山形には地方が4つ
Twitterでこんな記事を見た。
多民族国家・山形の地域別言語比較です。ご査収ください。 pic.twitter.com/8eeXGNe479
— そ (@g_glider0714) 2016年9月26日
山形県には村山、置賜、最上、庄内の4つの地方があり、それぞれ山形市、米沢市、新庄市、酒田/鶴岡市が中心都市である。(酒田と鶴岡はほら、ツインシティだから・・・)
庄内は他の3つの地方とは山で隔てられていて1つだけ海沿いである。当然言語も庄内とそれ以外に分かれてるんだろうと思ったら、なんかそうでもないようだった。面白そうなので、どの地方が言語的に近いのか測ってみようじゃないか。
どうやって測るか
それぞれの標準語について、4つの地方の単語の音声学的な近さを測ればよい。それには、単語を音素表記して、音素列同士の近さを測り、それをすべての項目について足し合わせればよいだろう。
データの準備
元のデータが画像だったので、泣きながら入力した。Yamagata.csv
yam <- read.csv("http://aitoweb.world.coocan.jp/data/Yamagata.csv",as.is=T,fileEncoding="UTF-8")
音素表記
こんなこともあろうかと、カタカナを音素のベクトルに変換するR packageを作っておいたのじゃ。
> library(devtools)
> install_github("akinori-ito/kana2phone")
> kana2phone("ツクッテオイタノジャ")
[1] "ts" "u" "k" "u" "q" "t" "e" "o" "i" "t" "a" "n" "o" "j" "a"
音素ベクトル間距離
こういうときはレーベンシュタイン距離を使うのが定番だろう。Rにはレーベンシュタイン距離を測る関数がいくつかあるが、残念ながら文字列用なのだ。音素は1音素1文字ではないので、1音素1文字に無理やり変換して文字列間のレーベンシュタイン距離を測るか、自前でレーベンシュタイン距離を測る関数を書くかのどちらかだ。自前で距離関数を書くのも難しくないのだが、怠けて前者のアプローチで行くことに。
1音素1文字にするために、"sh"=>"S"みたいな変換を定義する。ついでに話を簡単にするため、hashパッケージを使う(listを使うだけでもよかったかも)。
library(stringr)
library(hash)
phn <- str_split("N a a: i i: u u: e e: o o: w y b by ch d f g gy h hy j k ky m my n ny p py q r ry s sh t ts z"," ")[[1]]
str <- str_split("NaAiIuUeEoOwybBCdfgGhHjkKmMn=pPqrRsStTz","")[[1]]
phn2str <- hash(phn,str)
こんな感じでカタカナから1音素1文字の音素列に変換可能。
> paste(sapply(kana2phone("シャチョーサン"),function(x){phn2str[[x]]}),collapse="")
[1] "SaCOsaN"
レーベンシュタイン距離を求めるのはadist()。文字ベクトルを与えると、全部の組み合わせの距離を測ってくれる。便利だね。
> adist(c("abc","ade","bcd"))
[,1] [,2] [,3]
[1,] 0 2 2
[2,] 2 0 3
[3,] 2 3 0
これを使って距離を蓄積する。
dst <- matrix(0,4,4)
rownames(dst) <- colnames(dst) <- names(yam)[2:5]
for (k in 1:nrow(yam)) {
s <- rep("",4)
for (i in 1:4) {
s[i] <- paste(sapply(kana2phone(yam[k,i+1]),function(x){phn2str[[x]]}),collapse="")
}
dst <- dst+adist(s)
}
クラスタリング
相互の距離がわかればクラスタリングができる。ここではstatsパッケージのhclustを使おう。
library(stats)
d <- as.dist(dst)
h <- hclust(d)
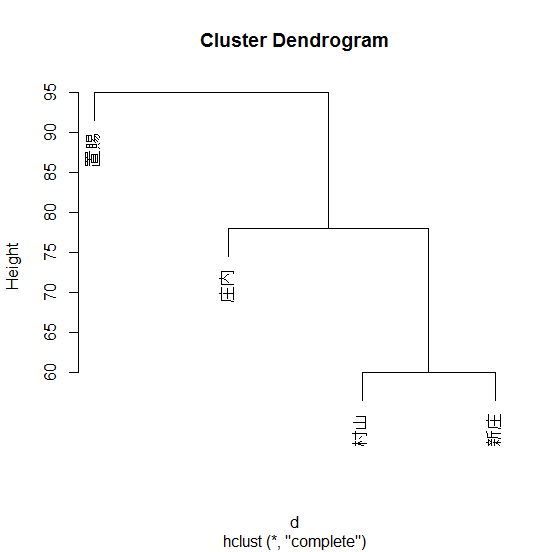
plot(h)
表示されるデンドログラムがこちら。意外にも村山と置賜より村山と庄内のほうが近い。米沢・・・
(おわり)