Rで使えるNon-realtime Voice Activity Detection: vadeR を書いたのでメモ。
アルゴリズム
普通のVADは音声認識や電話の前処理なのでリアルタイム処理が前提だが,Rでリアルタイム性を気にしてもしょうがないので,非リアルタイムを前提にこんな感じのアルゴリズムにしてみた。
1. 入力音声をMFCCに変換
2. MFCC系列をk-meansでいくつかのクラスタに分け(デフォルトは3),入力をベクトル量子化する。
3. コードベクトルのうちパワーが最小のものを無音区間だとみなす。
4. 無音区間と音声区間の長さにしきい値を設け,短い区間は直前の区間に統合
これだけだ。最後の統合がめんどくさいが,本質的な部分はこんなコードで書ける。下記のコードでは,各フレームが音声区間かどうかが変数vadに格納される。
R
library(tuneR)
x <- readWave("speechfile.wav")
mfc <- melfcc(x)
cl <- kmeans(mfc,3)
sil <- which.min(cl$centers[,1])
vad <- cl$cluster!=sil
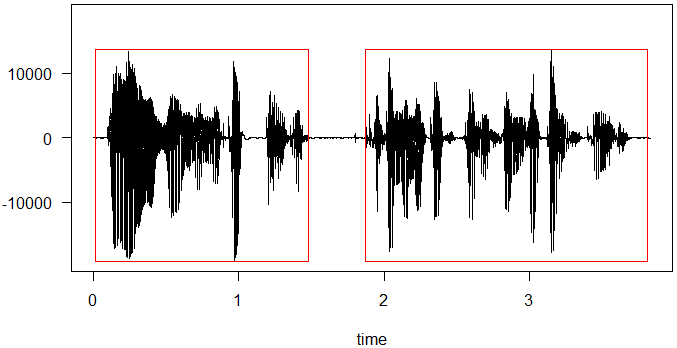
非常に単純なアルゴリズムであるが,それなりに動く。動作例はこんな感じ。