はじめに
本記事はARISE analytics Advent Calendar 2022の8日目です.
昨日は@tsukasaIさんの「作業中の変更を一時退避させる git stash ハンズオン」でした.
明日は@@ouerikaさんの「【Vue-CLI+Typescript+Element UI】でナビゲーションとモーダルダイアログを作成してみる」です.
GCNとは
近年,深層学習においてグラフ構造のデータを扱うGraph Neural Networkに関する研究が増えています.
GNNの中でも,グラフデータに対して画像のような畳み込み演算を行うものをGraph Convolutional Network(GCN)といいます.
GCNを提案した論文としては,[1]が挙げられることが多いようです.
GCNはグラフの隣接行列を$A$,次数行列を$D$,ノードの特徴量を$X$,モデルのパラメータを$W$として次のように表されます.
X^{(k+1)} = \sigma(D^{-\frac{1}{2}}AD^{-\frac{1}{2}}X^{(k)}W^{(k)})
GCNは重い?
実務で使うデータでは,グラフの規模が大きくモデルの推論速度やメモリ使用量が課題となるケースが多々あります.
GCNは上記の式を見ても分かるとおり,レイヤの計算にグラフの隣接行列を用いる必要があるため,推論時にはグラフ全体の情報を一度にメモリに載せる必要があります.そのため,ノード数やエッジ数が数千〜数万ともなってくる大規模なグラフとなると,学習時の試行錯誤が非常に大変になります.
では,実際のところGCNではどれくらいのグラフを扱えるのでしょうか?
実験してみようと思います.
実験してみた
実験の設定
今回はGCNの推論速度を計測するため,ノード数が10〜10000の完全グラフを用いて実際に推論させてみます.
Deep Graph Libraryを使用して簡単な分類問題を解くモデルを作成します.
class GCN(nn.Module):
def __init__(self, in_feats, h_feats, n_classes):
super().__init__()
self.conv1 = GraphConv(in_feats, h_feats)
self.conv2 = GraphConv(h_feats,n_classes)
def forward(self, g, in_feat):
out = self.conv1(g, in_feat)
out = torch.relu(out)
out = self.conv2(g, out)
return out
また,比較のために大規模グラフを扱えるGraphSAGEでも同じ条件で実験してみます.
モデルはこちら
class GraphSAGE(nn.Module):
def __init__(self, in_feats, h_feats, n_classes):
super().__init__()
self.conv1 = SAGEConv(in_feats, h_feats, aggregator_type="mean")
self.conv2 = SAGEConv(h_feats, n_classes, aggregator_type="mean")
def forward(self, g, in_feat):
out = self.conv1(g, in_feat)
out = torch.relu(out)
out = self.conv2(g, out)
return out
実験環境はGoogle ColaboratoryのGPU環境で実施しました.
当たったGPUはこちら.
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |
| N/A 44C P0 25W / 70W | 0MiB / 15109MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
モデルの特徴量は100次元,中間層は50次元,クラス分類は10クラスの設定で5回ずつ推論を実行し,平均をとりました.
実験結果
実験の結果はこちら.
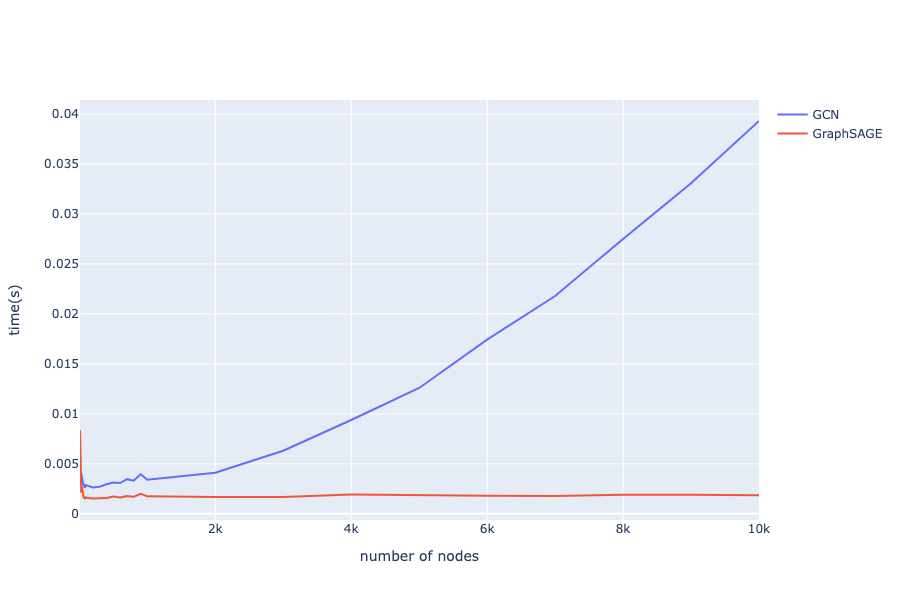
グラフを見ると,規模の大きなグラフではGraphSAGEの処理速度が圧倒的ですね.
ただ,GCNで10000ノードの完全グラフを推論させたとしても,1回あたりの推論時間は0.04秒程度です.
GPU利用率は10000ノードの完全グラフで2.6GB程度です.
推論時間面の性能としてはGraphSAGEに軍配が上がりますが,実務的にはグラフの大規模化によるGPU枯渇の方が早く問題になるかもしれません.
まとめ
近年研究が増えているGraph Neural NetworkからGCN(Graph Convolutional Network)の推論速度に関して簡単な検証を実施しました.
GCNでは,ノード数に比例して推論速度が重くなっていきますが,10000ノードの完全グラフでも推論速度は0.04秒程度でした.
実務上は推論速度よりもGPUメモリ使用率の方がボトルネックになりそうです.
また,推論速度の観点ではGCNに比べてGraphSAGEが圧倒的に高速でした.
参考文献
[1] T. Kipf et al., Semi-Supervised Classification with Graph Convolutional Networks, ICLR., 2017.
[2] Hamilton, W. L. et al., Inductive Representation Learning on Large Graphs, Neural Information Processing Systems, 2017.