この記事の他にも,ロボティクスの辞書 に様々なロボティクスに関する記事をまとめていますので、よろしければそちらもご覧ください!
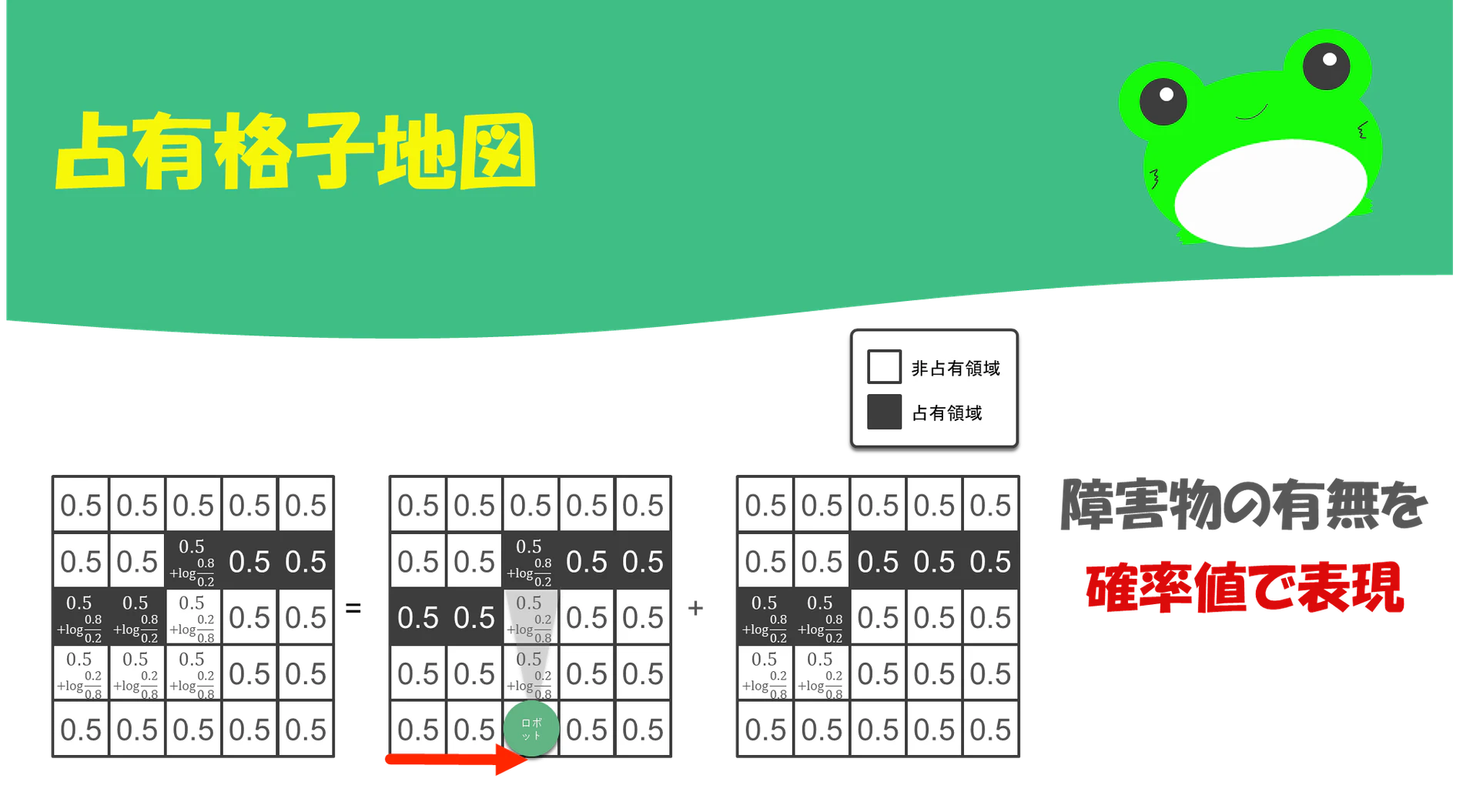
占有格子地図(occupancy grid map)とは?
占有格子地図(占有グリッドマップとも呼ばれる)とは、
環境を格子(grid)状に分割した時に、各セル内が占有されているか否か(=障害物があるか否か)を表現した地図
です。
この際、各セルは「占有=1」or「非占有=0」のどちらかになりますが、占有格子地図では
- 各セルが占有されているか否かを確率的に表す
ということをやっています。例えば、あるセルが占有されている確率が0.8の場合、そのセルには
- 80%の確率で障害物がある
ということになります。
各セルが占有されている確立は、lidar等から得られるセンサ値$z$
($z=0$(障害物なし)、$z=1$(障害物あり)の2値)
を元に推定されます。

「センサから障害物があるか否かの情報が得られているのだから$z$をそのまま採用すればよいのでは?」と思う方もいるかもしれません。
しかし、センサにはノイズが発生するため、ある時刻$t$に「$z_t=1$という観測値が得られたけど、実際は障害物が無かった」という状況(その逆もしかり)があるかもしれません。
そこで、「確率」の登場です。
以下の2パターンの例を考えて見ましょう。
- パターン1:1時刻だけ$z_t=1$と認識された場合
- パターン2:10時刻連続で$z_t=1$と認識された場合

パターン1と2を比べると、直感的にも「パターン2のほうが障害物がある確率が高そう」と予測できます(パターン1はノイズの可能性がありそう)。
占有格子地図でも同様の考え方で地図が更新され、「パターン1の方がセルが占有されている確立が低く」 なり「パターン2の方がセルが占有されている確立が高く」なります。
占有格子地図を使用すると、移動ロボットが障害物を避けながら走行をしたい場合などに、より安全に走行することが可能になります。
例えば、
- 占有されている確立が0.8以上ならば、その領域には障害物があるとみなす
- 占有されている確立が0.2未満ならば、その領域には障害物がないとみなす
といった閾値を設けることで障害物の有無を判定することができます。
また、「安全性を高めたいので閾値を厳し目に設定する」など閾値を変更することで、状況に応じた柔軟な地図作成を行うこともできます。
数式を読み解く
ここまでの考え方を数式で表現してみます。
バイナリベイズフィルタ
最初に地図全体の話をする前に、ロボットが環境をセンシングした時に得られる「センサ値$z$」より「障害物の有無」を推定する方法である
- バイナリベイズフィルタ
について説明したいと思います。

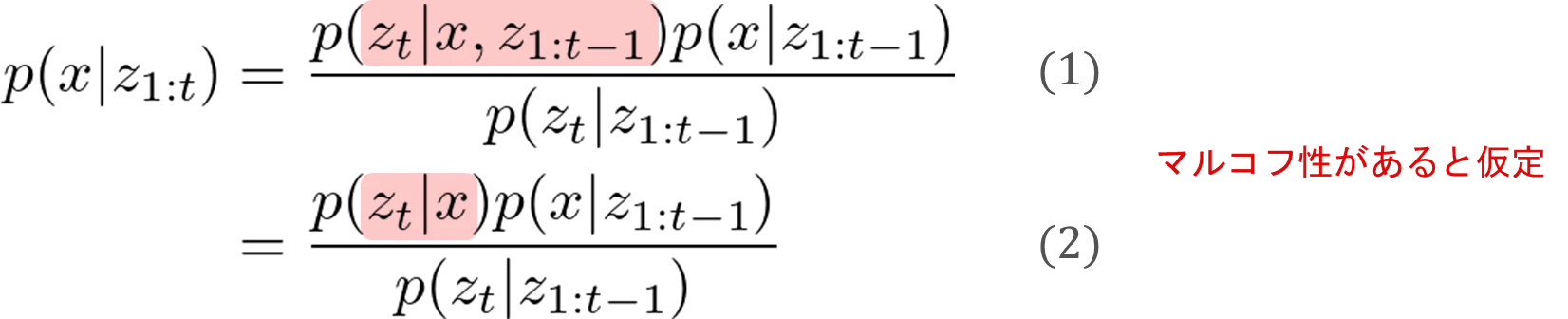
「現時刻までのセンサ値 $z_{1:t}$」という条件のもとで「障害物が存在する状態$x$」である確率(=センサ値を元に障害物の有無を推定)は、式(1)で表すことができます。
p(x|z_{1:t}) = \frac{p(z_t|x, z_{1:t-1})p(x|z_{1:t-1})}{p(z_t|z_{1:t-1})} \tag{1}
ここで式(1)の$p(z_t|x, z_{1:t-1})$にマルコフ性がある(現在のセンサ値は、過去のセンサ値にまったく依存しない)と仮定すると、式(1)は式(2)のように変換されます。
p(x|z_{1:t}) = \frac{p(z_t|x)p(x|z_{1:t-1})}{p(z_t|z_{1:t-1})} \tag{2}
ここで、実際にはマルコフ性はないことに注意してください.しかし,ここではマルコフ性がある前提で話を進めます。
ここで,式(2)の $p(z_t|x)$ に着目してみます.
これは,「障害物が存在する状態 $x$」という条件のもとで「観測値 $z$」である確率を求めています(=障害物の有無の状態からセンサ値を推定).

しかし,実際の状況を想定すると下図のように「センサ値 $z$(既知)」を元に「障害物が存在する状態 $x$(未知)」である確率を求めるという順番であり, $p(z_t|x)$ とは逆です.
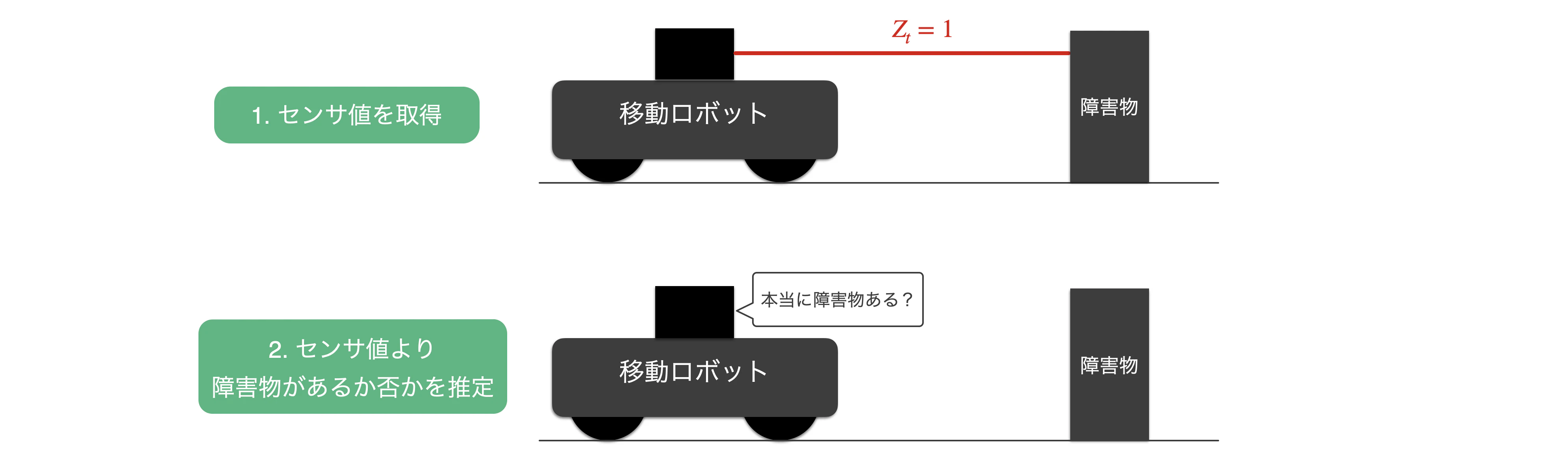
そこで,ベイズの定理により式(2)を式(3)に変換します.
p(x|z_{1:t}) = \frac{p(x|z_t)p(z_t)}{p(x)} \frac{p(x|z_{1:t-1})}{p(z_t|z_{1:t-1})} \tag{3}

上記のように
「センサ値 $z_t」$から「障害物が存在する状態 $x$」であるかを推定をするようなモデルは
測定値(出力)である「センサの観測値$z$」から逆算して「障害物が存在する状態 $x$」である確率を求めるため
- inverse sensor model
と呼ばれています。
次に,求めた式(3)を式(4)のオッズ1の形にします.
\begin{align}
\frac{p(x|z_{1:t})}{1-p(x|z_{1:t})} &= \frac{p(x|z_t)}{1-p(x|z_t)} \frac{1-p(x)}{p(x)} \frac{p(x|z_{1:t-1})}{1-p(x|z_{1:t-1})} \frac{p(z_t|z_{1:t-1})}{p(z_t|z_{1:t-1})}\\
&= \frac{p(x|z_t)}{1-p(x|z_t)} \frac{1-p(x)}{p(x)} \frac{p(x|z_{1:t-1})}{1-p(x|z_{1:t-1})} \tag{4}
\end{align}
そして、式(4)のlog(対数)を取った式(5)の形にします。
\begin{align}
\log\frac{p(x|z_{1:t})}{1-p(x|z_{1:t})}
&= \log \frac{p(x|z_t)}{1-p(x|z_t)} \frac{1-p(x)}{p(x)} \frac{p(x|z_{1:t-1})}{1-p(x|z_{1:t-1})} \\
& = \log\frac{p(x|z_t)}{1-p(x|z_t)} + \log\frac{1-p(x)}{p(x)} + \log\frac{p(x|z_{1:t-1})}{1-p(x|z_{1:t-1})} \tag{5}
\end{align}
ここで、式(5)の 「対数オッズ $\log\frac{p(x|z_{1:t})}{1-p(x|z_{1:t})}$」 を $l_t(x)$ に置き換えます(式(6))(単に、文字に置き換えただけです)。
\begin{align}
l_t(x) = \log\frac{p(x|z_t)}{1-p(x|z_t)} + \log\frac{1-p(x)}{p(x)} + l_{t-1}(x) \tag{6}
\end{align}
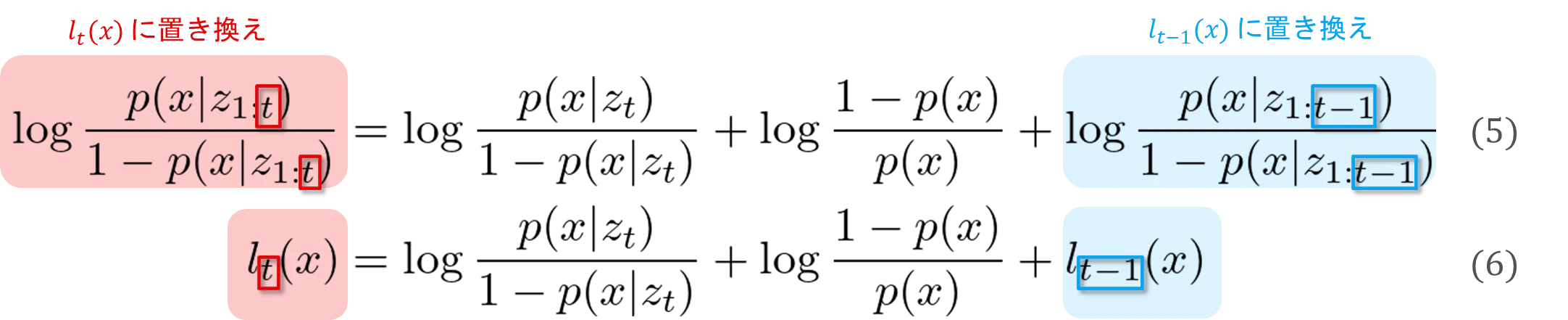
式(6)で完成でも良いのですが、以降で式の説明が若干しづらいので式(6)を式(7)のように変形します(式の意味としては式(6)と全く同じです。)。
\begin{align}
l_t(x) &= \log\frac{p(x|z_t)}{1-p(x|z_t)} + l_{t-1}(x) - \log\frac{p({x})}{1-p(x)} \tag{7}
\end{align}
-
$l_t(x)$:「現時刻までのセンサ値$z_{1:t}$」から推定した「障害物が存在する $x$」である確立の対数オッズ
-
$\log\frac{p(x|z_t)}{1-p(x|z_t)}$:「現時刻のセンサ値$z_{t}$」から推定した「障害物が存在する $x$」である確立の対数オッズ
-
$l_{t-1}(x)$:1時刻前の $l_t(x)$
-
$\log\frac{p({x})}{1-p(x)}$:「障害物が存在する $x$」である確立の対数オッズ(事前確立)
オッズのlogを取ったものは、「対数オッズ」と呼ばれ、log(対数)の特性の1つである
- 掛け算が足し算になる
といったメリットを受けることができます。
もう少し詳しくいうと
- 確率値は0〜1の間の値なので,掛け算になると数値が小さくなりすぎて数値誤差が発生しやすい。一方でlogを取ると足し算になるので、それを防げる
- 単純に,掛け算よりも足し算の方が(コンピュータの)計算速度が速い
というメリットがあります.
また、logを取ると
- 確立値の範囲である「0〜1」から「-∞〜∞」に範囲が拡張される
のも嬉しい(数値誤差の観点から)ところです。
先ほど求めた式(7)の詳細を確認してみましょう(再掲)。
\begin{align}
l_t(x) &= \log\frac{p(x|z_t)}{1-p(x|z_t)} + l_{t-1}(x) - \log\frac{p({x})}{1-p(x)} \tag{7(再掲)}
\end{align}
まず右辺の1項目 $\log\frac{p(x|z_t)}{1-p(x|z_t)}$ は
- 「現時刻のセンサ値 $z_t$」を元に「障害物の有無」を推定しています。
しています。
今回 $z_t$ は2種類の値を取るので,パターンとしては以下の2種類になります。
- $p(x|z_t=0)$:$z_t=0$ の時に「障害物が存在する状態 $x$」である確率
- $p(x|z_t=1)$:$z_t=1$ の時に「障害物が存在する状態 $x$」である確率
それぞれの確率はセンサの性能や環境によって変わります.そのため,実環境で使用する場合は,実際のセンサを使ってみて上記の2つの確率を事前に調べておく必要があります.
次に,2項目 $l_{t-1}(x)$ は
- 1時刻前の対数オッズ
となります。
最後に,3項目 $\log\frac{p({x})}{1-p(x)}$ についてです.これは
- 事前確率
になります。
例えば、最初の時点(センシングするより前の時点)で障害物の有無がある程度わかっている場合は、障害物付近の確率値を予め高く設定しておくことができると思います。

しかし、「予め確立を高く設定した領域」と「そうでない領域」を同じように更新してしまうと、「予め確立を高く設定した領域」の $l_t(x)$ が高くなりすぎてしまいます。
そこで、 $\log\frac{p({x})}{1-p(x)}$ を引くことで、 バランスを取るイメージです。
(「予め確立を低く設定した領域」の場合は、3項目がプラスになるのでこの逆の考え方になります)
逆に、事前情報が全くない場合は「障害物がある確立 $p(x)$」と「障害物がない確立 $1-p(x)$」が同じになるので
$$
\log \frac{p(x)}{1-p(x)} = \log \frac{0.5}{0.5} = 0
$$
となり、3項目は無視することができる、すなわち1項目のセンサ値のみを用いて「障害物の有無」を推定することになります。
実際に、最後のまとめで紹介するソースコードでは3項目が省略された形で実装されています。
ここまでの説明をもとに、式(7)を,わかりやすいイメージで言い換えてみると(厳密には対数オッズですが)
「新しい(=現時刻までの)障害物の有無の確率($1:t$)」=
「現時刻のセンサ値から推定された障害物の有無の確率($t$)」
+ 「1時刻前までの障害物の有無の確率($1:t-1$)」
- 「(事前確率)」
ということになります。
以降の、占有格子地図でも同じような式が出てきますが、その際は図付きで説明しているので、そちらの方がイメージが湧きやすいかもしれません。
この時点でイメージが浮かばない方は、とりあえず先を読み進めてみてください。
占有格子地図
ここからは、本題である占有格子地図の話に入っていきます。
最初に、以下の格子地図における表現のバリエーションを考えてみましょう。
地図は「2×2=4のセル」をもっており、各セルは、「0か1の2種類の状態」をもつため、考えられる地図のパターンは$2^4=16$パターンになります。
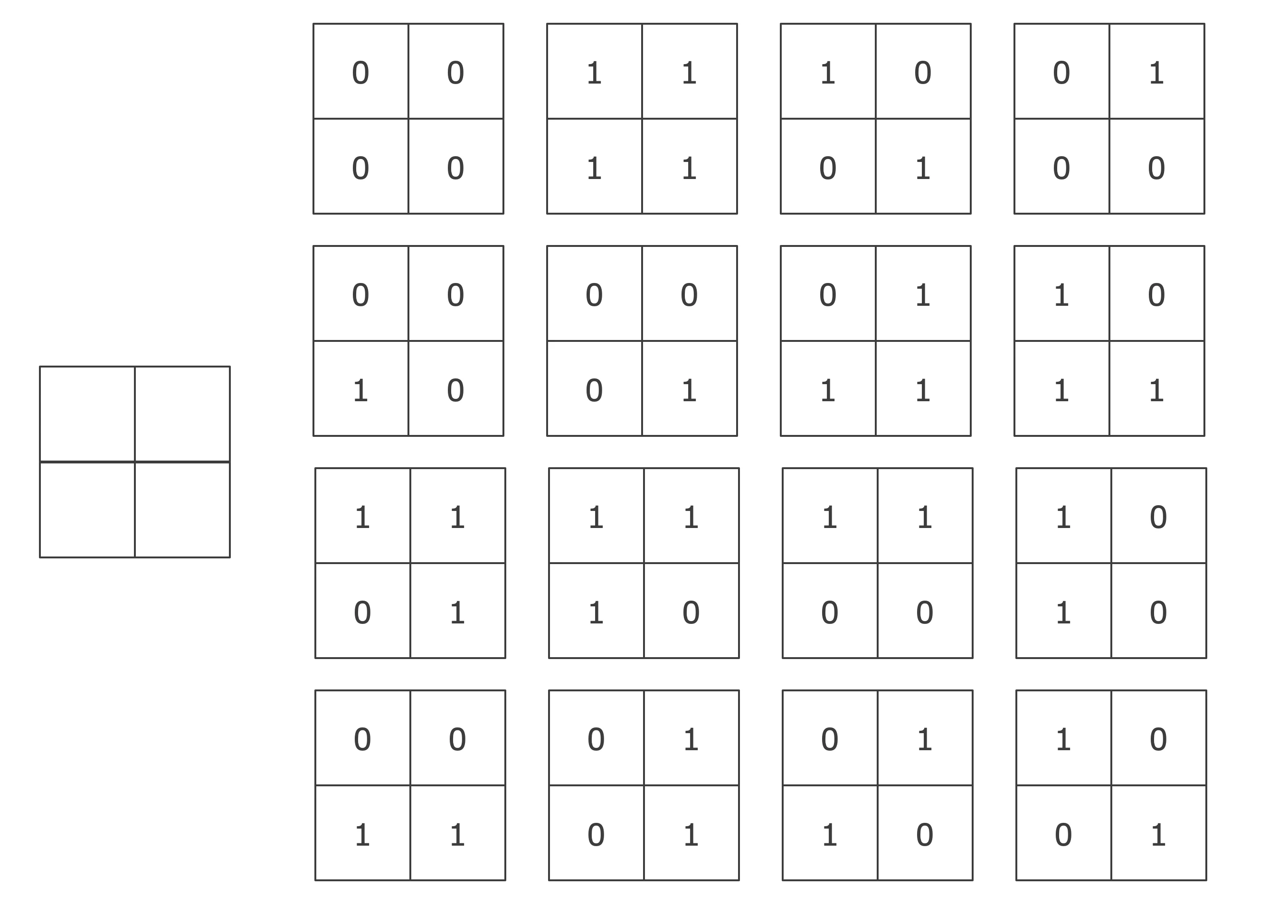
これを一般化してみましょう。マップ$m$のセル数を$|m|$とすると、$|m|$個のセルをもつ地図の表現のパターンは「$2^{|m|}$パターン」になります。
$|m|$に適当な値を入れてみればわかると思いますが、この場合$|m|$を少し大きくしただけで$2^{|m|}$の値は爆発的に大きくなってしまいます(次元の呪い)。
そこで、「各セルが独立している」という仮定のもと各セルが占有されている確立を求めることにしましょう。
「各セルが独立している」というのは正しくありません。
なぜなら、現実の環境は連続的であるためセルをまたぐように障害物が存在することは当たり前のようにあるからです。
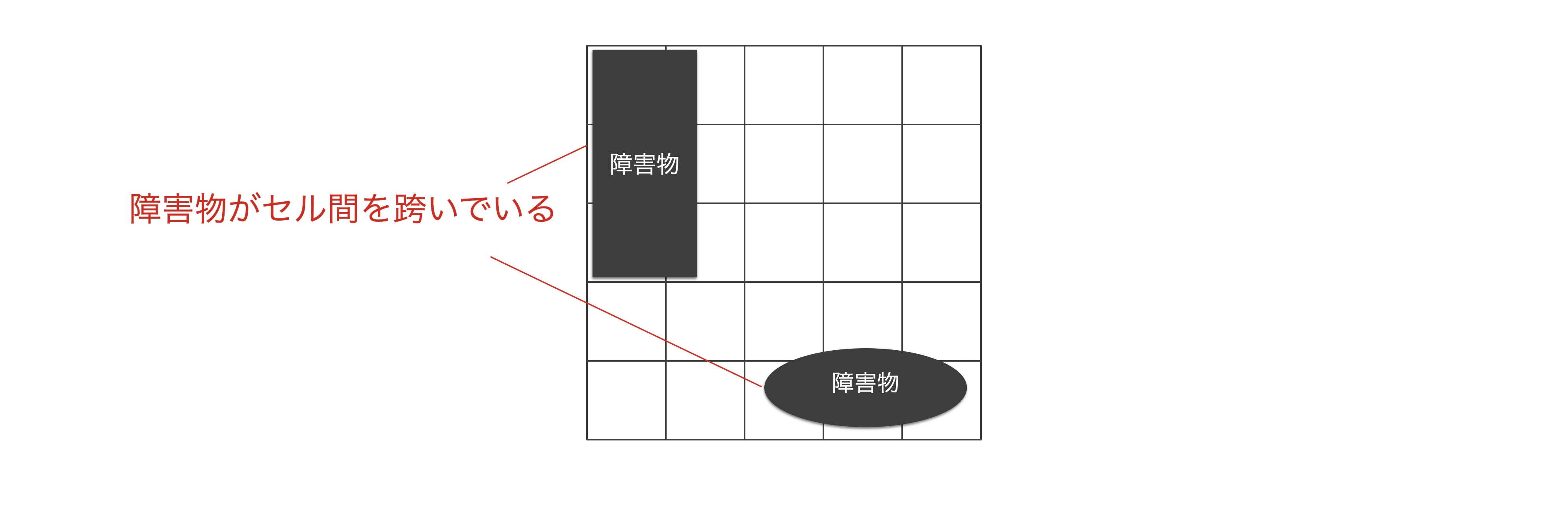
しかし、「各セルが独立している」と考えたほうが都合が良いのでここではそのように考えます。
各セルにおいて、「占有されている確率」と「占有されていない確率」の2パターンを考えるとすると必要な計算量は$2|m|$になり、これは$|m|$をある程度増やしても現実的な計算量になります。
そして、全てのセルは独立であると仮定しているため、式(9)のように表すことができます2。
p(m|z_{1:t},x_{1:t}) = \prod_{i}p(\boldsymbol{\rm{m}}_i|z_{1:t}, x_{1:t}) \tag{8}
-
$m$: 地図全体
-
$\boldsymbol{\rm{m}}_i$: $i$番目のセル
-
$z_{1:t}$:現時刻までのセンサ値
-
$x_{1:t}$:現時刻までのロボットの経路
- 姿勢のシーケンスとして表現。2次元平面ロボットの場合、$x_t=(x,y,\theta)^{\top}$
- 前節で紹介した 「障害物が存在する状態 $x$」 とは意味が違うことに注意してください
-
$p(\boldsymbol{\rm{m_i}} |z_{1:t}, x_{1:t})$:「現時刻までのセンサ値 $z_{1:t}$」と「現時刻までの姿勢 $x_{1:t}$」から推定された「$i$ 番目のセル」が占有されている確立

ここで、式(8)の「$i$ 番目のセルが占有されている確立 $p(\boldsymbol{\rm{m_i}} |z_{1:t}, x_{1:t})$」 の対数オッズをとった式は、前節で紹介したバイナリベイズフィルタの式(7)を用いて式(9)のように記述できます。
l_{t,i} = \log\frac{p(\boldsymbol{\rm{m}}_i|z_{t}, x_{t})}{1-p(\boldsymbol{\rm{m}}_i|z_{t}, x_{t})} + l_{t-1, i} - \log\frac{p(\boldsymbol{\rm{m}}_i)}{1-p(\boldsymbol{\rm{m}}_i)} \tag{9}
-
$l_{t,i}$:「現時刻までのセンサ値 $z_{1:t}$」と「現時刻までの姿勢 $x_{1:t}$」から推定された「$i$ 番目のセル」が占有されている確立の対数オッズ
-
$\frac{p(\boldsymbol{\rm{m_i}}|z_{1:t}, x_{1:t})}{1-p(\boldsymbol{\rm{m_i}}|z_{1:t}, x_{1:t})}$:「現時刻のセンサ値 $z_{t}$」と「現時刻の姿勢 $x_{t}$」から推定された「$i$ 番目のセル」が占有されている確立の対数オッズ
-
$l_{t-1,i}$:1時刻前の $l_{t, i}$
-
$\frac{p(\boldsymbol{\rm{m_i}})}{1-p(\boldsymbol{\rm{m_i}})}$:「$i$ 番目のセル」が占有されている確立の対数オッズ(事前確立)
-
$z_{1:t}$:現時刻までのセンサ値
-
$x_{1:t}$:現時刻までのロボットの経路
- 姿勢のシーケンスとして表現。2次元平面ロボットの場合、$x_t=(x,y,\theta)^{\top}$
ここで、 $l_{t,i}$ は「$i$ 番目のセルが占有されている確立 $p(\boldsymbol{\rm{m_i}} |z_{1:t}, x_{1:t})$」そのものではなく、$p(\boldsymbol{\rm{m_i}} |z_{1:t}, x_{1:t})$の対数オッズであることに注意してください。
式(9)を,わかりやすいイメージで言い換えてみると
「新しい(=現時刻までの)占有格子地図($1:t$)」=
「現時刻のセンサ値 $z_t$とロボットの姿勢 $x_t$から推定された占有格子地図($t$)」
+ 「1時刻前までのセンサ値 $z_{1:t-1}$と1時刻前までのロボットの姿勢 $x_{1:t-1}$から推定された占有格子地図($1:t-1$)」
- 「(事前確率)」

(上図では、3項目の「事前確立」は書いていません。)
ここまでで、占有格子地図における更新式を求めることができました。
式(9)は対数オッズであり、「$i$ 番目のセルが占有されている確立 $p(\boldsymbol{\rm{m_i}}|z_{1:t}, x_{1:t})$」そのものではないので、値の範囲は「-∞〜∞」になります。
前述したように、計算するときは対数オッズの形の方が扱いやすいですが、結果を人間が可視化する際は、「0〜1」の範囲である確立値の方が直感的にわかりやすいです。
そこで、式(10)を用いることで、対数オッズを確立値に変換することができます。
p(\boldsymbol{\rm{m}}_i|z_{1:t}, x_{1:t}) = 1-\frac{1}{1+\exp\{l_{t, i} \}} \tag{10}
-
$p(\boldsymbol{\rm{m_i}}|z_{1:t}, x_{1:t})$: 「現時刻までのセンサ値 $z_{1:t}$」と「現時刻までの姿勢 $x_{1:t}$」から推定された「$i$ 番目のセル」が占有されている確立
-
$l_{t, i}$:「現時刻までのセンサ値 $z_{1:t}$」と「現時刻までの姿勢 $x_{1:t}$」から推定された「$i$ 番目のセル」が占有されている確立の対数オッズ
占有格子地図を更新する具体例
ここからは、式(9)に実際の数値を当てはめてみて、占有格子地図がどのように更新されていくのかを確認してみましょう。
ここでは、式(9)の3項目にあたる「事前確率 $ \log\frac{p(\boldsymbol{\rm{m_i}})}{1-p(\boldsymbol{\rm{m_i}})}$」を考慮するとわかりにくくなるので、 $ \log\frac{p(\boldsymbol{\rm{m_i}})}{1-p(\boldsymbol{\rm{m_i}})} = \log\frac{0.5}{0.5} = 0$ である例を説明します。
まず、$z_t=1$ の時は、
「セルが占有されていない状態である確率 $1 - p(\boldsymbol{\rm{m_i}}|z_{t}, x_{t})$」 < 「セルが占有されている状態である確率 $p(\boldsymbol{\rm{m_i}}|z_{t}, x_{t})$」
になるので、それぞれを $p(\boldsymbol{\rm{m_i}}|z_{t}, x_{t}) = 0.8, 1 - p(\boldsymbol{\rm{m_i}}|z_{t}, x_{t}) =0.2$ とすると
- 1時刻目:$l_{t,i} = \log\frac{0.8}{0.2} + 0.0 \fallingdotseq 1.39$
- 2時刻目:$l_{t,i} = \log\frac{0.8}{0.2} + 1.39 \fallingdotseq 2.77$
- 3時刻目:$l_{t,i} = \log\frac{0.8}{0.2} + 2.77 \fallingdotseq 4.15$
と対数オッズが上昇していきます。
これを、式(10)により確率値に変換すると
0.80 → 0.94 → 0.98
と徐々に「セルが占有されている確率 $p(\boldsymbol{\rm{m_i}}|z_{1:t}, x_{1:t})$ 」が上昇していることがわかります。

逆に$z_t=0$ の時は、
「セルが占有されている状態である確率 $p(\boldsymbol{\rm{m_i}}|z_{t}, x_{t})$」 < 「セルが占有されていない状態である確率 $1 - p(\boldsymbol{\rm{m_i}}|z_{t}, x_{t})$」
になるので、それぞれを $p(\boldsymbol{\rm{m_i}}|z_{t}, x_{t}) = 0.2, 1 - p(\boldsymbol{\rm{m_i}}|z_{t}, x_{t}) =0.8$ とすると
- 1時刻目:$l_{t,i} = \log\frac{0.2}{0.8} + 0.0 \fallingdotseq -1.39$
- 2時刻目:$l_{t,i} = \log\frac{0.2}{0.8} + (-1.39) \fallingdotseq -2.77$
- 3時刻目:$l_{t,i} = \log\frac{0.2}{0.8} + (-2.77) \fallingdotseq -4.15$
と対数オッズが減少していきます。
これを、式(10)により確率値に変換すると
0.20 → 0.06 → 0.01
と徐々に「セルが占有されている確率 $p(\boldsymbol{\rm{m_i}}|z_{1:t}, x_{1:t})$ 」が減少していることがわかります。

最後に
以上が、ベイジアンフィルタによる占有格子地図の解説になります。
私も勉強中ですので、間違った解釈などがあればご教授いただけると幸いです。
また、ここまで記事をご覧になった方の中には「実際のプログラムで試してみたい!」という方もいると思います。私自身も時間があれば、自作に挑戦したいと思っているのですが、現時点では作成できていないので、下記のpythonコードをおすすめしたいと思います。
https://gist.github.com/superjax/33151f018407244cb61402e094099c1d
こちらのコードでは、センサ値のみを用いて地図を更新しており $l_{t, i}(x)$ の3項目に相当する部分は含まれていないので注意してください。
ロボティクスに興味のある方のお役に少しでも立てたら幸いです。
参考サイト、文献
- Occupancy Maps:基本的に、こちらの文献をもとに作成しました。
- Sebastian Thrun (著), Wolfram Burgard (著), Dieter Fox (著), 上田 隆一 (翻訳) (2016/9/21) 確率ロボティクス (プレミアムブックス版):ロボティクスの名著です。上記文献で理解しきれなかった部分を補足する形で読まさせていただきました。
-
オッズ:事象の起こりやすさを表す指標のことで、「ある事象が起こる確率$p$」を「その事象が起こらない確率$1-p$で割ったもの」として定義されます。 起こる確率と起こらない確率が同じときにオッズの値は1となり、1よりも大きいと事象が起こりやすい、小さいと起こりにくいことを表します。 ↩
-
独立同一分布(i.i.d.)において、各確率は総乘の形で表すことができます。参考:独立同一分布(i.i.d.)に従うってどういうことなんだ ↩