前回まで
前回まではRequestsとlxmlを使ってクローリング・スクレイピングを行った
第3章「ライブラリによる高度なクローリング・スクレイピング」はBeautiful Soupとpyqueryを使用する
3.1 HTMLのスクレイピング
3.1.1 Beautiful Soupによるスクレイピング
特徴
- シンプルでわかりやすいAPI
- 目的に合ったパーサーを選べる
使ってみる
$pip install beautifulsoup4 でインストール
適当にでっちあげたHTMLを参考に使い方を見ていく
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>hogehoge</title>
</head>
<body>
<div id="main">
<h1 class="h1hogehoge">hogehoge</h1>
<p> hegohego</p>
<a href="#hugohugo">hugohugo</a>
<table>
<tr>
<th>hoge1</th>
<th>hoge2</th>
</tr>
<tr>
<td>hego1</td>
<td>hego2</td>
</tr>
</table>
</div>
</body>
</html>
from bs4 import BeautifulSoup
with open("hogehoge.html") as f:
soup = BeautifulSoup(f,"html.parser")
print(soup.h1)
# <h1 class="h1hogehoge">hogehoge<h1>
print(type(soup.h1))#Tagオブジェクト
# <class 'bs4.element.Tag'>
print(soup.h1.name)#HTMLのタグ名を取得
# h1
print(soup.title.string)#要素の直接の子の文字列を取得
# hogehoge
print(type(soup.title.string))#strを継承したNavigableString
# <class 'bs4.element.NavigableString'>
print(soup.table.contents)#子要素のリストを取得
# ['\n', <tr>
# <th>hoge1</th>
# <th>hoge2</th>
# </tr>, '\n', <tr>
# <td class="hugogo">hego1</td>
# <td>hego2</td>
# </tr>, '\n']
print(soup.table.text)#要素内のすべての文字列を結合した文字列を取得
print(type(soup.table.text))#text属性でstrオブジェクトの文字列を取得
#
#
# hoge1
# hoge2
#
#
# hego1
# hego2
#
#
print(soup.div["id"])#Tagオブジェクトは辞書っぽい形式で属性を取得できる
print(soup.div.get("id"))#getでも属性を取得できる
# main
print(soup.div.attrs)#全属性をdictで取得
# {'id': 'main', 'class': ['container']}
print(soup.a.parent)#親要素を取得
# <div class="container" id="main">
# (省略)
# </div>
print(soup.tr)#複数ある場合は先頭の要素を取得
# <tr>
# <th>hoge1</th>
# <th>hoge2</th>
# </tr>
print(soup.find("td"))#上に同じ
# <td class="hugogo">hego1</td>
print(soup.find_all("td"))#指定した要素をすべて取得
# [<td class="hugogo">hego1</td>, <td>hego2</td>]
print(soup.find_all("td",class_="hugogo"))#上にキーワード引数を追加.classは予約後なのでclass_で
print(soup.find_all(class_="hugogo"))#属性のみで
print(soup.select("table > tr > td.hugogo"))#CSSセレクタで取得
# [<td class="hugogo">hego1</td>]
3.1.2 pyqueryによるスクレイピング
特徴
- JQueryと同じようなインターフェイスで使える(らしい。JQuery使ったこと無いのでノーコメント)
- 内部でlxmlを使っている
使ってみる
$pip install pyquery でインストール
from pyquery import PyQuery as pq
d = pq(filename="index.html") #(url="<url>")でURLを指定してパースもできる.他文字列を指定してパースも可能
# CSSセレクタを指定して取得
print(d("h1"))
# <h1 class="h1hogehoge">hogehoge</h1>
print(type(d("h1")))#listを継承したPyQueryクラスのオブジェクト
# <class 'pyquery.pyquery.PyQuery'>
print(d("h1")[0])#リストの中身はlxmlのElement
# <Element h1 at 0x7fb8c2f46728>
print(d("h1").text())#テキストを取得
# hogehoge
# 属性を取得
print(d("h1").attr("class"))
print(d("h1").attr.class_) #classは予約後なので末尾にアンダーバーをつける
print(d("h1").attr["class"])
# h1hogehoge
print(d("div").children()) #子要素を取得
# <h1 class="h1hogehoge">hogehoge</h1>
# <p> hegohego</p>
# <a href="#hugohugo">hugohugo</a>
# <table>
# (省略)
# </table>
print(d("h1").parent()) #親要素を取得
# <div id="main" class="container">
# (省略)
# </div>
# CSSセレクタ色々
print(d("td"))
# <td class="hugogo">hego1</td>
# <td>hego2</td>
print(d("td.hugogo"))
print(d(".hugogo"))
# <td class="hugogo">hego1</td>
# メソッドチェインで絞り込む
print(d("div").find("a")) #現在の要素の子孫からマッチする要素を取得
# <a href="#hugohugo">hugohugo</a>
print(d("td").filter(".hugogo"))#現在の要素のリストからマッチする要素を取得
# <td class="hugogo">hego1</td>
print(d("tr").eq(1)) #現在の要素のリストから指定したindexの要素を取得
# <tr>
# <td class="hugogo">hego1</td>
# <td>hego2</td>
# </tr>
3.2 XMLのスクレイピング
XMLのスクレイピング
XMLの代表例としてRSSのスクレイピングを行う
3.2.1 lxmlによるスクレイピング
前章でも使ったlxmlで、今回はRSSを解析する
今回はちょうど台風が来ていることもあって気象庁のRSSを利用する
$ wget https://www.jma-net.go.jp/rss/jma.rss
import lxml.etree
tree = lxml.etree.parse("jma.rss") #ElementTree要素を取得
root = tree.getroot() #RSSのルート要素を取得
for item in root.xpath("channel/item"):#itemの子要素をXpathで指定
title = item.xpath("title")[0].text
url = item.xpath("link")[0].text
pub_date = item.xpath("pubDate")[0].text
print(title,pub_date,url)
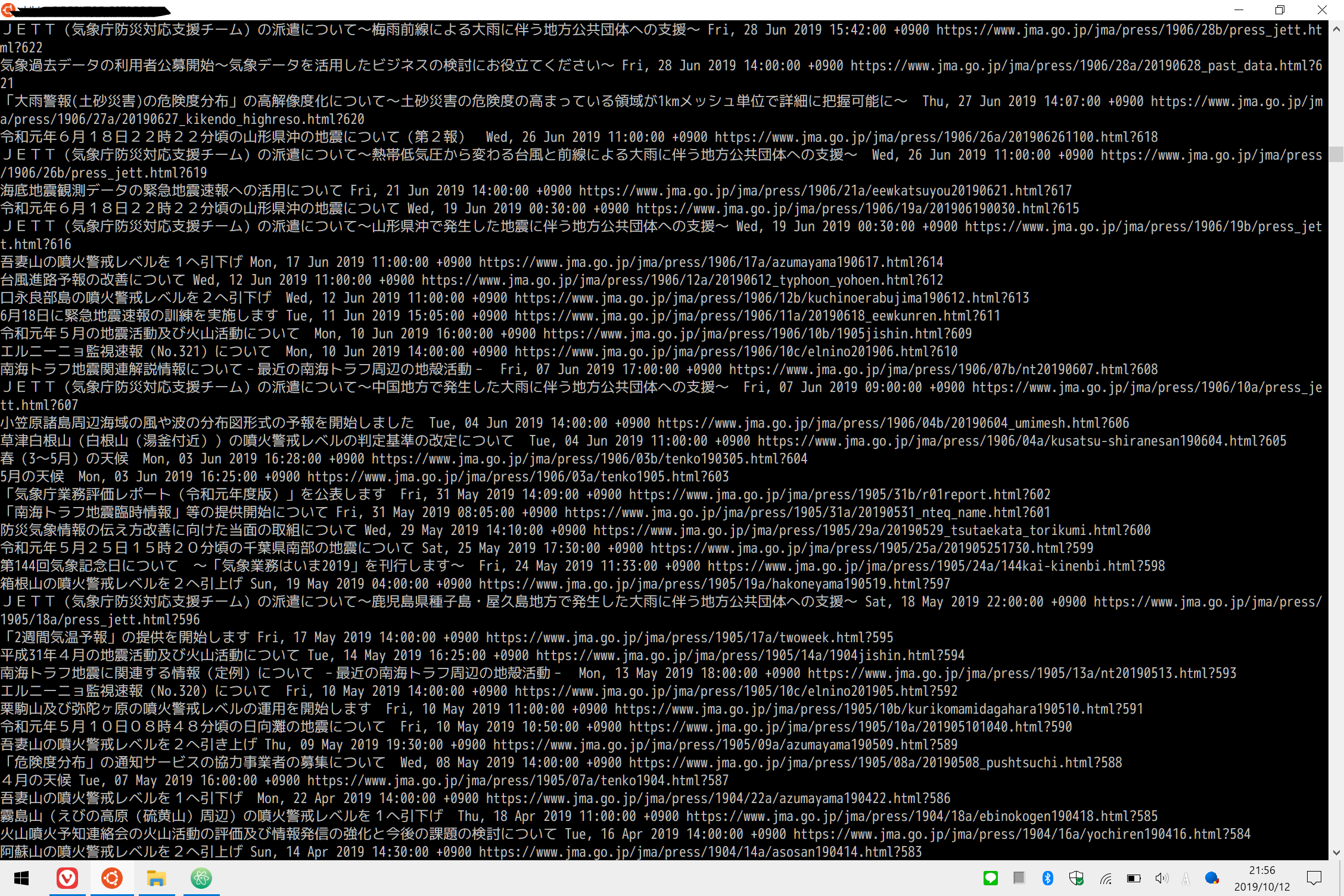
実際のRSSのファイルと比べると、要素内の、の各要素のデータがきちんと取得できていることがわかる
lxmlでは名前空間が使われたRSSフィード(Atomフィード)をスクレイピングする際にはXPath内に別名の接頭辞をつけ、namespacesにdict形式で接頭辞と名前空間を対応させる必要がある
例:root.xpath('接頭辞:title', namespaces={'接頭辞':'名前空間'})
3.2.2 feedparserによるスクレイピング
RSSフィードのフォーマットの違いを吸収するのでフォーマットを意識せずにスクレイピングできるのが特徴
import feedparser
d = feedparser.parse("jma.rss")
for entry in d.entries:
print(entry.link,entry.title,entry.updated)

先ほどと同じデータをより簡潔なコードで取得できた
3.3 データベースに保存する
リレーショナルデータベースではSQlite3とMySql、NoSQLではMongoDBを用いる
NoSQLとは?リレーショナルデータベース(RDB)との違いを徹底比較
両者の違いはこの記事を参考にした
3.3.1 SQLite 3への保存
SQLiteについて
- ファイルベースのシンプルなRDBMS
- 様々なプログラムに組み込まれることを想定されており、Pythonでは標準ライブラリsqlite3モジュールで使用できる
- ファイルの書き込みに時間がかかる
- 複数のプログラムからの同時書き込みができない
- これらの問題を解消するためにクライアント・サーバー型のRDBMSやNoSQLが使える
今回はサンプルコードを参考に、前回の記事で作成した競馬の結果をスクレイピングするプログラミングを元にした、スクレイピング結果をデータベースに保存するプログラムを作成した
import sys
import requests
import lxml.html
import sqlite3
def main(argv):
url = argv[1] #コマンドライン引数からURLを取得
html = fetch(url) #URLのWebページを取得
result = scrape(html) #取得したWebページから欲しい部分のみを切り出す
save_sql(result) #データベースに保存
def fetch(url :str):
r = requests.get(url) #urlのWebページを取得する
r.encoding = r.apparent_encoding #文字化けを防ぐためにencodingの値をappearent_encodingで判定した値に変更する
return r.text #取得データを文字列で返す
def scrape(html: str):
html = lxml.html.fromstring(html) #fetch()での取得結果をパース
a_list = html.cssselect('#race_main > div > table > tr > td > a') #馬名,騎手名,調教師名はそれぞれ成績ページにリンクされているのでaタグで絞り込む
columns = [[d.text for d in c] for c in [a_list[i:i+3] for i in range(0,len(a_list),3)]]#1.a_listの中身は[馬名,騎手名,調教師名,…]のリストになっているのでそれを3つずつのリストに分割 2.分割したリスト内の各要素はElementオブジェクトなので.textで各要素の文字列を取得
dict_culumns = []
for i,c in enumerate(columns): #リストは順位順なのでi+1で着順
dict_culumns.append({"rank":i+1,"horse":c[0],"jockey":c[1],"trainer":c[2]})#sqlでのコードを簡潔にするため、辞書を各要素に持つリストを作る
return dict_culumns #結果を返す
def save_sql(result):
conn = sqlite3.connect('result.db') #ファイルを開き、コネクションを取得する。
c = conn.cursor() # カーソルを取得する。
# execute()メソッドでSQL文を実行する。
c.execute('DROP TABLE IF EXISTS result')# 何回実行しても同じ結果になるようにするため、テーブルが存在する場合は削除する。
c.execute("""
CREATE TABLE result (
rank integer,
horse text,
jockey text,
trainer text
)
""")# cテーブルを作成する。
# executemany()メソッドでは、複数のパラメーターをリストで指定できる
# パラメーターが辞書の場合、プレースホルダーは :キー名 で指定できる
c.executemany('INSERT INTO result VALUES (:rank, :horse, :jockey, :trainer)',result)
conn.commit() # 変更をコミット
conn.close() # コネクションを閉じる。
if __name__ == '__main__':
main(sys.argv)
今回は競馬の結果から馬名・騎手名・調教師名をスクレイピングし、着順の情報はあとで付け加えて、DBに保存した

sqlite3コマンドで確認すると

スクレイピングした結果がDBに保存されていることが確認できる
このくらいのデータ量では書き込みが遅いというデメリットはまだ感じない(当たり前か)
3.3.2 MySQLへのデータの保存
MySQLについて
- クライアント・サーバー型
- 様々なプログラミング言語から簡単に使用できる
- 大規模でもスケールアウトでの性能向上が見込める
クライアントサーバシステムとは - IT用語辞典 e-Words
スケールアウトとは - IT用語辞典 e-Words
sudo apt install -y mysql-server libmysqlclient-dev
でmysql本体と開発用のパッケージをインストール
mysqlサーバはインストールと同時に起動されるそうなので
sudo systemctl status mysql
でステータスを確認しようとすると
"System has not been booted with systemd as init system (PID 1). Can't operate."
なるエラーメッセージが表示される
検索してみたところWSL上ではsystemctlコマンドが動かないそうで…
色々検索して出てきたservice --status-allとsudo service mysql statusで起動はできているっぽいことを確認
とりあえず、ユーザーの作成やサンプルコードの動作は正常に行えた
System has not been booted with systemd as init system (PID 1). Can't operate
[Ubuntu]稼働中のサービスを確認する
$ pip install mysqlclient でPythonからMySQLに接続するライブラリをインストール
SQLite3のときと同じくサンプルコードを参考にしたプログラムを作成した
前述のコードとダブっている部分は省略
# 省略
import MySQLdb #ライブラリをインポート
#
#
# 省略
#
#
def save_sql(result):
conn = MySQLdb.connect(db="hogehoge",user="hogehoge",passwd="hogehoge",charset="utf8mb4")
c = conn.cursor()# カーソルを取得する。
c.execute("DROP TABLE IF EXISTS `result`")# 何回実行しても同じ結果になるようにするため、テーブルが存在する場合は削除する。
c.execute("""
CREATE TABLE `result` (
rank integer,
horse text,
jockey text,
trainer text
)
""")#cテーブルを作成する。
# executemany()メソッドでは、複数のパラメーターをリストで指定できる
# パラメーターが辞書の場合、プレースホルダーは %(キー名)s で指定できる
c.executemany('INSERT INTO `result` VALUES (%(rank)s, %(horse)s, %(jockey)s,%(trainer)s)', result)
conn.commit() # 変更をコミット(保存)する。
conn.close() # コネクションを閉じる。
#
#
# 省略
#
#
スクレイピング対象はこちら

上記のプログラムを実行し、mysqlのコマンドでテーブルを表示すると…

こちらもスクレイピングした結果がDBに保存されていることが確認できる
PythonからSQLite3とMySQLを操作するためのコードが似ているのは、どちらも「Python Database API 2.0」というPythonの標準的なAPI仕様に則っているからとのこと
dictのリストを渡した場合のSQL文のバインドはSQLite3の書き方のほうが簡単でいいと思う
3.3.3 MongoDBへのデータの保存
MongoDB(モンゴーデービー)について
- NoSQLの一種
- ドキュメント型
RDBとドキュメント型のDBの違いについてはこちらを参考にした
ドキュメント指向データベースと列指向データベース
ドキュメント型について
- 各ドキュメントは「BSON」というJSONを元にした、バイナリ形式のデータで扱われる
- ドキュメント毎に異なるデータ構造を持てる
- RDBより複雑なデータ操作を行える
- RDBに比べて書き込み性能が早い
Ubuntuの公式パッケージだとバージョンが古いそうなのでmongodb.orgからリポジトリを追加してインストール
$ sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 9DA31620334BD75D9DCB49F368818C72E52529D4
$ echo "deb [ arch=amd64 ] https://repo.mongodb.org/apt/ubuntu bionic/mongodb-org/4.0 multiverse"
| sudo tee /etc/apt/sources.list.d/mongodb-org-4.0.list
$ sudo apt update
$ sudo apt install -y mongodb-org
apt-keyはパッケージを認証するための公開鍵に関係しているらしい
apt-key は、apt が パッケージを認証するのに使用するキーの一覧を管理するのに使用します。このキーで認証されたパッケージは、信頼するに足ると見なせるでしょう。
apt-key - APT キー管理ユーティリティ - Ubuntu Manpage
なるほど、わからん
次の行でパッケージのリスト(?)を取り込んで、apt updateでその情報をaptに反映させてインストール!みたいな感じだろうか
この辺奥深そうで詳細を調べてたらドツボにはまりそうなので今はスルーで
本記事執筆時点では上記コマンドを入力すると、mongodbのV4.0.12がインストールされるので、書中で指定されている4.0.9にダウングレード…しようと思って色々調べてみたが、よくわかんないので4.0.12のままですすめる
そして sudo service mongod start で起動しようとするとエラーが出るが
WSL の Ubuntu に MongoDB をインストールする - えぢた 2.2 @k_zoar
こちらのブログの方法で解決
pip install pymongo でMongoDB公式のPythonバインディングをインストール
例によってサンプルコードを参考にして、プログラムを作成する
今回はXMLのスクレイピングの項で扱った気象庁のRSSをスクレイピングしてMongoDBに保存する
import lxml.etree
from pymongo import MongoClient
tree = lxml.etree.parse("jma.rss") #ElementTree要素を取得
root = tree.getroot() #RSSのルート要素を取得
client = MongoClient('localhost', 27017)
db = client.scraping # scrapingデータベースを取得。存在しない場合は自動的に作成される
collection = db.rss # rssコレクションを取得。存在しない場合は自動的に作成される
collection.delete_many({})# このスクリプトを何回実行しても同じ結果になるようにするため、コレクションのドキュメントをすべて削除する。
for item in root.xpath("channel/item"):
title = item.xpath("title")[0].text
url = item.xpath("link")[0].text
pub_date = item.xpath("pubDate")[0].text
collection.insert_one({'url': url, 'title': title, 'pub_date': pub_date}) #dictをコレクションに追加
# コレクションのすべてのドキュメントを_idの順にソートして取得する。
for article in collection.find().sort('_id'):
#すべてのドキュメントには_idフィールドにObjectIdと呼ばれる12バイトの識別子が自動で付与されている
print(article['_id'], article['url'], article['title'], article['pub_date'])
実行結果は

インタラクティブシェルから
$ mongo
>>use scraping
>>db.rss.find().sort({'_id',1})
で

同様の結果を得ることができた
3.4 クローラーとURL
3.4.1 パーマリンクとリンク構造のパターン
- パーマリンク
- 1つのコンテンツに対応し、対応するコンテンツが変わらないURL。パーマは不変を意味するPermanentから
- 一覧・詳細パターン
- パーマリンクをもつ詳細ページとそれを一覧するページの組み合わせで構成されているWebサイトのリンク構造のパターンを指す「Pythonクローリング&スクレイピング」独自の用語
3.4.2 再実行を考慮したデータの設計
- データを一意に識別するキー
- クローラーを複数回実行した場合に、同じコンテンツを表すデータが複数存在すると言った場合を防ぐため、データに一意のキーをもたせ、既存のデータと新しく取得したデータを区別する必要がある
- パーマリンクを持つコンテンツの場合、パーマリンクから一意の識別子を抜き出してキーにすると扱いやすくなる
- 例:AmazonのASIN
- データベースの設計
- 一意の識別子を格納するフィールドにユニーク制約を持たせることで一意性を確保する
- Webサイト側の識別子はサイトの更新で変わる可能性があるので、主キーにはこれとは別にサロゲートキーを生成して使うと良い
- 「ナチュラルキー」と「サロゲートキー」の違い
- サロゲートキーの例:MySQLのAUTO_INCREMENT,MongoDBのObjectId(前節のコードを参照)
- Webサイト側の識別子はサイトの更新で変わる可能性があるので、主キーにはこれとは別にサロゲートキーを生成して使うと良い
- 一意の識別子を格納するフィールドにユニーク制約を持たせることで一意性を確保する
3.5 Pythonによるクローラーの作成
この節に関してはサンプル丸写しになっちゃいそうなので、例によって次の記事ではオリジナルプログラムを作成したい。
競馬の出馬表からクローリングして出走馬の詳細データを取得…みたいなものを作れたら。
新しく出てきたものとしては
- timeモジュール
- time.sleep(秒数)で 指定した秒ごとに実行。
3.6 まとめ
次章は実用的なテクニックについて
感想
- RSSフィードをパースして一覧表示するWebアプリを前にRailsで作ったことあるのでそのへんはちょっとなつかしかった
- SQLは現在業務上の研修でOracleを使っている真っ最中だが、NoSQLは存在は知っていても、触れるのは初めてなので勉強になった
- ついにWSL環境ゆえの弊害が生じましたがこのまま突っ走る所存。いざとなったらUbuntu Mateが入ったサブPCで何とかなるかなと
- この記事の7割はアルコールが入った状態で書かれているので誤字脱字、はたまたコードに致命的なエラーが発生している可能性もありますがご了承ください