バージョン情報
- Python 3.6.3
- NumPy 1.13.3
- Pandas 0.23.4
import
import numpy as np
import pandas as pd
やりたいこと
df = pd.DataFrame(
columns=['type', 'items'],
data=[
['type-001', ['apple', 'orange', 'melon']],
['type-002', ['apple', 'google', 'microsoft', 'ibm']],
['type-003', ['foo', 'bar']],
]
)

こんな感じで中にリストを持っているDataFrameを,
pd.DataFrame(
columns=['type', 'items'],
data=[
['type-001', 'apple'],
['type-001', 'orange'],
['type-001', 'melon'],
['type-002', 'apple', ],
['type-002', 'google'],
['type-002', 'microsoft'],
['type-002', 'ibm'],
['type-003', 'foo'],
['type-003', 'bar'],
]
)

これにしたい.
やりかた
結構よくあるシチュエーションのような気がするが, 超お手軽にやる方法は無さそうな感じだった. この記事も私の自己流になります.
まず次のような関数を作っておく. これは DataFrame の apply 関数に渡して1行ずつ処理させることを意識しています.
def flatten(row):
df1 = pd.Series(row['type']).to_frame(name='type')
df2 = pd.Series(row['items']).to_frame(name='item')
df1['key'] = df2['key'] = 0
return df1.merge(df2, how='outer').drop(columns='key')
一瞬だけ key という名前のカラムを作っているのはcross joinを行いたかったためです. 参考: cartesian product in pandas - Stack Overflow
これを実際に apply するコードは下記のようになる:
pd.concat(df.apply(flatten, axis=1).values)
df.apply(flatten, axis=1) の時点では複数の DataFrame が入った Series が返っているので, それを pd.concat で全部くっつけている. 結構力技だと思う.
ちなみに, わざわざ cross join を使っているので type の値にリストが入っているようなシチュエーションでもそのまま動く.
df = pd.DataFrame(
columns=['type', 'items'],
data=[
[['type-001', 'type-A'], ['apple', 'orange', 'melon']],
[['type-002'], ['apple', 'google', 'microsoft', 'ibm']],
[['type-003'], ['foo', 'bar']],
]
)
pd.concat(df.apply(flatten, axis=1).values)

もうちょっと複雑なとき
現実的なケースを考えると type だけでなく type と同じ行にいる他の列も一緒に連れてくる必要があるケースがほとんどだろう.
次のようなデータを考えよう:
df = pd.DataFrame(
columns=['type', 'items', 'bra', 'yo'],
data=[
[['type-001', 'type-A'], ['apple', 'orange', 'melon'], 'brabrabrabra', 'Yo'],
[['type-002'], ['apple', 'google', 'microsoft', 'ibm'], 'brabrabrabrabrabrabrabra', 'YoYo'],
[['type-003'], ['foo', 'bar'], 'brabrabrabra', 'YoYoYoYo'],
]
)

もしも type の中身がリストでなければ, 前のコードを
df1 = pd.DataFrame({'type':row['type'], 'bra':row['bra'], 'yo':row['yo']})
と書き換えるだけで対応できるが, 今回は type にリストが来るという制約を自ら課してしまったので, もう少し面倒な書き方をする必要がある. apply に渡すための関数はこんな感じになる:
def flatten(row):
df1 = pd.Series(row['type']).to_frame(name='type')
df2 = pd.Series(row['items']).to_frame(name='item')
df3 = pd.DataFrame([{'bra': row['bra'], 'yo': row['yo']}])
df1['key'] = df2['key'] = df3['key'] = 0
return df1.merge(df3, how='outer').merge(df2, how='outer').drop(columns='key')
展開に関係しないカラムはまとめて df3 に入れておき, 2回 cross join を走らせている. apply する側のコードは変わらず
pd.concat(df.apply(flatten, axis=1).values).loc[:, ['type', 'item', 'bra', 'yo']]
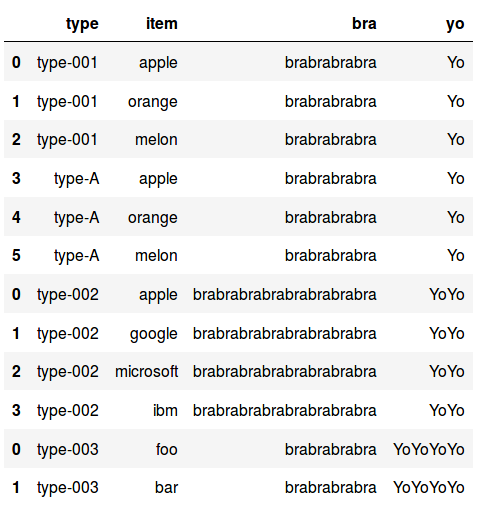
ただし, カラムの順番が気持ち悪くなるので .loc で直している.