僕の周りではPythonよりもMATLABやC++で計算するという人を見ることが多い気がします.
しかし,豊富なライブラリがあるなどPythonはとても便利な言語です.
これを機に何となくの雰囲気を知ってもらえたらなと思います.
この記事はPython3やそのライブラリの使い方の概要を説明するもので,環境構築や細かい所などには触れません.
基本的な書き方
例えば,forやifはこのように書いたりします.
# range(10)は0から9までの10個の数を次々に吐き出してくれるもの
# range(0, 10)と書いてもいい
for i in range(10):
if i % 2 == 0 and i % 3 == 0:
print("FooBar")
elif i % 2 == 0:
print("Foo")
elif i % 3 == 0:
print("Bar")
else:
print(i)
コロン(”:”)とインデントによってブロックを表すところが特徴的ですね.
もちろんwhileなどもありますが,今回は省略します.
このとき,適切にインデントしないと怒られてしまいます.
# だめな例
for i in range(10):
print(i)
# IndentationError: expected an indented block
またC++のtryのような例外処理もPythonには備わっています.
a = [0, 1]
try:
print(a[2])
except IndexError as e:
print("うぎゃあ,例外が発生したよ", e.args)
# うぎゃあ,例外が発生したよ ('list index out of range',)
データ構造
Pythonにはいわゆる配列やハッシュみたいなものが組み込みで入っています.
今回はリストと辞書を紹介します.
ざっと見ていきましょう.
リスト(list)
中身を編集可能な可変長配列です.
大カッコ(”[ ]”)で表します.
# リストの要素アクセス
a = [1, 2, 3]
a[0] = 0
print(a)
# [0, 2, 3]
# リストの結合
b = [1, 2, 3] + [4, 5, 6]
print(b)
# [1, 2, 3, 4, 5, 6]
# リストの繰り返し
c = [1] * 5
print(c)
# [1, 1, 1, 1, 1]
# 末尾挿入
d = [1, 2, 3]
d.append(4)
print(d)
# [1, 2, 3, 4]
# forにも使える
for name in ["Ichiro", "Ziro", "Saburo"]:
print(name)
# Ichiro
# Ziro
# Saburo
このようにリストは柔軟な表現ができるのですが,要素アクセスが遅いので規模の大きい計算には不向きです.
そこで,行列計算などを高速に行うために作られたのが固定サイズ配列numpy.ndarrayです.(詳しくはライブラリ紹介で)
辞書(dictionary)
これはいわゆるハッシュみたいなもので,キー(key)から値(value)を高速に呼び出すことができるものです.
キーなどの取得は次のようにできます.
# keyが名前で,valueが年齢
a = dict({"Hanako": 18, "Taro": 32, "Koziro": 88})
print(a["Hanako"])
# 18
# aのkey一覧を取得
# 順番はでたらめ
for key in a.keys():
print(key)
# Koziro
# Taro
# Hanako
# aのvalue一覧を取得
# 順番はでたらめ
for value in a.values():
print(value)
# 88
# 32
# 18
# aのkeyとvalueのペア一覧を取得
# 順番はでたらめ
for key, value in a.items():
print(key, value)
# Koziro 88
# Taro 32
# Hanako 18
辞書の編集や,要素の確認は次のようにできます.
a = dict({"Hanako": 18, "Taro": 32, "Koziro": 88})
# aから"Hanako"のデータを削除
del a["Hanako"]
print(a)
# {'Koziro': 88, 'Taro': 32}
# aに"Shiro"のデータを追加
a["Shiro"] = 55
print(a)
# {'Shiro': 55, 'Koziro': 88, 'Taro': 32}
# keyが存在するかの確認
name = "Shiro"
if name in a:
print("{} はいます!".format(name))
else:
print("{} はいません!".format(name))
# Shiro はいます!
NumPy
NumPyはPythonで使われる様々な科学計算ライブラリの中心になるライブラリです.
N次元配列,線形演算などの様々な関数がサポートされており,科学計算では色々お世話になります.
Pythonに関係するものの名前にはやたらとpyが入るんですが,PythonでPythonを実装するとこうなります.
N次元配列(ndarray)
NumPyで用いられるN次元配列です.
固定サイズで型が指定されています.
# numpyモジュールをnpという名前でインポート
import numpy as np
# リストで初期化
# dtypeを指定すると型を指定できる
a = np.array([1, 2, 3, 4, 5, 6], dtype=np.float)
print(a, a.dtype)
# [ 1. 2. 3. 4. 5. 6.] float64
# 配列を変形
b = a.reshape([2, 3])
print(b)
# [[ 1. 2. 3.]
# [ 4. 5. 6.]]
# リストを入れ子にすると多次元配列になる
c = np.array([[1, 2], [3, 4]])
print(c)
# [[1 2]
# [3 4]]
# 指定した範囲の連続した数値をとることもできる
d = np.arange(6)
e = np.linspace(0, 10)
print(d)
print(e)
# [0 1 2 3 4 5]
# [0. 0.20408163 ... 9.79591837 10.]
では実際に簡単な計算をしてみましょう!
import numpy as np
a = np.arange(4, dtype=np.float).reshape([2, 2])
# [[ 0. 1.]
# [ 2. 3.]]
b = np.ones([2, 2], dtype=np.float)
# [[ 1. 1.]
# [ 1. 1.]]
# 要素ごとの和
a + b
# [[ 1. 2.]
# [ 3. 4.]]
# 要素ごとの積
a * a
# [[ 0. 1.]
# [ 4. 9.]]
# スカラー倍
a * 2
# [[ 0. 2.]
# [ 4. 6.]]
# 要素ごとに2乗
a**2
# [[ 0. 1.]
# [ 4. 9.]]
線形演算
NumPyは線形代数に関する様々な関数をサポートしています.
import numpy as np
A = np.arange(4, dtype=np.float).reshape([2, 2])
B = np.ones([2, 2], dtype=np.float)
# 行列積 @を使った表記はPython3.5以降
A @ B
# [[ 1. 1.]
# [ 5. 5.]]
# 行列とベクトルの積もできる
x = np.array([1, 2])
y = A @ x
# [ 2. 8.]
# 連立一次方程式を解く
x_ = np.linalg.solve(A, y)
# [ 1. 2.]
特殊な要素アクセス
ちょっと特殊な要素へのアクセス方法もあります.
配列中の,特定の要素だけを取り出したいときに便利です.
a = np.array([-1, 2, 1, -5, 3, -2])
# 配列の中で,特定の範囲だけ取り出したいとき
a[1:4]
# [ 2 1 -5]
# 配列の中で,正の要素だけ取り出したいとき
mask = (a > 0)
# [False True True False True False]
a[mask]
# [2 1 3]
Matplotlib
Matplotlibは図やグラフなどをプロットするのに用いるライブラリです.
簡単に使い方を紹介します.
import numpy as np
# matplotlibからpyplotをpltという名前でインポート
from matplotlib import pyplot as plt
x = np.linspace(-2, 2)
y = x**3 / 3 - x
plt.plot(x, y)
plt.show()

import numpy as np
from matplotlib import pyplot as plt
# x, yを正規分布からサンプルする
num_points = 500
x = np.random.normal(loc=0.0, scale=2.0, size=num_points)
y = np.random.normal(loc=0.0, scale=1.0, size=num_points)
# x, y軸のスケールを同じにする
plt.axis("equal")
plt.scatter(x, y)
plt.show()
scikit-learn
最後に機械学習周りをサポートするライブラリscikit-learnを紹介します.
実際に簡単なデータでクラス分類などをしてみます.
# http://scikit-learn.org/stable/auto_examples/svm/plot_iris.html#sphx-glr-auto-examples-svm-plot-iris-py
# を参考にした
from sklearn import svm
from sklearn.datasets import load_iris
from sklearn.cross_validation import train_test_split
import numpy as np
from matplotlib import pyplot as plt
# 有名なirisデータセット
# これを使って簡単なクラス分類をしてみる
iris = load_iris()
# サンプル数×4変数 の行列
data = iris.data
print(data.shape)
# (150, 4)
# 今回は,0, 2番目の変数のみを使う
data = np.c_[data[:, 0], data[:, 2]]
print(data.shape)
# (150, 2)
# 0, 1, 2のラベルがすべてのサンプルについて割り当てられている
# 0:setosa
# 1:versicolor
# 2:virginica
# という品種に対応している
labels = iris.target
# 今回はラベル1, 2のみ使う
mask = (labels >= 1)
data = data[mask]
labels = labels[mask]
# データを訓練用,テスト用に分割する
data_train, data_test, labels_train, labels_test = train_test_split(data, labels, test_size=0.2)
# 線形サポートベクターマシンを使う
model = svm.SVC(kernel="linear")
model.fit(data_train, labels_train)
# テストデータでの正答率を計算
predictions = model.predict(data_test)
accuracy = (predictions == labels_test).mean()
print(accuracy)
# 0.9
# 毎回結果は異なる
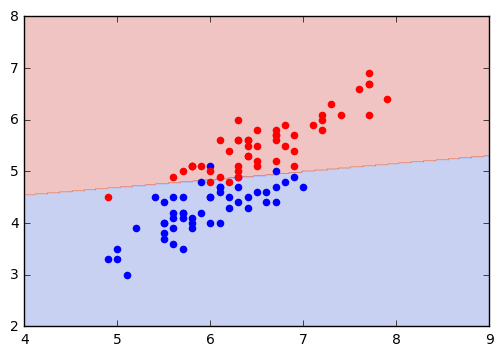
# 境界のプロット
# ごちゃごちゃですね
x_min = 4
x_max = 9
y_min = 2
y_max = 8
plt.xlim(x_min, x_max)
plt.ylim(y_min, y_max)
xx, yy = np.meshgrid(np.linspace(x_min, x_max, num=300), np.linspace(y_min, y_max, num=300))
xx_flatten = xx.flatten()
yy_flatten = yy.flatten()
zz_flatten = model.predict(np.c_[xx_flatten, yy_flatten])
plt.contourf(xx, yy, zz_flatten.reshape(xx.shape), cmap=plt.cm.coolwarm, alpha=0.3)
# データのプロット
plt.scatter(data[labels == 1, 0], data[labels == 1, 1], color="b")
plt.scatter(data[labels == 2, 0], data[labels == 2, 1], color="r")
plt.show()
最後に
いかがでしたか?
Pythonはライブラリがとても充実している便利な言語です.
今回は紹介できませんでしたが,他にも様々な便利なライブラリがあるので最後にさらっと紹介します.
SciPy
先程紹介したライブラリのうち,NumPyやMatplotlibといった科学計算ライブラリを一括りにしてSciPyといいます.
Scipyはこの他にも信号処理,積分計算,統計処理,シンボリック計算,対話的な実行環境などをサポートしています.
OpenCV
あのOpenCVもPythonから使うことが出来ます.
細かいことですが,C++では行列をCV::Matとして扱いますが,Pythonではnumpy.ndarrayをそのまま使えたりします.
Jupyter Notebook
色々コードを書き散らかして実験をしたり,コードと実行結果をhtmlにまとめたりできる便利なアプリケーションがJupyter Notebookです.
小規模なコードで色々試してみるのにはとても便利です.
JupiterではなくJupyterです.しょうもないこだわりがいいですね

深層学習まわり
深層学習に用いるライブラリTensorFlowやCaffeなどもPythonから使うことが出来る(らしいです).
深く目を通してはいませんが,U-TOKYO AP Advent Calendar 2017 3日目にCaffeの紹介みたいなものがあったので興味のある方はそちらもどうぞ!!