はじめに
昨年からGitHub CopilotやClineなど、IDE上でAIを活用してコーディングするツールが登場してきました。2025年にもなり、ローカルで構築したLLMやChatGPTとIDEを往復しながら開発をしている自分がそろそろ化石になってきていることに気づいたため、タイトル通りVSCode上でローカルLLMを動かせる環境を作成しました。
環境
- OS: Windows 11 Pro
- CPU: Intel(R) Core(TM) i7-14700F 2.10 GHz
- GPU: GeForce RTX™ 4070 SUPER 12GB
- WSL2: Ubuntu 22.04.3
使用ツールなど
Ollama
Meta社が公開した大規模言語モデル「Llama」をはじめとする各種言語モデルを、ローカルで簡単に実行・活用するためのオープンソースツールです。手軽に大規模言語モデルを利用できるため、とても便利です。かなりメジャーなツールなので詳しい説明は割愛します。
Qwen2.5-Coder
今回使用するLLMのモデルです。中国のAlibabaグループが開発したコーディング特化モデルで、昨年の2024年11月12日にリリースされました。パラメータ数320億のこのモデルは、GPT-4oに匹敵するとされるデータもあります。
- GitHub: https://github.com/QwenLM/Qwen2.5-Coder
- Huggingface: https://huggingface.co/Qwen/Qwen2.5-Coder-32B-Instruct
Continue
Visual Studio Codeの拡張機能で、GitHub Copilotのようにコード補完や自然言語での指示が可能なAIアシスタントです。今回はローカルのLlamaを使用していますが、他の多種多様なモデルも使用可能です。
構築手順
1. Ollamaのインストール
以下のコマンドでインストールします。
$ curl -fsSL https://ollama.com/install.sh | sh
※sudo権限で実行してください。
>>> Downloading Linux amd64 bundle
>>> Creating ollama user...
>>> Adding ollama user to render group...
>>> Adding ollama user to video group...
>>> Adding current user to ollama group...
>>> Creating ollama systemd service...
>>> Enabling and starting ollama service...
Created symlink /etc/systemd/system/default.target.wants/ollama.service → /etc/systemd/system/ollama.service.
>>> Nvidia GPU detected.
>>> The Ollama API is now available at 127.0.0.1:11434.
>>> Install complete. Run "ollama" from the command line.
Nvidia GPU detectedと表示されれば、GPUが認識されています。GPUがない場合でも軽量なモデルを使えば問題ありません。
2. モデルのインストール
とりあえずデカいものという精神で最大パラメータ数のモデルを試してみます。
$ ollama run qwen2.5-coder:32b
インストール時に19GBほどのデータがダウンロードされます。デカい。
pulling manifest
pulling ac3d1ba8aa77... 100% 19 GB
...
success
成功するとCLI上で対話が始まります。終了するにはCtrl + Dを押してください。
3. Continueのインストールと設定
VSCodeの拡張機能タブでContinueを検索し、インストールします。
左側のアイコンをクリックすると設定画面が開きます。

初期状態ではClaudeが選択されていますが、チャット部分下部のモデル名をクリックしてAdd Chat Modelを選びます。
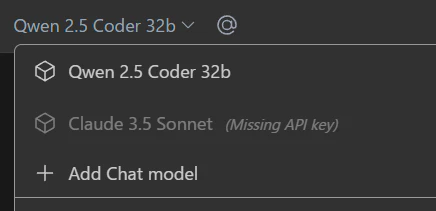
表示されたダイアログでOllamaとqwen2.5-coder:32bを設定すれば完了です。
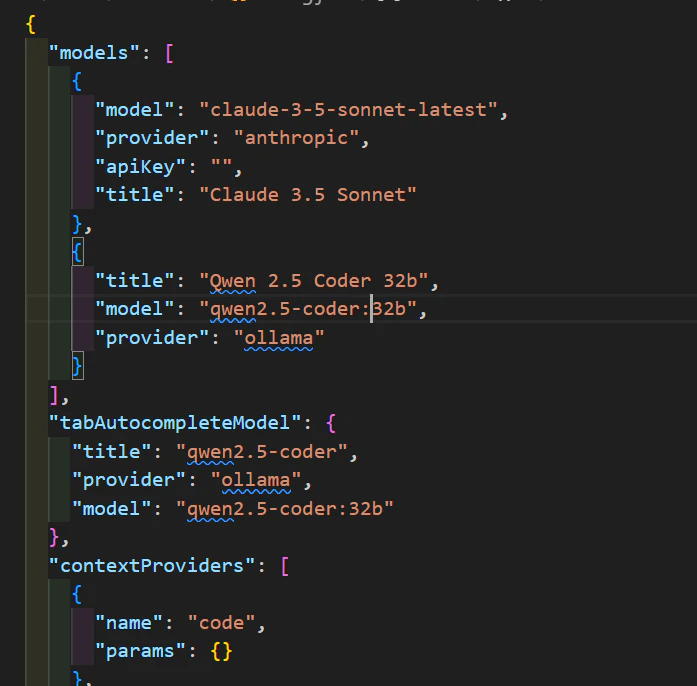
※注意点
実行時に404エラーが発生した場合、画面右下のContinueボタンを押し、Configure autocomplete optionsを選んで設定ファイルconfig.jsonを編集してください。
私の導入時は発生しました。
デフォルトではこのようになっています。
"model": "qwen2.5-coder-32b"
これを以下のように修正します。
"model": "qwen2.5-coder:32b"
修正後、正常に動作するようになります。
動作確認
無茶振りします。
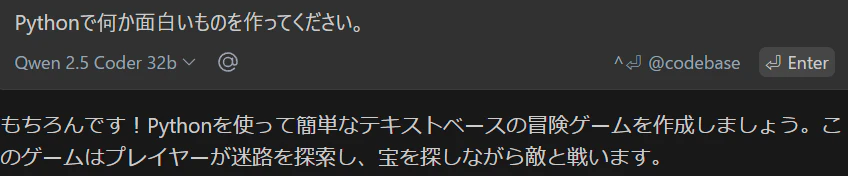
出力結果
import random
class Enemy:
def __init__(self, name, health):
self.name = name
self.health = health
def attack(self):
damage = random.randint(5, 10)
print(f"{self.name}はあなたを攻撃して{damage}のダメージを与えました!")
return damage
class Player:
def __init__(self, name, health):
self.name = name
self.health = health
def attack(self, enemy):
damage = random.randint(10, 20)
print(f"{self.name}は{enemy.name}を攻撃して{damage}のダメージを与えました!")
enemy.health -= damage
def heal(self):
heal_amount = random.randint(5, 15)
self.health += heal_amount
print(f"あなたは回復しました。+{heal_amount} HP")
def main():
player_name = input("冒険者の名前は何ですか? ")
player = Player(player_name, 100)
enemy_names = ["ゴブリン", "ドラゴン", "ゾンビ"]
enemies = [Enemy(name, random.randint(20, 30)) for name in enemy_names]
print(f"\nこんにちは、{player.name}。あなたの冒険が始まります。\n")
while True:
action = input("何をしますか? (attack/heal/run): ").strip().lower()
if action == 'attack':
enemy = random.choice(enemies)
print(f"\nあなたは{enemy.name}と戦います。")
player.attack(enemy)
if enemy.health > 0:
damage_taken = enemy.attack()
player.health -= damage_taken
if player.health <= 0:
print("あなたは倒れました...")
break
elif action == 'heal':
player.heal()
elif action == 'run':
print("逃げ出した!")
continue
else:
print("無効な選択です。もう一度試してください。\n")
if player.health > 0:
print(f"あなたのHP: {player.health}")
print("\nゲームオーバー。\n")
if __name__ == "__main__":
main()
実行すると以下のような結果が得られます。

上記の出力時間は1分半程度と、ChatGPTなどの生成時間と比べると長いものの実用的だと思います。
GPUもフルで使用されるものの、ファンが猛回転したりということはないので安心しました。
おわりに
Llamaとモデルの導入、拡張機能のインストール・設定のみで環境を構築できたため、とても手軽でした。今回、個人開発用に構築しましたが、業務での利用も視野に入れ、特に機密情報の漏洩リスクを避けたい方におすすめです。