Tabular Editor 2 Docs
こちらはTabular Editor 2 Docs Advent Calendar 2022への投稿記事です。
2022年11月下旬ごろのDocsを日本語訳しています。
最新情報は公式ページ・公式リポジトリをご確認ください。
テーブルのインポート
すでにレガシーデータソースがモデル内にある場合は、それを右クリックして「Import Tables...」を選択できます。Tabular Editorはデータソースで指定されたデータプロバイダーと認証情報を使って接続を試みます。成功すれば、データソースからアクセス可能なすべてのデータベース、テーブル、ビューのリストが表示されます。

左側のテーブルまたはビューをクリックすると、右側にデータのプレビューが表示されます。このとき、含めたくない列の選択を解除できます。ただし、The data import best practice では、常にビューを使用し、タブラーモデルに必要な列のみをビューに含めることを推奨しています。UIには結果のSQLクエリが表示されます。デフォルトでは、Tabular Editorは SELECT * FROM ... を使ってテーブル/ビューをインポートしますが、プレビューで任意のカラムをトグルすると、結果のクエリにカラムのリストが明示的に表示されます。SELECT * FROM ... に戻すには、右上の "Select all columns" チェックボックスをトグルしてください。
複数のテーブル/ビューを選択して、一度にインポートできます。インポート "をクリックすると、選択されたすべてのテーブル/ビューは、メタデータからすべてのカラムが入力された新しいテーブルとしてインポートされます。各テーブルにパーティションが作成され、UIから出力されたSQLクエリが保持されます。
これだけです!もうTabular EditorとSSDTの間を行ったり来たりする必要はありません。
レガシーデータソースと構造化データソースの比較に関するメモ
現在、Tabular EditorにはM(Power Query)式から返されるメタデータを推測する方法がないため、このUIはレガシー(別名、プロバイダー)データソースのみをサポートしています。構造化データソースを使用しなければならない場合でも、一時的なレガシー接続を使用してテーブルスキーマを最初にインポートし(データソースがSQL、OLE DB、ODBCを通してアクセスできると仮定)、インポートしたテーブルのパーティションを手動で切り替えて、構造化データソースを使用することが可能です。WebサービスやAzure Data Lake Storageなどの「エキゾチックな」データソースからデータをインポートする場合、スキーマメタデータは自動的にインポートできませんが、クリップボードを通じてメタデータ情報を提供するオプションがあります.
しかし、一般的には、次のようなソースには常にレガシー接続を使用することをオススメします。
- SQL Server databases
- Azure SQL Databases
- Azure SQL Data Warehouse
- Azure Databricks (through ODBC)
- Any relational OLEDB data source
- Any relational ODBC source
Azure Active Directory with MFAを使用した認証については、こちらをご覧ください。
既存のデータソースがない場合のインポート
モデルにまだデータソースが含まれていない場合、"Model" メニューから "Import Tables..." をクリックすることで、テーブルをインポートできます。結果として、UIは以下のようになります。

選択項目が「新しいデータソースを作成してモデルに追加する」のまま、「次へ」をクリックすると、接続ダイアログのUIが表示されます。このダイアログでは、接続の詳細を指定できます。

「OK」をクリックすると、指定した接続を使用する(レガシー)データソースがモデル内に作成され、上記のインポートページが表示されます。
リストの次のオプションである「一時的な接続を使用する」は、モデルに新しいデータソースが追加されません。つまり、モデルをデプロイする前に、新しくインポートされたテーブルのパーティションにデータソースを割り当てる責任があります。
最後のオプションである「他のアプリケーションからメタデータを手動でインポートする」は、列のメタデータのリストに基づいて新しいテーブルをインポートしたい場合に使用します。これは、構造化(Power Query)データソースに便利です(下記参照)(/Importing-Tables#power-query-data-sources)。
SQL機能
SQL Server以外のデータソース(正確にはNative SQL Clientドライバーを使用しないデータソース)の場合、画面下部付近の2つのドロップダウンボックスに注目してください。

テーブルインポートウィザードは、ソーステーブルまたはビューから200行のデータしか取得しないため、"行の削減 "ドロップダウンは、ソースにプレビューデータを照会する際に使用する行削減句を指定できます。"TOP"、"LIMIT"、"FETCH FIRST "など、もっとも一般的な行削減句を選できます。
識別子の引用 "ドロップダウンにより、生成されるSQL文におけるオブジェクト名 (カラム、テーブル) の引用方法を指定できます。これは、テーブルを表形式モデルにインポートする際、データプレビューとテーブルパーティションクエリで使用するSQLステートメントの両方に適用されます。デフォルトでは角括弧が使用されていますが、他の一般的な識別子の引用符に変更することもできます。
テーブルのソースを変更する
インポートページを表示させるもう1つの方法は、既存のテーブル(レガシーデータソースを使用)を右クリックし、「列の選択...」を選択することです。そのテーブルが以前にUIを使用してインポートされていた場合、インポートページには、ソーステーブル/ビューとインポートされた列があらかじめ選択されて表示されるはずです。列を追加・削除したり、モデルで選択したテーブルの代わりに、まったく別のテーブルをインポートすることもできます。テーブルの列が選択解除されたり、インポート元のテーブル/ビューに存在しなくなった場合、モデルから削除されることに注意してください。このような操作は、CTRL+Zでいつでも元に戻すことができます。
テーブルメタデータのリフレッシュ
バージョン2.8から、Tabular Editorに新しいUI機能が追加され、スキーマドリフトを簡単にチェックすることができるようになりました。つまり、データ型が変更されたカラムや、ソーステーブルやビューに追加または削除されたカラムを検出できます。このチェックは、モデルレベル(レガシーデータソースにのみ適用)、データソースレベル、テーブルレベル、パーティションレベルで実行できます。これは、オブジェクトを右クリックして、"Refresh Table Metadata... "を選択することで実行されます。

変更は、それぞれのテーブル上のすべてのデータカラムの「ソースカラム」と「データ型」プロパティに基づいて検出されます。何らかの変更が検出された場合、Tabular Editorは上記のUIを表示し、変更の詳細を示します。モデルに適用したくない変更を選択解除できますが、一部の変更は処理エラーを引き起こす可能性があることに注意してください(たとえば、ソーステーブル/ビュー/クエリーに存在しないソースカラムなど)。
このメカニズム(およびテーブルのインポートUI)では、ソースからメタデータを照会する際にFormatOnlyフラグが使用されます。つまり、ストアド・プロシージャを使用するテーブル・パーティションを持つことができます。FormatOnly-flagは、ストアドプロシージャが決して直接実行されないようにします。その代わり、サーバーが静的解析を行い、ストアドプロシージャの実行時に返されるであろう結果セットを記述したメタデータのみを返します。RDBMSによっては、ストアドプロシージャでFormatOnly-flagを使用する際に、いくつかの制限があります。SQL Serverをデータソースとして使用する場合のこのトピックに関する詳細については、この記事を参照してください。
CLIサポート
コマンドラインから -SC フラグを使用して、モデルレベルのスキーマチェックを行うことができます。CLIでスキーマチェックを実行した場合、マッピングの問題のみが報告されることに注意してください。これはモデルに変更を加えることはありません。これはCI/CDパイプラインでTabular Editorを使っている場合に便利です。なぜなら、マッピングの問題はテスト/本番環境にモデルをデプロイした後に問題を引き起こす可能性があるからです。
オブジェクトを無視する
Tabular Editor 2.9.8では、スキーマチェック/メタデータリフレッシュの対象からオブジェクトを除外できます。これは、除外したいオブジェクトにアノテーションを設定することで制御します。アノテーションの名前には、以下のコードを使用します。アノテーションの値は空白のままでも、"1"、"true"、"yes "のいずれかを設定できます。注釈の値を "0"、"false"、"no "に設定すると、注釈が存在しないかのように、効果的に注釈を無効化します。
Table flags:
-
TabularEditor_SkipSchemaCheck: Tabular Editorがこのテーブルのスキーマチェックを完全にスキップするようにします。 -
TabularEditor_IgnoreSourceColumnAdded: Tabular Editorは、このテーブル上のどのテーブルカラムにもマッピングされていない追加カラムを無視します。 -
TabularEditor_IgnoreDataTypeChange: Tabular Editorは、テーブルのどのカラムでも、データ型の不一致を無視します。 -
TabularEditor_IgnoreMissingSourceColumn: Tabular Editorは、ソースカラムがソースに存在しないように見える場合、インポートされたカラムを無視します。
Column flags:
-
TabularEditor_IgnoreDataTypeChange: Tabular Editorは、この特定のカラムのデータ型の不一致を無視します。 -
TabularEditor_IgnoreMissingSourceColumn: Tabular Editorは、この特定のカラムに明らかに欠けているソースカラムを無視します。
このフラグは、UIとCLIの両方を通じてスキーマチェックに影響を与えます。
警告をエラーとして扱う
デフォルトでは、パーティション・クエリを実行できなかった場合、またはインポートされたテーブルにソース・クエリ内のどの列とも一致しない列が含まれている場合、CLI はエラーを報告します。列のデータ型がソース・クエリの列と一致しない場合、またはソース・クエリにインポートされたテーブルのどの列にもマッピングされていない列が含まれている場合、CLIは警告を報告します。また、同じテーブルの異なるパーティションのソースクエリが同じカラムを返さない場合にも警告が表示されます。
Tabular Editorバージョン2.14.1以降では、上記の警告をすべてエラーとして報告するようにCLIの動作を変更できます。これを行うには、model レベルに以下のアノテーションを追加します。
-
TabularEditor_SchemaCheckNoWarnings: Tabular Editorがすべてのスキーマチェックの警告をエラーとして扱うようにしました。
Azure Active DirectoryとMFA
Azure SQL DatabaseまたはAzure Synapse SQLプールからテーブルをインポートする場合、Azure Active Directoryの多要素認証が必要になる可能性があります。残念ながら、.NET Frameworkで使用されるSQL Native Clientプロバイダーでは、この認証はサポートされていません。代わりに、MSOLEDBSQLプロバイダーを使用してください(Analysis Services がテーブルからデータを読み込む際に、ネイティブ クライアントよりも一般的に高速になるという利点もあります)。ローカル・マシンで動作させるには、このドライバーの最新(x86)バージョンがインストールされていることを確認します。
以下は、MFAと連携するためのデータソースのセットアップの手順です。
- 新しいレガシーデータソースを作成し、モデルに追加します。モデル > 新規データソース(レガシー)
- プロバイダプロパティとして
System.Data.OleDbを指定し、以下のような接続文字列を使用します(正しいサーバ名、データベース名、ユーザ名を代入してください)。
Synapse SQLプールの場合
Provider=MSOLEDBSQL;Data Source=<synapse workspace name>-ondemand.sql.azuresynapse.net;User ID=daniel@adventureworks.com;Database=<database name>;Authentication=ActiveDirectoryInteractive
Azure SQLデータベースの場合
Provider=MSOLEDBSQL;Data Source=<sql server name>.database.windows.net;User ID=daniel@adventureworks.com;Database=<database name>;Authentication=ActiveDirectoryInteractive
- このソースからテーブルをインポートするには、データソースを右クリックして「テーブルのインポート...」を選択すると、テーブルのインポートウィザードUIが表示され、ソースからのテーブル/ビューのリストが表示されるはずです。Synapse SQLプールの場合、データプレビューを機能させるために、行句として「TOP(NOLOCKなし)」を指定する必要があります。
- モデルをAnalysis Servicesにデプロイする際、テーブルデータの更新時にAnalysis Servicesがソースに対して認証を行うために、Service PrincipalのアプリケーションIDやシークレット、SQLアカウントなど、他の認証情報を指定する必要ありまる。これは、TMSLやSSMSを使用してデプロイ後に指定することもできますし、CI/CDデプロイメントパイプラインの一部としてセットアップすることもできます。
スキーマ/メタデータの手動インポート
テーブルのインポートウィザードでサポートされていないデータソースを使用している場合、メタデータを手動でインポートするオプションがあります。このオプションでは、左側のテーブルスキーマを入力または貼り付けるUIが提供され、列名とデータ型情報が自動的に解析されます。または、右側に各カラム名を手動で入力し、ドロップダウンでデータ型を選択することもできます。いずれにせよ、手動でテーブルを作成し、メインUIから個々のデータカラムを追加するよりも高速になります。完了したら、「インポート!」を押して、テーブル名とパーティション式を調整します。
左側のテキストを解析する際、Tabular Editorは特定のキーワードを検索し、情報がどのように構成されているかを判断します。データの解釈はかなり自由なので、たとえばCREATE TABLE SQLスクリプトのカラムリストや、後述するPower Queryの Table.Schema(...) 関数の出力を貼り付けることができます。唯一の要件は、テキストの各行がソースデータの1列を表していることです。

Power Queryのデータソース
Power Query/M式の実行や検証を公式にサポートする方法がないため、Tabular EditorはPower Queryデータソースを限定的にサポートしています。2.9.0では、テーブルのインポートウィザードの「他のアプリケーションからメタデータを手動でインポートする」オプションを使用すると、ExcelまたはPower BI DesktopのPower Queryからスキーマをインポートできます。ワークフローは以下の通りです。
- まず、モデルにPower Queryのデータソースが含まれていることを確認します。[データソース] > [新規データソース (Power Query)]を右クリックします。SQL Server からデータを読み込む場合は、プロトコルに「tds」を指定し、Database、Server、AuthenticationKind の各プロパティを記入します。

- 他の種類のデータソースの場合、最初のモデルと最初のいくつかのテーブルをSSDTで作成し、データソースがどのように構成されるべきかを把握し、テーブルを追加するときだけ以下のテクニックを使用する方が簡単かもしれません。
- Excel または Power BI Desktop内のPower Queryを使用して、ソースデータに接続し、必要な変換を適用します。
- Power QueryのAdvanced Editorを使って、前回の出力に
Table.Schema(...)M function を使用するステップを追加します。
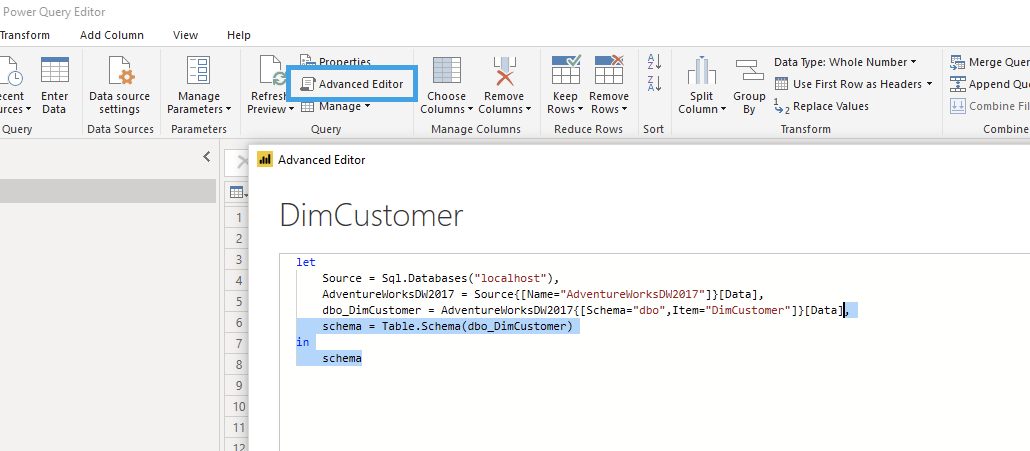
- フル出力プレビューを選択し、クリップボードにコピー(CTRL+A、CTRL+C)して、テーブルのインポートウィザードのスキーマ/メタデータテキストボックスに貼り付けます。
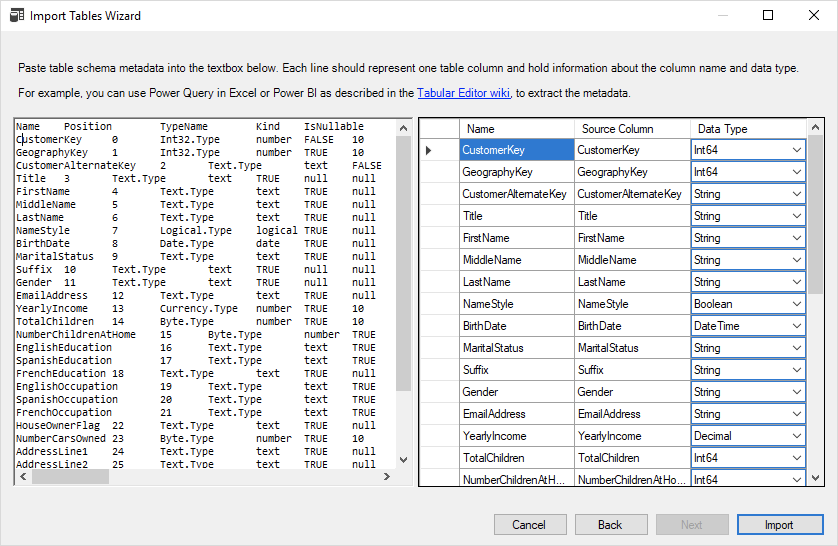
- 「インポート!」をクリックし、テーブルの適切な名前を指定します。
- 最後に、Excel/Power BIで使用した、
Table.Schema(...)関数で修正する前のオリジナルのM式を、新しく作成したテーブル上のパーティションに貼り付けます。M式を修正して、最初のステップで指定したソースを指すようにします。
