はじめに
今回もキャプチャ多め、自分用のメモになります。
内容は、表題の通りのことになります。
また、後半は、作成したPythonのコードをGitHubに登録し、静的解析にSider というコードの解析サービスを使った例をご紹介します。
前提条件 / 環境
- MacOS (High Sierra)
- Python3を利用 (Googleの公式サイトのサンプルコードを利用しています)
パスの通っている基本のPythonは、MacにプリインストールのPython2xですが、venvを利用して3系を使って書いています。
なぜスクリプト?なぜPython?
とある作業で、1000件くらいのPDFをGoogleDriveにアップロードする必要が出たのがきっかけです。
ファイルは1000件強なので、Drag & Dropのアップロードでもまあ良いのですが、以下のような背景がありました。
アップロードするとファイル名でなくIDが割り当たる
- アップロードする元のファイルは、別のデータ形式で、スクリプトで変換をかけて生成したものである(この処理についてはまたどこかでメモを上げます)
- ファイル名にはPDF文書のタイトルをつけたいけれど、ローカルのファイルシステム上では空白やスラッシュの入ったファイル名を設定できない
- ファイルには日付やタグの属性など、付加情報があったが、変換の際にそれらが欠損しまうので、タイトルに含めたい
- GoogleDriveにアップすると、実際はファイル名でなくIDが割りあたる
- オブジェクトの属性としてのタイトルは、空白やスラッシュがあっても登録できる
ということで、ローカルのファイルシステム上では xxxxxxx.pdf といったファイル名にしておき、アップロードする際に対応表を参照して適切なタイトルを添えたい...ということで、scriptを組んでみることにしました。
なぜPython?
今回GoogleDriveへの操作も含めて、下準備の変換もPythonで行いました。
なぜそうしたかというと、以下の本を読んでいたからです。
プログラマじゃ無い...わけではないのですが、単調な作業ではあるので、ここは書籍に倣って。
また、GoogleDriveのAPIを試したくてドキュメントを見た所、サンプルにPythonもあったので、こちらを選択となりました。
まず参考にしたところ
アプリから利用ではなく、HTTPでのREST APIを利用になるので、以下を参照しました。
下準備: Drive APIを有効にする
Overviewにも解説があるとおり、GoogleDriveのAPIを有効にする必要があります。
このあたりは割愛しますが、credential.jsonを取得して、Pythonのスクリプトの直下に配置しました。
Google Clientライブラリを入れる
手順に従い、google-api-python-client, oauth2client を追加します。
こちらのクライアントライブラリは、GoogleDriveはじめSheet, Slide, Calendarといった割とビジネス向けツールだけでなく、BigQueryやApp EngineといったGCPのAPIも対象にしています。
- https://developers.google.com/api-client-library/python/
- https://developers.google.com/apis-explorer/#p/drive/v3/ (GoogleDriveのAPI一覧)
以下はGoogleDrive APIの一覧です。
このページから、各APIに対して簡易の入力フォームからリクエスト、レスポンスを確認することができます。(後述します)
やってみる
さて、実際にAPIを使って、PythonのコードでGoogleDriveにアクセスしてみます。
最初は読み取りから確認してみます。
読み取りさせてみる
基本のコードは、公式サイトのサンプルの通りになります。
ただ、それだけだと面白くないので、少しコメントをつけて、何を行なっているかを添えてみます。
# __future__ はPython2系と3系の互換性のためのもの。
# サンプルコードでは「どちらのバージョンで」という記載は無いので、2系でも3系でも
# 動くようにするため。
from __future__ import print_function
# Google's discovery based API
from googleapiclient.discovery import build
# よく使われるhttp用のライブラリです
from httplib2 import Http
from oauth2client import file, client, tools
# If modifying these scopes, delete the file token.json.
# scopeは読み取りのみ(不用意な削除更新を防げます)
SCOPES = 'https://www.googleapis.com/auth/drive.metadata.readonly'
def main():
"""Shows basic usage of the Drive v3 API.
Prints the names and ids of the first 10 files the user has access to.
"""
store = file.Storage('token.json')
creds = store.get()
if not creds or creds.invalid:
flow = client.flow_from_clientsecrets('credentials.json', SCOPES)
creds = tools.run_flow(flow, store)
service = build('drive', 'v3', http=creds.authorize(Http()))
# Call the Drive v3 API
# サンプルでは条件は無しでしたが、キーワードに"SRE"を含むものを指定
results = service.files().list(
pageSize=10, fields="nextPageToken, files(id, name, mimeType)", q="name contains 'SRE'").execute()
items = results.get('files', [])
if not items:
print('No files found.')
else:
print('Files:')
for item in items:
print('{0} ({1})'.format(item['name'], item['id'], item['mimeType']))
if __name__ == '__main__':
main()
こちらを早速実行してみます。
認証する部分
まずcredential.jsonが配置されたディレクトリでスクリプトを実行。
$ python quickstart.py
まずは、OAuth2のお作法にのっとり、認証、次に認可の処理が行われます。
token.json というファイルに、最終的にAPIのURLにアクセスして処理を行うためのアクセストークンが書き出されます。
初回の認証後は、「このリソース(ファイル読み取り)にアクセスさせていいですか?」という認可のダイアログも出てきます。
コマンドラインでの実行の場合でも、ブラウザが起動して認可を求められます。
認証・認可を踏まえると、ブラウザ側には "The authentication flow has completed." というメッセージが表示されます。
また、認可後には、ターミナル側に以下のようなメッセージが出ます。
その後に、print文の結果が表示されます。
UserWarning: Cannot access token.json: No such file or directory
warnings.warn(_MISSING_FILE_MESSAGE.format(filename))
Your browser has been opened to visit:
https://accounts.google.com/o/oauth2/auth?client_id=xxxxx .... [ 略] .... &response_type=code
If your browser is on a different machine then exit and re-run this
application with the command-line parameter
--noauth_local_webserver
Authentication successful.
SCOPE (できる範囲)を設定
APIでのアクセスの際には、「こういうことをしたいけどいいですか?」といった認可情報を踏まえて、手続きが行われます。
ファイルのお読み取りだけならdrive.readonly, 操作(追加更新削除)といった場合はdrive.file といった指定になります。
詳しくは以下の一覧に掲載されています。
- https://developers.google.com/identity/protocols/googlescopes
- https://developers.google.com/identity/protocols/googlescopes#drivev3 (GoogleDriveに関してのscope)
ファイルを絞り込む
実際の呼び出しは、service.files().list() の箇所で処理しています。
何も条件を指定しないと、アクセスできるファイルが全て抽出対象になります。
ただし、APIとしては一気に結果を返さずに、一度に何件で残り何回分(何ページ)ありますという情報を添えて、最初の分が返ります。
drive.files.list() に引数を指定して、もう少し絞り込んでみます。
検索条件は、q="....." という形で渡します。
「大なり小なり」「完全一致・部分一致」など、細かい条件は以下に記載されています。
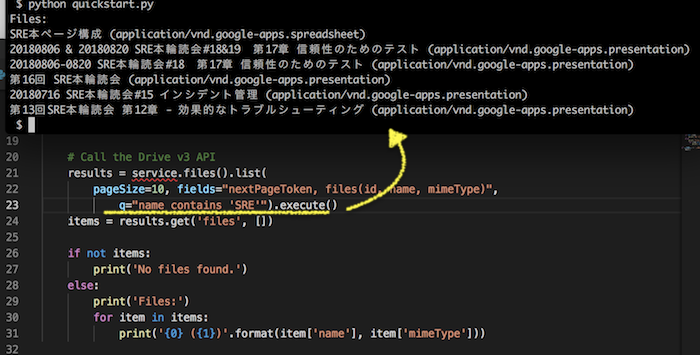
今回の場合は、q="name contains 'SRE'" (ドライブ中のドキュメント名に SRE を含むもの)を指定しました。
結果は、以下の通り。
API Explorerも試してみる
さて、先ほど少しふれた通り、API Explorerからも試してみます。
ブラウザでAPI一覧を確認、テスト用のリクエストを送信できます。
GoogleDriveのAPIエクスプローラーでは、こちらに該当します。
- https://developers.google.com/apis-explorer/#p/drive/v3/drive.files.list (drive.files.list)
画面の右側の"Authorize requests using OAuth 2.0:" のボタンをONにして試してみます。
その上で、抽出したいドキュメントのフィールドを指定します。
こちらも、画面下側に "Use fields editor" というリンクがあるので、こちらをクリックすると抽出できるフィールドが選べます。
ドキュメント名、ID、mimeType....といった感じ。
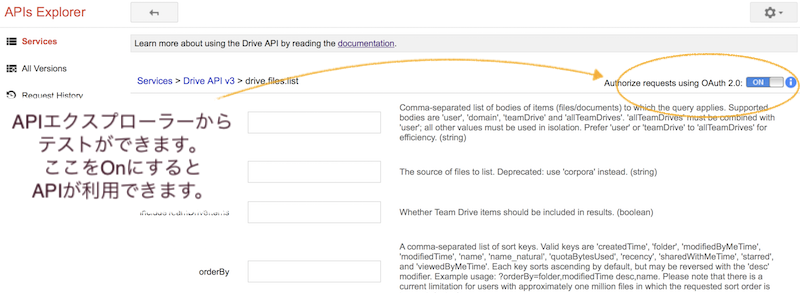
Executeボタンを押すと、以下のように結果が表示されます。
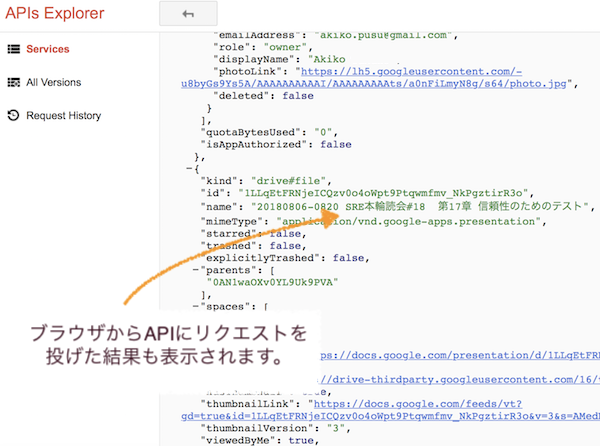
API Explorerは、なるほど使ってみると便利でした。
今後も動作確認などに活用しようと思います!
登録させてみる
さて、APIが利用できることが確認できたので、次に登録(アップロード)をしてみます。
この場合は、SCOPESが異なりますので、readonlyで取得したtokenでは権限が足りません。
再取得を行なった上で、Uploadを実施します。
from googleapiclient.discovery import build
from httplib2 import Http
from oauth2client import file, client, tools
from apiclient import discovery
from apiclient.http import MediaFileUpload
import os, json
from pathlib import Path
# 例外でなくwarningを抑止する際に利用
import warnings
# コンテンツのMediaType判定
import mimetypes
# 学習のため、簡単なクラスを作ります
class GoogleDriveUpload():
def __init__(self, folder_id):
self.set_service()
self.upload_folder_id = folder_id
def set_service(self):
# If modifying these scopes, delete the file token.json.
SCOPES = 'https://www.googleapis.com/auth/drive.file'
flags = tools.argparser.parse_args('--auth_host_name localhost --logging_level INFO'.split())
warnings.filterwarnings('ignore')
store = file.Storage('token.json')
creds = store.get()
if not creds or creds.invalid:
flow = client.flow_from_clientsecrets('credentials.json', SCOPES)
creds = tools.run_flow(flow, store, flags)
self.service = build('drive', 'v3', http=creds.authorize(Http()))
# 一個づつアップロードする関数 / 基本はここがメイン
def upload(self, filename, title, mediaType='application/pdf'):
# ファイルのメタデータを設定
file_metadata = {
'name': title,
'mimeType': mediaType,
'parents': [self.upload_folder_id]
}
media = MediaFileUpload(str(filename),
mimetype='application/vnd.google-apps-document',
resumable=True)
self.service.files().create(body=file_metadata,
media_body=media,
fields='id').execute()
こんな感じで利用します。
インタラクティブモードで、インスタンスを作成してから、uploadメソッドを呼んでみます。
$ python
Python 3.7.0 (default, Aug 22 2018, 15:22:33)
[Clang 9.1.0 (clang-902.0.39.2)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> from drive_upload import GoogleDriveUpload
>>> folder_id = 'アップロードするフォルダのID'
>>> instance = GoogleDriveUpload(folder_id)
>>> instance.service
<googleapiclient.discovery.Resource object at 0x10d9b6e48>
>>> instance.upload('source/おためし.txt', 'おためしのテキストです', 'text/plain')
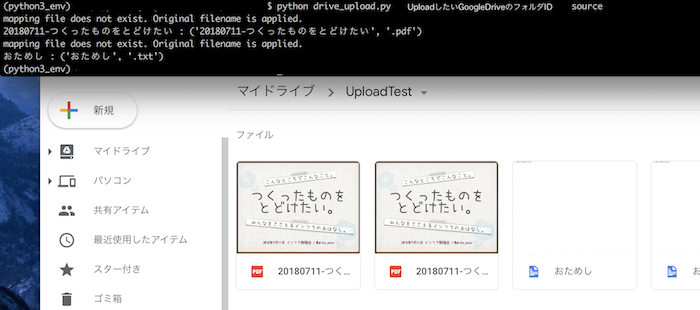
実際は、対象のディレクトリにあるファイルをまとめてアップロードさせているので、そのために指定のディレクトリからファイルの一覧を取得して、mymeTypeやアップロード時の属性をチェックして、for で1つずつGoogleDriveにアップロードしています。
# ファイル名に対してのメタデータをもったjsonを指定(なくても動く)
# アップロードする際に対応表を参照して適切なタイトルを添えたいという目的で使ってます
file_map = 'mapping_file.json'
g = GoogleDriveUpload(upload_folder_id)
# 別途関数で指定のローカルのディレクトリからファイル一覧を取得
files = target_files(from_dir)
# 一括アップロード
g.bulk_upload(files[start_index:], file_map)
正直、このあたりは学習しながらなので、適切な書き方かどうかかなり恥ずかしいのですが、ソース自体はGitHubに登録してみました。
-
https://github.com/akiko-pusu/python_google_drive_sample
- この記事を書いている時点ではmasterブランチはREADMEのみです
- https://github.com/akiko-pusu/python_google_drive_sample/tree/add_quickstart_sample で作業中
せっかくなのでSiderで静的解析してみた
さて、GitHubにアップしてみたのですが、そこそこの量のPythonのコードになりましたので、人目に晒す前に、「お作法的に大丈夫なの?」というあたりが気になります。とくに、ぼっち開発の場合...。
ということで、SideCIあらため Sider 様のサービスを利用してみることにしました。(日頃 Redmineのプラグインを書く際にお世話になっています!!)
まずは登録&プルリクエストを作ります
公開リポジトリであれば、簡単に静的解析の対象に登録が可能です。
ただし、わたしはPythonの静的解析(lintと言ったりします)は初めて。
ひとまずmasterブランチにREADME.mdのみを登録した段階で、Siderの解析対象に登録してみました。
チェック対象の言語はPythonを選びます。
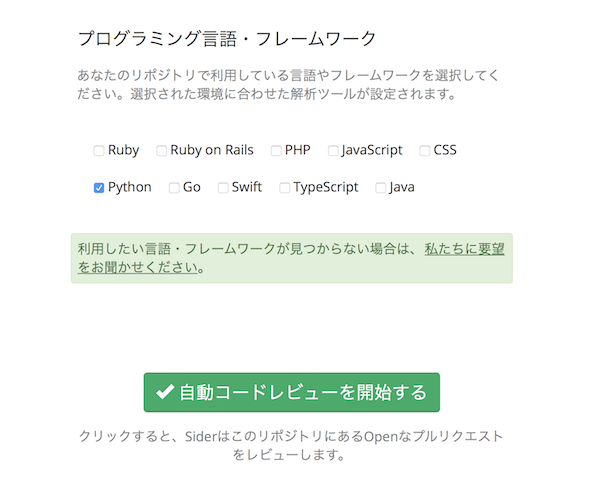
つぎに、上記のPython Scriptをプルリクエスト用のブランチに登録。
GitHub側にプルリクエストを作成しました。
Siderはプルリクエストが作成されるとWebhookを受けて解析を開始します。
デフォルトでは、言語の他にスペルチェック用の解析ツールも起動します。
今回はPythonなので、flake8を利用して解析が始まりました。
いつも通り解析が始まり、さてどれだけ指摘されるかな...?と思ったら、なんとエラーなし!
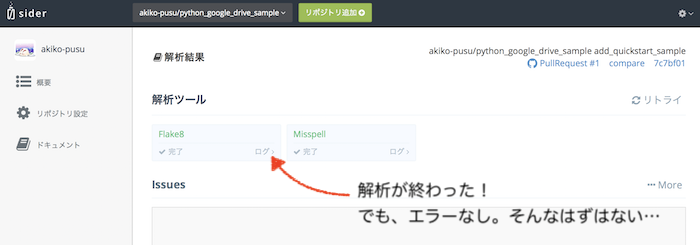
そんなはずはないので、setup.cfgを追加
そんなはずはない...。
ここで、あらためてPythonの静的解析が初めてだったのを思い出し、flake8をインストール。
特に指定なしでも、いろいろ指摘が出てきます....。
Sider側では、プロジェクト単位での解析が走るので、ソースコードに setup.cfg や tox.ini といった設定ファイルがないと処理が走らないようです。
こうして、あらためて setup.cfg を追加(commit --amend) して、プルリクエスト用のブランチに強制push。(あまりやらないように...)
追加したのは、以下のような内容になります。(今後微調整...)
[flake8]
max-line-length = 140
include = *.py
exclude = tests/*, python3_env/*
max-complexity = 10
すると、ただしく?解析され、ビシバシと指摘が入りました!
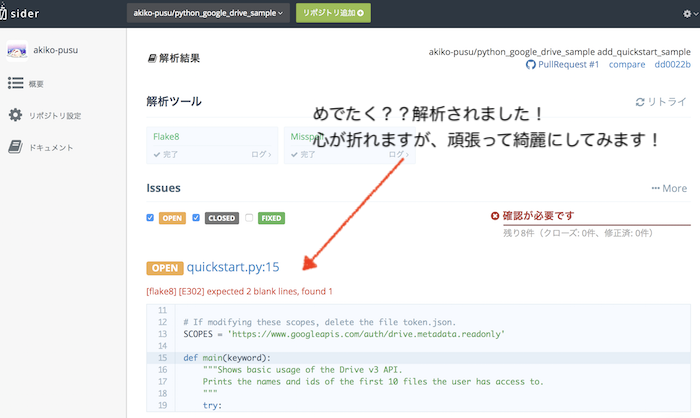
GitHubのプルリクエスト側は、xマークが付き、このプルリクエストには難点があるよということが一目で分かります...。
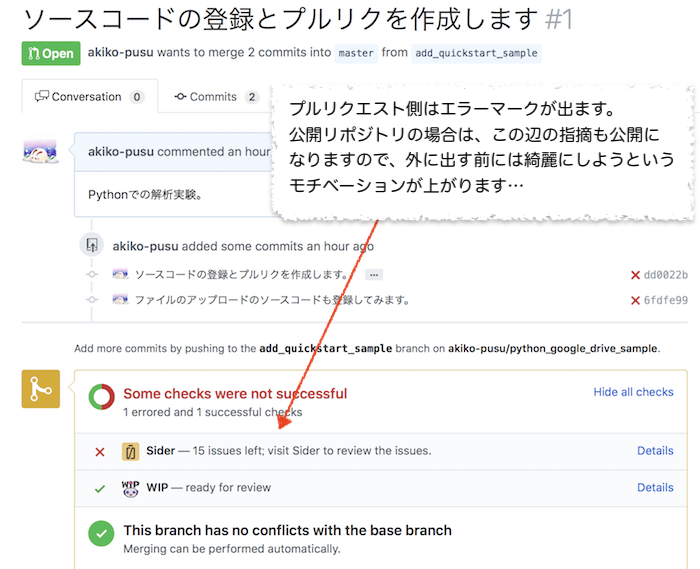
Sider側のオプションで、指摘をGitHub側にコメントとして飛ばすこともできます。
ただし、慣れないうちは、この機能をオフにし、ローカル開発環境側でもlinterを利用して、できるだけ整えてからpush...というのが良さそうです。
また、実際に試してみてですが、Pythonのフレームワークを使ったリポジトリでなくとも、Siderで解析できることが分かりました。
ほかにも、PHPやJavaといった主要な言語に対応しているので、rubyだけでなく、ある程度外に出すようなものは気をつけてみようと思います。
まとめ
以上、内容がいろいろと散らばってしまいましたが、以下について駆け足で触れてみました。
- Pythonを使ったGoogle API Clientの利用
- GoogleDrive APIの紹介
- 認証および認可の際の動作
- ディレクトリ情報の取得とアップロードのテスト
- GitHubへの登録&Siderを使った静的解析
アップロードの方法は、他にもマルチパートでのアップロードや、バッチ形式の方法があったかと思います。まだこちらは試していませんが、必要が出たタイミングで、試してみようと思います。
また、GoogleのAPIには、Driveだけでなく、もちろんスケジューラやGCPのものもあります。GASと合わせて、いろいろ試せたらな、と思います。
上記いずれかのトピックについて、なにかお役に立てましたら幸いです。