Watson APIをいつかは触ってみたいと思っていたので触ってみます。今回はWatson APIの中でも日本語資料が少なく、かつ面白そうなPersonality Insightsについて紹介したいと思います。ホントはサンプルやった上でプラスαのことしたかったけど間に合わなかったごめんなさい!
Personality Insightsとは
ドキュメントにはこう書かれています。
Watson Personality Insights: Personality Insights は、トランザクション・データや
ソーシャル・メディアのデータから洞察を引き出し、購買決定、意図、行動特性などを判別する
心理的特性を識別して、顧客転換率の向上に役立てることができます。
ちょっと訳がわかりづらい😇
Watson APIの紹介記事ではこう書かれています。
「Personality Insights(性格分析)」は、Twitter のツイートや Eメールなどのテキストを通じて
パーソナリティーの特性を分析するというもの。例えばツイートを分析すると「協調性」や「外向性」
「誠実性」など、いわゆる「ビッグファイブ」という個性を表す基準をはじめ、
「衣服を買うときは品質を優先する」傾向にある、といった行動の分析までできるのが面白いところ。
つまりある文章からその人の性格や傾向がわかるというものです。
Personality Insights (性格分析)によると、Personality Insightsは顧客とのパーソナライズしたコミュニケーションや企業、大学志願者とのマッチングに活用することができるとされています。
また、テキストから人の性格を見破るAIは本物かという記事によると、記事を公開する前にこのAPIに投げて印象の取られ方をチェックして炎上を防いだり、社員が落ち込んでいるタイミングを検知することができたり、顧客の消費傾向を把握した上で商品を提案することができると言われています。
ここから先の話にあまり興味なくても、デモはやってみると面白いです。今まで自分が書いたことある文章とかを突っ込むとパーソナリティ診断をやってくれます。デモの内容については自分の性格をWatson で“10秒解析”してみたの記事を見るとわかりやすいと思います。
なんとなくわかったところでチュートリアルをやってみます。
アカウント作成
アカウントはこちらから作成できます。ちょっといじってみるくらいなら無料アカウントでも全然大丈夫そうです。
ライトと書いてあるAPIは無料でも使うことができます。

チュートリアル
Getting started tutorialを適宜訳しながら進めます。
インスタンス作成
※ドキュメントの手順にはGo to the Watson Developer Console Services page.と書いてあったのですが、Servicesページ開いても500エラーが出て何もできませんでした。が、手順の内容を見ているとPersonality Insightsの説明ページから意図している手順を踏めそうなのでこっちで試しています。
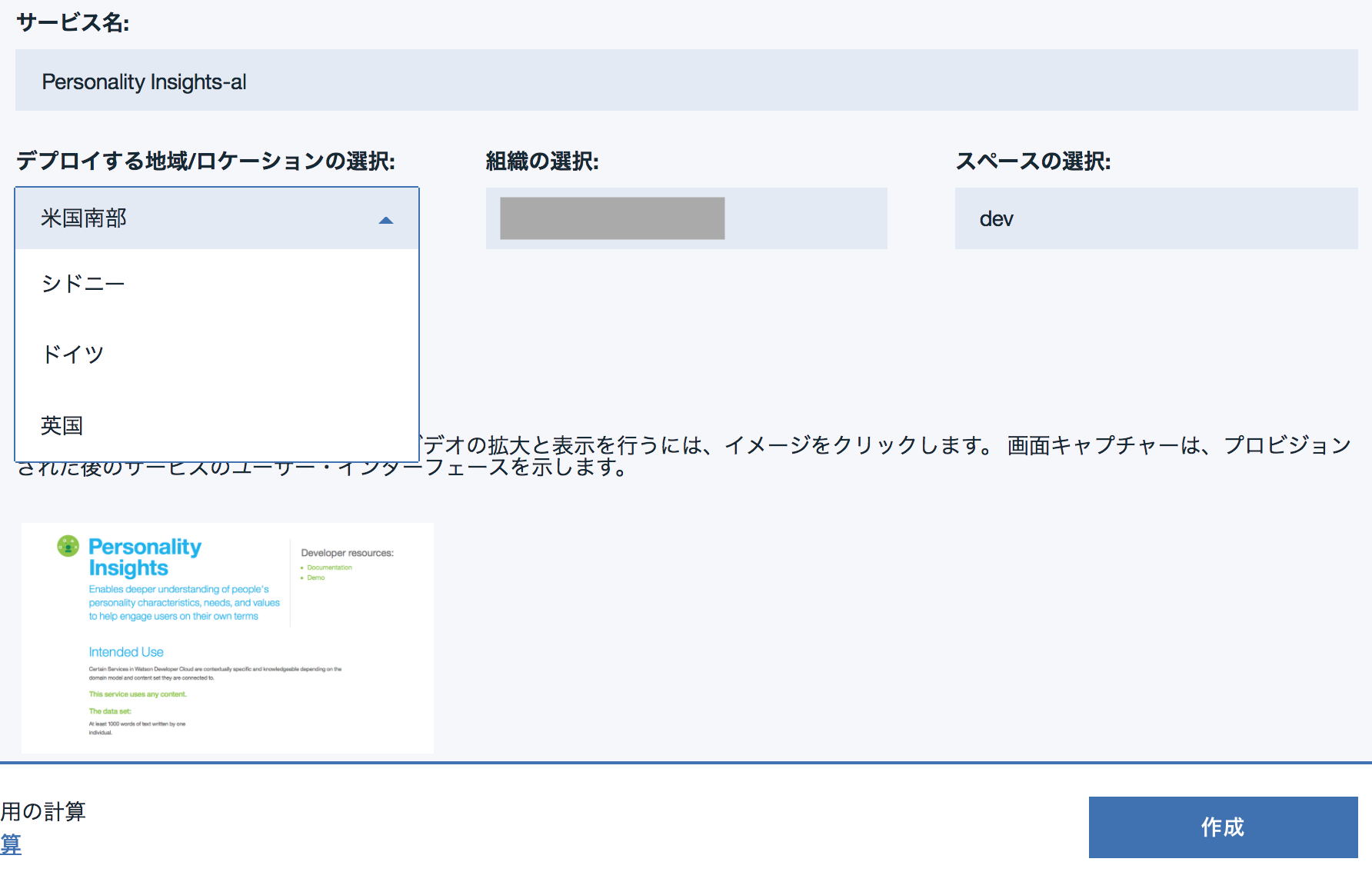
Personality Insightsの説明ページで試しにサービス名をpersonality-tutorialにして作成ボタンをクリックします。私の場合ロケーションは実質米国南部しか選択できませんでした(他は使用可能な○○がありませんと出てしまう)。
認証周りの準備をする
さっき作成ボタンをクリックした時にページ遷移しているはずなのでそこでこちゃこちゃやります。

こんなかんじのメニューになっているのでサービス資格情報のタブをクリックします。まだ何も資格情報を作成していない場合は適当に作ります。
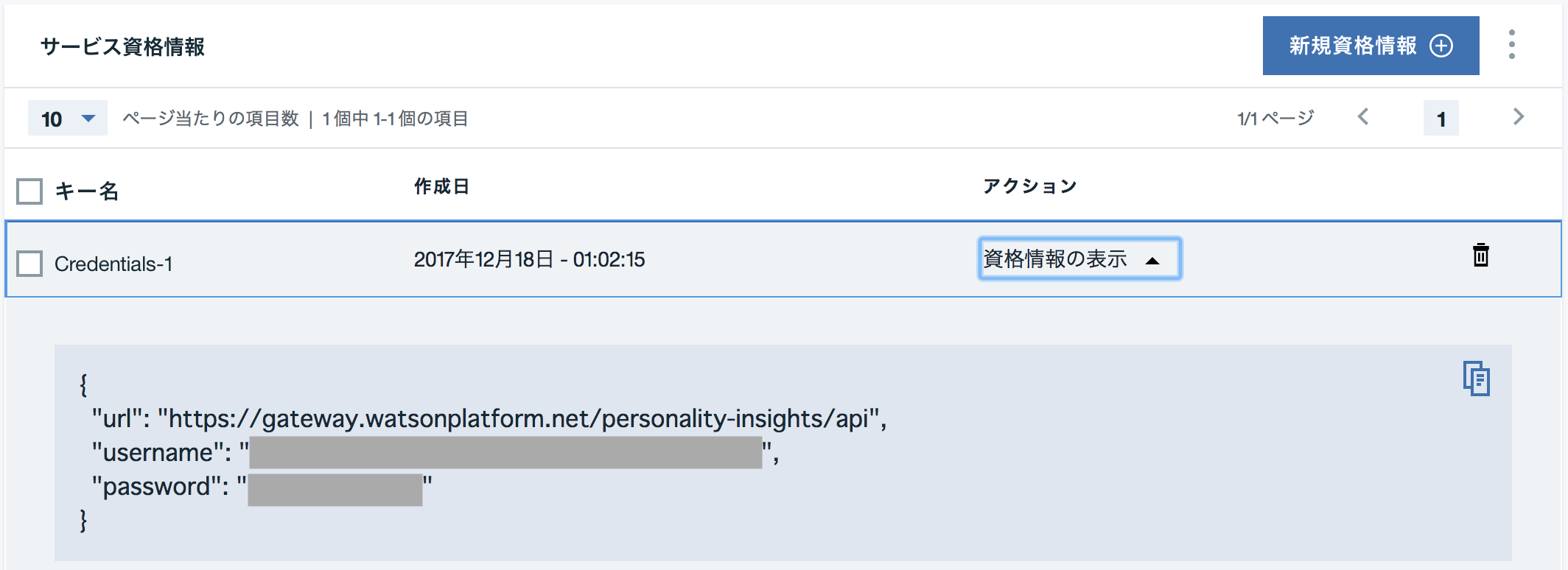
これらの値はあとで使うので覚えておきます。
ステップ1: テキストを入力してJSONを受け取る
最初の例はプレーンなテキストファイルをPOST /v3/profileメソッドに送ってJSONのレスポンスを得る方法です。
profile.txtというテキストファイルをダウンロードします。
コマンドラインツールで以下のコマンドを打ちます。ユーザ名、パスワード、テキストファイルまでのパスは自分の環境に値を合わせます。これによってメタデータ入りのJSONデータが返ってきます。
curl -X POST --user {username}:{password} \
--header "Content-Type: text/plain;charset=utf-8" \
--data-binary "@{path_to_file}profile.txt" \
"https://gateway.watsonplatform.net/personality-insights/api/v3/profile?version=2017-10-13"
{
"word_count": 15223,
"processed_language": "en",
"personality": [
. . .
],
"needs": [
. . .
],
"values": [
. . .
],
"behavior": [
. . .
],
"consumption_preferences": [
. . .
],
"warnings": []
}
レスポンスの各フィールドの説明
レスポンスのJSONデータにはいろいろ入っていますが、ざっくり各フィールドの意味を書くとこんなかんじ。詳しい説明はThe Profile objectをご確認ください。
-
word_count:入力したテキストのワード数 -
processed language:入力されたテキストを処理する時に使った言語モデル -
personality:入力したテキストから推測される、ビッグファイブの軸情報 -
needs:入力したテキストから推測される欲求、需要 -
values:入力したテキストから推測される価値観 -
behavior:入力したコンテンツの時系列の分布(タイムスタンプが含まれたJSONファイルが入力された時のみ返す) -
consumption_preferences:各カテゴリに対する消費傾向(consumption_preferencesパラメータがtrueになっている時のみ返す) -
warnings:入力したテキストに何かしらあったら入ってくるメッセージ
上記のpersonality, needs, valuesによって文章からビッグファイブ(パーソナリティの特徴を5つの要素で説明するもの)情報を得ることができます。このAPIでは、テキスト筆者の分析結果と、サンプル集団の分析結果とを比較して各要素のばらつきを出してくれます。
パーソナリティ分析の出力
このような出力がされます。
{
. . .
"personality": [
{
"trait_id": "big5_openness",
"name": "Openness",
"category": "personality",
"percentile": 0.8011555009553,
"raw_score": 0.77565404255038,
"significant": true,
"children": [
{
"trait_id": "facet_adventurousness",
"name": "Adventurousness",
"category": "personality",
"percentile": 0.89755869047319,
"raw_score": 0.54990704031219,
"significant": true
},
. . .
]
},
. . .
],
"needs": [
{
"trait_id": "need_challenge",
"name": "Challenge",
"category": "needs",
"percentile": 0.67362332054511,
"raw_score": 0.75196348037675,
"significant": true
},
. . .
],
"values": [
{
"trait_id": "value_conservation",
"name": "Conservation",
"category": "values",
"percentile": 0.89268222856139,
"raw_score": 0.72135308187423,
"significant": true
},
. . .
],
. . .
}
欲求(needs), 価値観(values)には特性を表す配列が用意されます。ビッグファイブ特性ではトップレベルの配列が因子を表し、その次のレベルで各因子の程度が表されます。ビッグファイブの各フィールドの意味はざっくりこんなかんじ。
-
trait_id:一意のID -
name:特性の名前 -
category:特性のカテゴリ(personality、needs、values) -
percentile:特性を正規分布化したもの(より詳しい情報はPercentiles for personality characteristicsで) -
raw_score:特性の生のスコア。このフィールドはraw_scoreパラメータをtrueにした時にしか返ってきません。より詳しい情報はRaw scores for personality characteristicsで。 -
significant:その特性が入力した言語にとって意味のあるものかどうかを指し示すもの。このフィールドは英語、スペイン語、日本語入力の全ての特性でtrueになっています。サービスモデルが十分意味のある成果を出せないとしているアラビア語、韓国語の入力に関してはこのフィールドはfalseになっています。詳しい情報はLimitations for Arabic and Korean inputで。 -
children:ビッグファイブの各因子のより詳細な結果が入った配列。この配列はビッグファイブに関するフィールドのときのみ返されます。
詳細はPersonality characteristics outputにて。
ステップ2: JSONを送って、詳細なJSONデータを受け取る
2つ目の例ではJSONファイルを/v3/profileメソッドに渡します。ツイートが複数含まれたprofile.jsonをダウンロードし、今度は以下のコマンドを打ってみます。
curl -X POST --user {username}:{password} \
--header "Content-Type: application/json" \
--data-binary "@{path_to_file}profile.json" \
"https://gateway.watsonplatform.net/personality-insights/api/v3/profile?version=2017-10-13&consumption_preferences=true&raw_scores=true"
今回も同じようにJSONデータが返ってきます。このデータの中には、他の集団と比較しない、テキスト筆者本人の特性に基づくraw_scoreも含まれています。
今回の入力テキストにはタイムスタンプが含まれているので、行動特性も出力することができます。
行動に関する出力
このような出力がされます。
{
. . .
"behavior": [
{
"trait_id": "behavior_sunday",
"name": "Sunday",
"category": "behavior",
"percentage": 0.21392532795156
},
{
"trait_id": "behavior_monday",
"name": "Monday",
"category": "behavior",
"percentage": 0.42583249243189
},
. . .
{
"trait_id": "behavior_0000",
"name": "0:00 am",
"category": "behavior",
"percentage": 0.4561049445005
},
{
"trait_id": "behavior_0100",
"name": "1:00 am",
"category": "behavior",
"percentage": 0.12209889001009
},
. . .
],
. . .
}
behaviorフィールドはタイムスタンプが含まれたJSONが入力されたら返ってきます。このフィールドには何曜日の何時に関する情報なのかが入ります。
各フィールドの意味は以下の通りです。
-
trait_id:曜日や時間が付与された一意のID -
name:特性の名前 -
category:特性のカテゴリ名。ここでは常にbehavior。 -
percentage:1週間のうち、あるいは1日のうちどれくらいそのコンテンツに関する出来事が起こっていたかを表すパーセンテージ。詳しい情報はPercentages for behavioral characteristicsへ
ここでは消費嗜好のスコアも知ることができます。スコアはテキスト筆者がどんな製品、サービス、活動を好む可能性があるのかを教えてくれます。
より詳しい情報はBehavioral outputを見てください。
消費嗜好に関する出力
{
. . .
"consumption_preferences": [
{
"consumption_preference_category_id": "consumption_preferences_shopping",
"name": "Purchasing Preferences",
"consumption_preferences": [
{
"consumption_preference_id": "consumption_preferences_automobile_ownership_cost",
"name": "Likely to be sensitive to ownership cost when buying automobiles",
"score": 0
},
. . .
]
},
{
"consumption_preference_category_id": "consumption_preferences_health_and_activity",
"name": "Health & Activity Preferences",
"consumption_preferences": [
{
"consumption_preference_id": "consumption_preferences_eat_out",
"name": "Likely to eat out frequently",
"score": 1
},
. . .
]
},
. . .
{
"consumption_preference_category_id": "consumption_preferences_volunteering",
"name": "Volunteering Preferences",
"consumption_preferences": [
{
"consumption_preference_id": "consumption_preferences_volunteer",
"name": "Likely to volunteer for social causes",
"score": 0
}
]
}
],
. . .
}
consumption_preferencesパラメータがtrueの場合、Profileオブジェクトにconsumption_preferencesが入って返ってきます。このフィールドには各カテゴリのConsumptionPreferencesCategoryオブジェクトが含まれています。
各フィールドの意味は以下の通りです。
-
consumption_preference_category_id:消費嗜好カテゴリの一意なID -
name:消費嗜好カテゴリ名 -
consumption_preferences:各嗜好カテゴリの結果を持つConsumptionPreferencesオブジェクトの配列
各嗜好はConsumptionPreferencesを通して説明されます。カテゴリの中には1つの嗜好で構成されるものもあれば、複数の嗜好で構成されることもあります。中身は以下のフィールドで構成されています。
-
consumption_preference_id:消費嗜好に関する一意なID -
name:消費嗜好名 -
score:テキスト筆者が、ある物事についてどれだけ好んでいるかを表す数値です。0.0〜1.0の間の数値で表されます。詳細についてはConsumption preferencesから。
これらの詳細はConsumption preferences outputに書かれています。
ステップ3: JSONを送って、詳細なCSVデータを受け取る
3つ目の例は2つ目と似ていて、同じJSONを渡して同じ結果を要求します。異なる点としてはAcceptヘッダーでカンマ区切りのCSVを指定し、text/csv形式になるようにしています。また、--outputオプションを付けてprofile.csvという名前で出力するようにしたり、パラメータにcsv_headers=trueを入れて出力結果にカラムのヘッダーを付けるようにしたりしてます。
curl -X POST --user {username}:{password} \
--header "Content-Type: application/json" \
--header "Accept: text/csv" \
--data-binary "@{path_to_file}profile.json" \
--output profile.csv \
"https://gateway.watsonplatform.net/personality-insights/api/v3/profile?version=2017-10-13&consumption_preferences=true&raw_scores=true&csv_headers=true"
CSV出力
このサービスではAcceptヘッダーでtext/csvを指定すればカンマ区切りのCSV形式で出力することができます。CSVのアウトプットはJSONでのアウトプットと似たような結果を得ることができます。JSONと同様に、入力データがタイムスタンプを含んでいるか、ロースコアや消費傾向のデータまで求めているかどうかによって出力が変わります。
ただしJSONとは異なり、CSVでは固定長のカラムが返ってきます。最初の行はcsv_headersパラメータをtrueにした場合はカラムのラベルになっています。2番目の行は分析結果になっています。
CSVで出力される全てのカラムについての説明はUnderstanding a CSV profileに書かれています。
まとめ?
- Personality Insightsは自然言語からその人のパーソナリティを推測できるAPI
- 採用面接の適性検査的なものとして利用できそう
- 自分のブログ記事を突っ込んで冒頭で紹介したデモをやったかんじだと、精度はまあまあ高そう