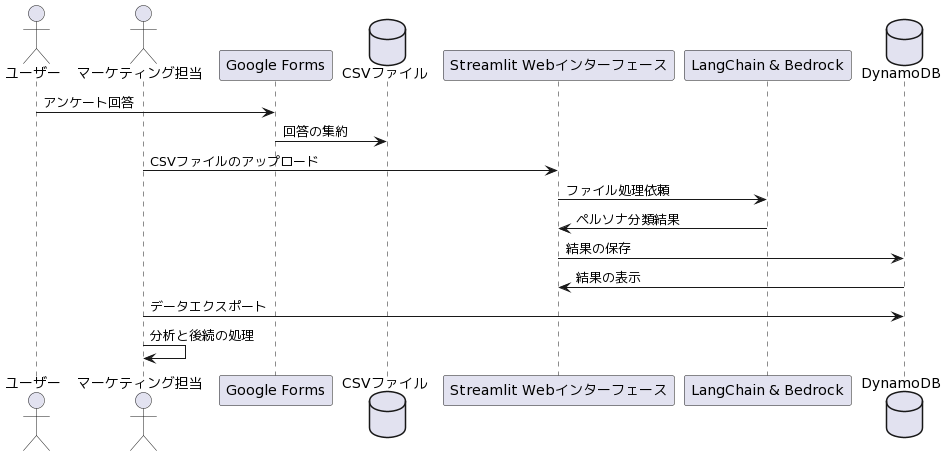
3.1. アンケートの設計
3.2. Streamlitを使ったフロントエンドの開発とLangChainとBedrockの統合
3.3. Bedrockによるペルソナ分類の仕組みと結果の表示方法
3.1. アンケートの設計
Google Formsによりアンケート収集し、結果はCSV形式のファイルにまとめます。(複数ユーザーの回答を一つのファイルにまとめます)
なお、アンケート項目を設計する際にも、Bedrockにペルソナを提示し、アンケート項目を提案してもらいました。
以下は、アンケートのイメージです。(本物からだいぶモデファイしています)
アンケート項目###
Q1. あなたの年代を教えてください。
1. 10代
2. 20代
3. 30代
4. 40代
5. 50代
6. 60代以上
Q2. あなたの家族構成を教えてください。
1. 独身
2. 既婚、子供なし
3. 既婚、子供あり
4. その他
Q3. 通常の休日はどのように過ごしますか?(複数回答可)
1. アウトドア活動
2. ショッピング
3. 家でリラックス
4. スポーツや運動
5. 趣味やクラフト
Q4. 一週間の平均的なインターネット利用時間はどのくらいですか?
1. 5時間未満
2. 5-10時間
3. 10-20時間
4. 20時間以上
Q5. 購入を決める際に最も重視する点は何ですか?(複数回答可)
1. 品質
2. 価格
3. ブランドの信頼性
4. ユーザーレビュー
5. 環境への配慮
Q6. 健康や栄養に関してどの程度意識していますか?
1. 高い
2. そこそこ
3. あまり意識していない
4. まったく意識していない
Q7. ビジネス関連のネットワーキングやイベントに参加しますか?
1. 頻繁に
2. たまに
3. ほとんど参加しない
4. 参加しない
###
3.2. Streamlitを使ったフロントエンドの開発とLangChainとBedrockの統合
この辺りはソースコードを見ていただいた方がわかりやすいと思います。
▪️本体のコード(StreamlitからBedrock呼び出し)
import os
import streamlit as st
from langchain.chat_models import BedrockChat
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from modules.template import get_template
import pandas as pd
from dotenv import load_dotenv
load_dotenv()
AWS_DEFAULT_REGION = os.environ.get('AWS_DEFAULT_REGION')
import langchain
langchain.verbose=False
def init_page():
st.set_page_config(
page_title="Questionary Analyzer",
page_icon="🤗"
)
# サイドバーを表示
st.sidebar.title("Nav")
# CSVアップロードの画面
def get_csv():
uploaded_file = st.file_uploader(
label='Upload your CSV file',
type='csv',
)
if uploaded_file:
# pandasのデータフレームを読み込む
df = pd.read_csv(uploaded_file)
print(df)
return df
else:
return None
# ペルソナ分類の画面
def page_csv_upload_and_create_template():
st.title("CSV Upload")
container = st.container()
with container:
df = get_csv()
st.session_state.df = df
def page_analyze_questionary():
st.title("Questionary Analyzer!")
# session_stateからdfを取得
df = st.session_state.df
# Create chat_model(Calude2を利用)
MODEL_ID = "anthropic.claude-v2"
chat_model = BedrockChat(model_id=MODEL_ID, streaming=False, model_kwargs={"temperature": 0.0, "max_tokens_to_sample" : 2048})
# Templateの定義
template = get_template()
button = st.button("Analyze")
if button:
# データフレームの行をイテレーションする
for row in df.itertuples():
# print(row)
print('----')
# PromptTemplateを使って、promptを作成する
prompt = PromptTemplate(
input_variables=["message"],
template=template
)
# LLMにpromptを渡して、回答を得る
chain = LLMChain(llm=chat_model, prompt=prompt)
input = f"""
Q1. {row.Q1}
Q2. {row.Q2}
Q3. {row.Q3}
Q4. {row.Q4}
Q5. {row.Q5}
Q6. {row.Q6}
Q7. {row.Q7}
"""
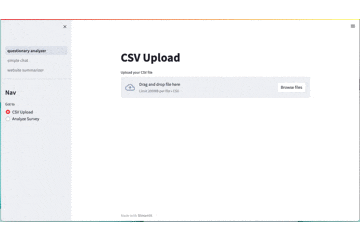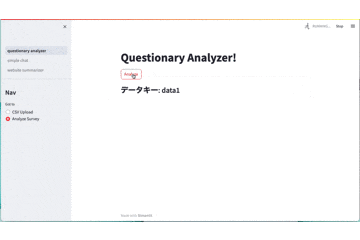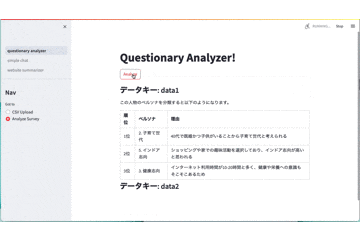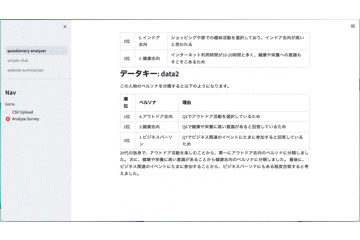
st.markdown('### データキー: ' + str(row.KEY))
result = chain.run(message=input)
# DynamoDBに保存する(コメントアウト)
# put_item(str(row.KEY), result)
st.write(result)
def show_page():
selection = st.sidebar.radio("Got to", ["CSV Upload", "Analyze Questionary"])
if selection == "CSV Upload":
page_csv_upload_and_create_template()
else:
page_analyze_questionary()
def main():
# ページの初期設定
init_page()
# メインページの表示
show_page()
if __name__ == "__main__":
main()
▪️プロンプトのテンプレートコード
def get_template():
template = """
販売促進のための情報提供を行うことを考えています。
そのために、以下のようなアンケートを取り、その結果をペルソナに振り分けたいと思います。
アンケート###
Q1. あなたの年代を教えてください。
<長くなるので途中を省略してあります!>
Q7. ビジネス関連のネットワーキングやイベントに参加しますか?
1. 頻繁に
2. たまに
3. ほとんど参加しない
4. 参加しない
###
ペルソナ###
1.ビジネスパーソン
2.子育て世代
3.健康志向
4.アウトドア志向
5.インドア志向
6.シニア
###
この前提で、以下の人物(アンケート回答結果)をどのペルソナに分類するべきでしょうか?
* 分類した理由も簡潔に記載してください。
* 1人の人物のペルソナは、合致度の高い順に3つ提示してください。
* 出力フォーマットの指定には厳格に従ってください。
人物(アンケート回答結果)###
{message}
###
出力フォーマット###
マークダウンのテーブル形式で出力してください。
以下の出力例を示します。
| 順位 | ペルソナ | 理由 |
|---|---|---|
|1位|4.アウトドア志向|選択した理由をここに書く|
|2位|2.子育て世代|選択した理由をここに書く|
|3位|1.ビジネスパーソン|選択した理由をここに書く|
###
"""
return template
3.3. Bedrockによるペルソナ分類の仕組みと結果の表示方法
ソースコードの説明と重複しますが、ペルソナ分類については特別なロジックをコーディングすることなく、以下の項目をプロンプトから入力し、生成AI任せにしています。
- アンケート項目
- ペルソナ定義
- ユーザーの回答内容
- 出力形式指定 (Markdownのテーブル形式 *)
* JSONのOutputParserを使ってみましたが、若干動作が不安定なので、Markdownで書き出して、後で独自にParseすることにしました。
4. Bedrock利用のメリット
この節で記載する内容はBedrock固有ではなく、どの生成AIのモデルにも当てはまると思います。
4.1. アンケート回答の多様性対応
4.2. リソースの問題
4.3. 事前評価の難しさ
4.1. アンケート回答の多様性対応
- この記事に掲載しているアンケートの回答パターンを計算すると実に「1,476,096通り」となります
- 実際に、これだけのパターンを考慮してコーディングやテストをすると莫大な工数がかかります(現実には、設問に重みをつけてロジックを組むことになりますが、どの項目に重みをどれだけつけるか?という考慮が必要になります)
4.2. リソースの問題
- 今回はこの一連の作業に割けるヒューマンリソースが圧倒的に足りていませんでした
- 今回Bedrockを使ったことにより、マーケティング担当は他の部分(ペルソナ向けに発信する情報の整備など)に工数を割くことが可能となりました
4.3. 事前評価の難しさ
- 今回の一連の作業は一斉にアンケートを取って、事後に解析するのではなく、ある一定期間にアンケートを受け付けながら、情報発信をしていくというものです(実は現在進行形)
- そのため、事前にペルソナ分類の妥当性を評価しきれない部分があります
- やりながらプロンプトを改善していくという点で、Bedrockを使ったメリットがあったと思います
5. 結論と今後の展望
5.1. BedrockとLangChainを用いたマーケティングの成果と学び
生成AIの回答がエンドユーザーの目に直接触れるユースケースは、まだまだ躊躇があります。しかし、今回のように一旦生成AIが分析をし、次に人間のチェックや作業が入る場合には、導入の障壁が低くなると感じました。
さらにいうと、生成AIは必ずしも正しい回答を返すとは限らないので、それを前提とできる業務に対して積極的に導入していくべきと思いました。
5.2. 今後の展望と、生成系AIを活用したマーケティングの可能性についての考察
実はここから書くことはChatGPT(手が滑ってここだけChatGPTに聞いてしまいました)の受け売りですが、以下のような活用案があるとのことです。
今後も積極的にトライしていきたいと思います。
- コンテンツ生成とカスタマイゼーション
- チャットボットと顧客サービスの自動化
- 広告とプロモーションの最適化
- 市場トレンドと消費者行動の分析
- Eメールマーケティングのパーソナライゼーション