この記事はWWDC2017のNatural Language Processing and your Appsのセッションをざっくり日本語に訳したものになります。適宜「※」にて簡単な補足を入れています。何か間違っていたら編集リクエストをお願いします。
イントロダクション
自然言語を入力、出力するアプリにおいてユーザ体験を大幅に向上させうる自然言語 APIについて紹介します。
ファーストパーティアプリにおける事例
iMessageを立ち上げたとします。固有名詞である「Vatnajökull」を入力しようとしますが、Batmanなど異なる変換候補が出てきてしまっています。
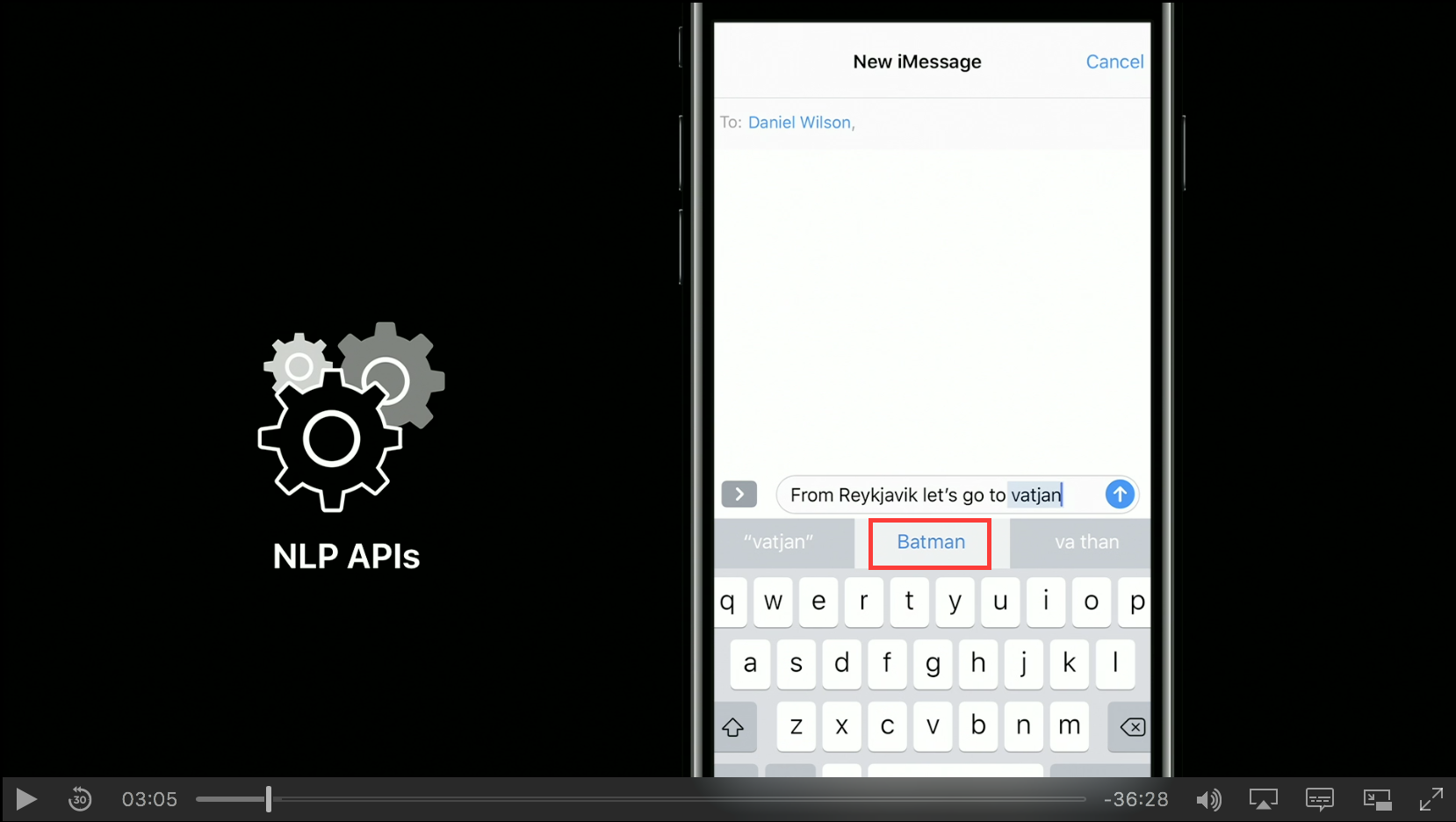
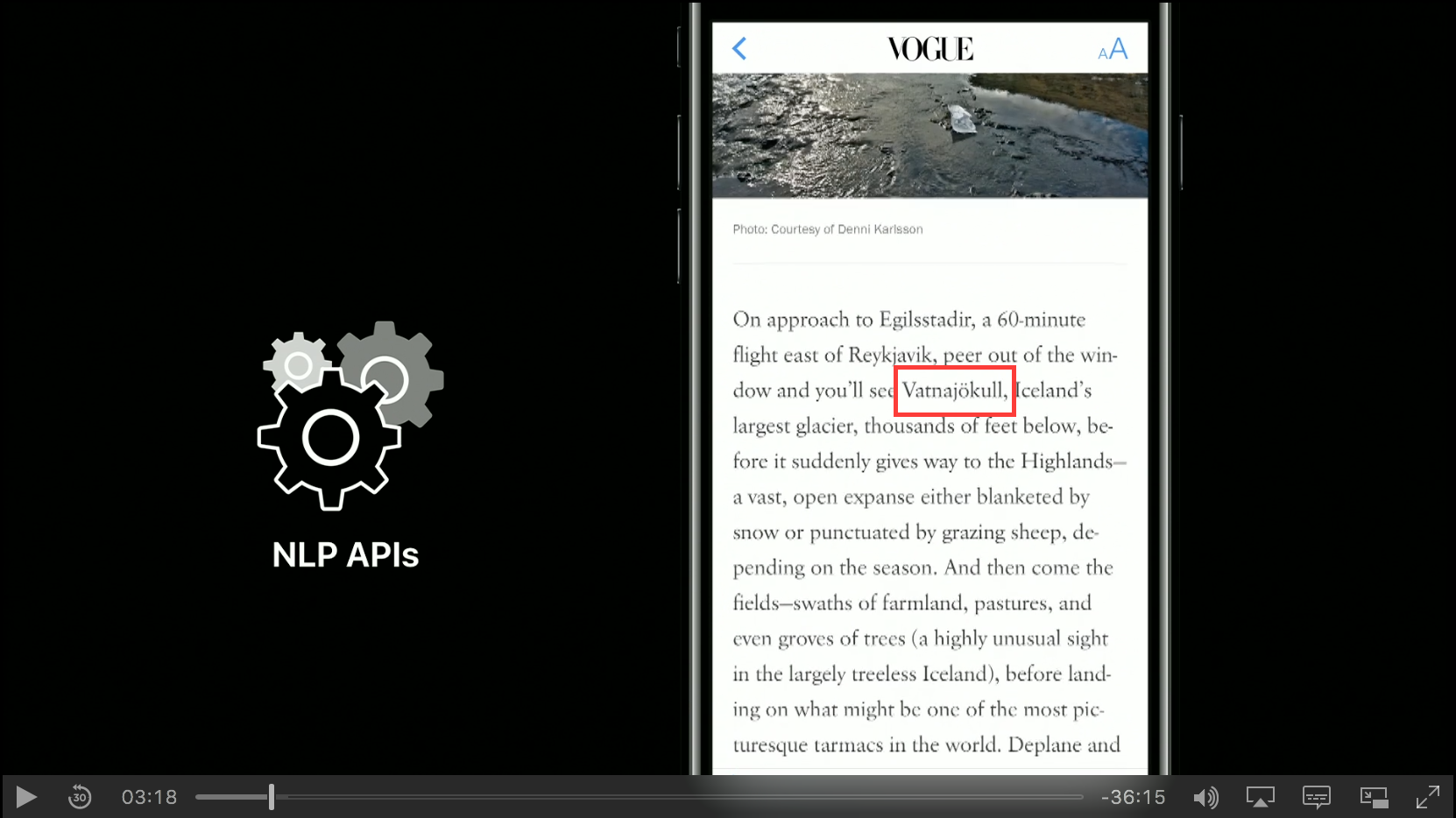
ここでNewsアプリを立ち上げてアイスランドのことが書かれた記事を読んでみます。この記事の中には「Vatnajökull」などの固有表現も出てきます。ここで機械学習の力を借りつつ自然言語処理をして名前を抽出します。
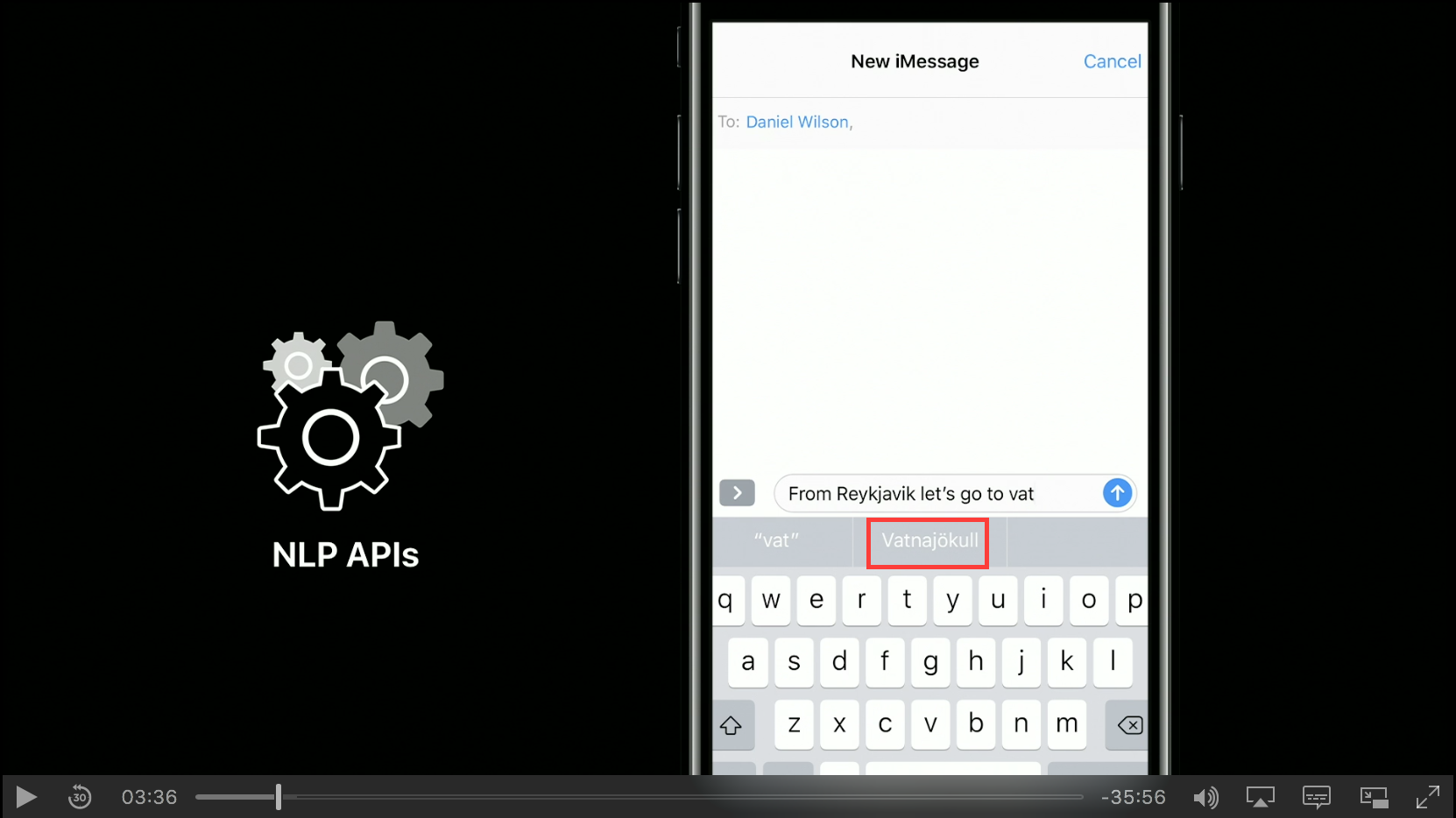
もう一度iMessageアプリに戻って先程と同じように「Vatnajökull」を入力してみます。するとNLP APIによって変換候補に「「Vatnajökull」」が出て来るようになります。
これから話すこと
ナマの文章から意味のある情報を抽出し、それをユーザ - デバイス間、もしくはデバイス - デバイス間での体験に役立てます。ここでは基礎的な部分の処理を説明してNLP APIを理解してもらおうと思います。
自然言語処理の工程
言語識別
文章を処理する時にはまずその文章が何の言語で書かれているかを知らなければなりません。これには機械学習の技術を使用します。
トークン化
1つの文章から段落、段落から文、文から単語へとスコープを変化させつつ意味のある塊に分割していきます。
ここで文レベルの例をあげます。例文は「Mr. Tim Cook presided over the earnings report of Apple Inc. on Tuesday.」です。単に「ピリオドが来たら文を区切る」というルールベースでチャンキング(※あるものを小さな塊に分割したり大きなまとまりにまとめたりすること)しようとすると、この文は3文から成り立っていると誤解してしまいます。なのでNLP APIの文のトークナイズでは適切にチャンキングできるアプローチを提供します。
中国語のように空白を持たない言語はさらに複雑になります。マシンが解析できるようにするためには文を単語に分割する必要があります。それがつまりトークン化です。
タグ付け
タグ付けとはテキスト内の全ての単語に品詞を振ることです。以下が例になります。
Mr.(Noun) Tim(NNP) Cook(NNP) presided(Verb) over(PP) the(DT) earnings(Noun)
report(Noun) of(PP) Apple(Noun) Inc.(Noun) on(PP) Tuesday(Noun).(PUNCT)
アプリ開発者のあなたにとってこれは何に役立つのでしょうか。例えば辞書サービスを開発している場合のことを考えてみます。bearという単語に焦点を当てます。bearは名詞の可能性も動詞の可能性もあります。もしクリックした時にそれが動詞であるということがわかっていれば(品詞に応じた)正しい意味を表示することができ、ユーザの役に立てることができます。
レンマ化
単語は現在形、過去形などにより形を変えることがあります。しかし共通する根幹の部分はあります。これをレンマと呼びます(※辞書の見出し語を抽出すると思えば良い)。例を見てみます。
Mr. Tim Cook presided over the earnings report of Apple. The stock was up 3% after hours.
presidedという単語は動詞であり、根幹部分はpresideです。同じように、hoursという単語は名詞ですが、その根幹部分はhourになります。これがなぜ重要なのでしょうか。英語のような言語では無意味に思えます。しかしロシア語やトルコ語のような複雑な言語の場合はレンマや接尾辞に分解することは非常に重要です。
固有表現抽出
固有表現抽出とは文章から自動的に名前を抽出することです。そしてその名前は異なるカテゴリに分類されます。例を見てみます。
Mr. Tim Cook presided over the earnings report of Apple Inc. on Tuesday.
Mr. Tim Cookは人名であり、Apple Inc.は組織名になります。固有表現抽出では機械学習と言語学的な情報を用いて自動的にタグ付けをしていきます。
NLP API
今まで自然言語処理の基礎部分について説明してきましたが、私達はこれらの処理をどのように行えば良いのでしょうか。その疑問に答え、様々なことをやってくれるのがNLP APIになります。以後はNLP APIの使い方を説明します。NLP APIはNSLinguisticTaggerを用いることで全てのAppleプラットフォームで使えます。すでにNSLinguisticTaggerをアプリに組み込んでいる人もいるでしょう。これはセグメンテーションやタグ付けに用いられ、テキストを読み込ませると解析結果を出力してくれます。
NSLinguisticTagger
詳しいことはドキュメントをご参照ください。ここではNSLinguisticTaggerの新機能に注目してみます。今回大幅な改良を行いました。
タグ付け単位種別の増加
以前のNSLinguisticTaggerは単語に対してのみ使用可能でした。しかし単語レベルの解析をするだけでは不十分なこともあります。新しいNSLinguisticTaggerでは単語以外の単位(文、段落、文書)も持っています。
public enum NSLinguisticTaggerUnit : Int {
case word
case sentence
case paragraph
case document
}
利用可能なタグスキームの取得
ただし全ての単位で全てのタグスキームが使えるわけではありません。文に対して品詞を聞いても意味を成しません。そこで互換性のある単位とスキームを見つけるためのAPIが用意されています。
class func availableTagSchemes(for unit: NSLinguisticTaggerUnit, language: String)
-> [NSLinguisticTagScheme]
単位と言語を指定することで利用可能なタグスキームを取得する事ができます。
言語識別メソッド
今までNSLinguisticTaggerを使った言語識別が難しいと感じていたのは、単語レベルで処理しようとしているからです。NSLinguisticTaggerは与えられた全ての単語に対して言語識別をしようとします。しかも単に言語を識別したいだけの時でも、コードに恐ろしく膨大なテキストを与えなければなりませんでした。しかしdominantLanguageを呼ぶことによってこんなことはしなくてよくなります。文字列を渡すだけで言語の識別結果を得ることができます。
さらに、Swift4ではタグやタグスキームのためのnamed typesができました。
基礎部分の大幅な改善
NSLinguisticTaggerの基礎部分の実装を大幅に改善しました。APIインターフェースに変わりはありません。これにより、パフォーマンスの向上、精度の向上、より多くの言語へのサポートが実現されました。
ここからはAPIについて掘り下げてみようと思います。単にコードを示すだけでなく、WinnowとWhiskという2つのアプリ通じて例示していきたいと思います。WinnowはmacOSアプリで、WhiskはiOSアプリです。
活用例
Winnowの場合
Winnowは説明文とともに写真を保存するアプリです。私は家族や友達などと多くの写真を撮るので、写真に説明文をつけて残しておきたいと思っています。残し方は音声でも、文字でも構いません。
Winnowでは撮った写真に対して説明文を付けられます。多言語対応しています。この説明文がどのように作られているのかは今回問いません。私は1人のアプリ開発者としてこれをAppStoreに出したのですが、もっと機能を追加したいと思います。
まず最初にやりたいことは検索機能の追加です。これまで書いてきた説明文を使って、例えば子供の誕生日と入力した時に関連する写真全てが見られるようにしたいと思います。ここで試しにhikeというクエリを投げてみますが残念ながら結果は得られません。なぜならhikeという文字列が説明文の中になかったからです。そこでNLPの力を使って検索体験の改善を行いたいと思います。
hikeというクエリを投げた時にhikeの変化形のhiked, hikes, hikingという単語も含めて検索し、関連する写真が出てくるようにしたいと思います。NLP APIのレンマ化の技術を用いてこれをどのように実現するのか見てみましょう。
まず最初にやらなくてはならないことは言語識別です。なぜならあなたの友達がフランス語など異なる言語で説明文を送ってくる可能性があるからです。言語識別が終わったらテキストを単語、文、段落などの単位にトークナイズします。それが終わったら品詞タグ付けを行い、最後にレンマ化を行います。これら全てをWinnowアプリ内で行えば検索体験を改善できます。これからデモを行いつつコードを見せて、あなたのアプリでもとても簡単に使えるということを示したいと思います。
import Foundation
let tagger = NSLinguisticTagger(tagSchemes: [.language], options: 0)
tagger.string = "Die Kleinen haben friedlich zusammen gespielt"
let language = tagger.dominantLanguage
言語識別はたった3行で実現できます。Foundationをインポートして、NSLinguisticTaggerオブジェクトのインスタンスを作成して、タグスキームを指定します。言語識別だけであればスキームはlanguageを指定するだけで構いません。その後解析したい文字列をセットします。この場合、文字列はドイツ語です。ここでdominantLanguageメソッドを使って言語を取得します。水面下では複雑な機械学習が使われておりあらゆる種類のモデルが使われていますが、あなたは結果を得るだけでよく、自分のアプリの使い勝手を向上させることができます。
トークン化について見てみましょう。
import Foundation
let tagger = NSLinguisticTagger(tagSchemes: [.tokenType], options: 0)
let text = "NSLinguisticTagger provides text processing APIs.\n NSLinguisticTagger 是苹果的文字理处平台。"
tagger.string = text
let range = NSRange(location: 0, length: text.utf16.count)
let options: NSLinguisticTagger.Options = [.omitPunctuation, .omitWhitespace]
tagger.enumerateTags(in: range, unit: .word, scheme: .tokenType, options: options) { tag, tokenRange, stop in
let token = (text as NSString).substring(with: tokenRange)
// Do something with each token
}
もう一度NSLinguisticTaggerオブジェクトのインスタンスを作成します。今度はタグスキームにtokenTypeを指定しました。テキストとテキスト範囲を指定します。NSLinguisticTaggerはまだNSRangeを扱っていますが、次のリリースでRangeに移行したいと思っています。今回は範囲を文字列全体にして解析してみます。今回の場合は句読点と空白を除去するオプションを設定します。最後に全ての単語を取り出して、もとの文字列からトークンを部分文字列として見つけ出します。
次にレンマ化について見てみましょう。
import Foundation
let tagger = NSLinguisticTagger(tagSchemes: [.lemma], options: 0)
let text = "Great hikes make great pics! Wonderful afternoon in Marin Country."
tagger.string = text
let range = NSRange(location: 0, length: text.utf16.count)
let options: NSLinguisticTagger.Options = [.omitPunctuation, .omitWhitespace]
tagger.enumerateTags(in: range, unit: .word, scheme: . lemma, options: options) { tag, tokenRange, stop in
if let lemma = tag?.rawValue {
// Do something with each lemma
}
}
コードを見てみると先ほどと非常に似ています。もう一度NSLinguisticTaggerオブジェクトのインスタンスを作成します。今回はlemmaをタグスキームとして指定します。テキストと分析したい範囲を指定します。また句読点と空白を除去するオプションを設定します。全ての単語を列挙したらその単語のレンマが何かを判別します。一度レンマ化すると、他のアプリでもこのレンマをインデキシングすることができます。
NLPの力を使ったWinnowのデモを見せます。初版のWinnowは非常にシンプルです。各写真に説明書きがあり、文字列検索を用いて写真を探すことができます。当初のWinnowにはNLPの力を使っていません。そのためhikeと検索した時にhikingなどの表現が含まれている写真があっても出てこないことがありました。これらの単語が関連したものであるということがわからないのです。どうすべきでしょうか。コードを見てみましょう。
fileprivate func setOfWords(string: String, language: inout String?) -> Set<String> {
var wordSet = Set<String>()
string.enumerateSubstrings(in: string.startIndex..<string.endIndex, options: .byWords) {
word, _, _, _, in
guard let word = word else { return }
wordSet.insert(word.lowercased())
}
return wordSet
}
この関数はこのアプリにおける検索処理の中心部分で、インデキシングなどの役割を担っています。この関数は説明文や検索語などの文字列を受け取り、それを検索に使用する単語セットに変換しています。これはナンセンスです。単に標準のStringメソッドを部分文字列に使っているのと同じです。このメソッドが行っているのは全ての単語を受け取り、小文字に変換することだけです。大文字小文字は区別されません。
ではこれを改善してみましょう。馴染みのあるLinguisticTaggerを用いて置き換えてみます。
fileprivate func setOfWords(string: String, language: inout String?) -> Set<String> {
var wordSet = Set<String>()
let tagger = NSLinguisticTagger(tagSchemes: [.lemma, .language], options: 0)
let range = NSRange(location: 0, length: string.utf16.count)
tagger.string = string
if let language = language {
// If language has a value, it is taken as a specification for the language of the text and set on the tagger.
let orthography = NSOrthography.defaultOrthography(forLanguage: language)
tagger.setOrthography(orthography, range: range)
} else {
// If language is nil, then the tagger sets it based on automatic identification of the language of the string.
language = tagger.dominantLanguage
}
tagger.enumerateTags(in: range, unit: .word, scheme: .lemma, options: [.omitPunctuation, .omitWhitespace]) { tag, tokenRange, _ in
let token = (string as NSString).substring(with: tokenRange)
// Each word of the text is inserted into the result set (in lowercase form).
wordSet.insert(token.lowercased())
if let lemma = tag?.rawValue {
// If there is a lemma, it is also inserted into the result set (in lowercase form).
wordSet.insert(lemma.lowercased())
}
}
return wordSet
}
今回の場合、スキームはレンマを使用します。taggerに何の言語なのかを教えてあげます。もし言語がわからない状態でここにきたらdominantLanguageを使って判別します。次にレンマスキームを使って処理していきます。トークナイズも行います。レンマを取得したらそれも検索に使う語として取っておきます。それでは試してみましょう。
この版のWinnowはhikeと入力した時にhiking、hikesなどの語が使われている写真もヒットします。他の言語でもできます。フランス語の動詞marcherで試してみても、ドイツ語の動詞spielen で試してみても、活用形は同じ単語として認識されます。
Whiskの場合
私はSNSアカウントが複数あるので各アカウントにログインしてフィードを見たりコメントすることに一種の苦痛を覚えます。Whiskは異なるSNSのフィードを取得し、それを1つのインターフェースで見ることのできるアプリです。Whiskには問題がありました。見づらいのです。あるものはPinterestで、Facebookで、Twitterで見ているからです。もっとユーザのエンゲージメントを高めたいと思いました。そこで、フィードを興味を持った人や組織、場所にもとづいて整理しようと思いました。
ここではTwitterやFacebookで多くのものをフォローしているとします。NLP APIを使って全てのフィードの全てのコンテンツに対して固有表現抽出や自動タグ付けをします。Tim CookやStevie WonderのフィードもNLP APIを使って解析します。機械学習を使って仕上げます。こうする事によってユーザ体験が向上します。
様々なSNSメディアからフィード情報を送ってくるAPIがあると仮定します。このAPIをNLP APIを介してWhiskに組み込むとします。その場合まず最初に言語識別を行います。次に、フィードは文や段落から成り立っているのでトークナイズを行います。最後に、要素を抽出するために固有表現抽出を行います。ではサンプルコードを用いてどれほど簡単に実装しているのか見てみましょう。
import Foundation
let tagger = NSLinguisticTagger(tagSchemes: [.nameType], options: 0)
let text = "Tim Cook is the CEO of Apple Inc. which is located in Cupertino, California"
tagger.string = text
let range = NSRange(location: 0, length: string.utf16.count)
let options: NSLinguisticTagger.Options = [.omitPunctuation, .omitWhitespace, joinNames]
let tags: [NSLinguisticTag] = [.personalName, .placeName, .organizationName]
tagger.enumerateTags(in: range, unit: .word, scheme: .nameType, options: options) { tag, tokenRange, stop in
if let tag = tag, tags.contains(tag) {
let name = (text as NSString).substring(with: tokenRange)
}
}
NSLinguisticTaggerのインスタンスを作成することから始めます。今度はタグスキームをnameTypeにします。今度は固有名詞の種類を調べるわけです。調べたい単語や文字列の範囲、オプションを指定します。よく見ると今まで見たことのないjoinNamesというオプションがあります。固有名詞は複数のトークンからできている場合もあります。例えばTim Cookという名前は2つのトークンから構成されています。これを1つの人名として取得したいのでトークンを結合するオプションを付けます。今度は私が興味を持っている人名、場所目、組織名のタグ付けをします。順番にトークンを見ていって、興味があるタグを持つトークンが出てきたらそれを取得することができます。またデモをしてみたいと思います。
シミュレータでWhiskを動かしてみます。それぞれのSNSを見に行くのは面倒です。私達がしたいことは固有名詞によってこれらの情報を整理することです。下部のボタンをタップするとよく使う順で全ての名前をリストアップしたものが出てきます。「Tim Cook」を選択すると、Tim Cookについて言及した記事を見ることができます。該当部分にハイライトもされています。どのように実現されているのか、コードを見てみましょう。
func extractEntities(tags: [NSLinguisticTags]) -> [NamedEntity] {
let text = loadResourceText()
let tagger = NSLinguisticTagger(tagSchemes: [.nameType], options: 0)
tagger.string = text
let options: NSLinguisticTagger.Options = [.omitPunctuation, .omitWhitespace, joinNames]
let range = NSRange(location: 0, length: text.utf16.count)
var extractedEntities: [NamedEntity] = []
tagger.enumerateTags(in: range, unit: .word, scheme: .nameType, options: options) { tag, tokenRange, _ in
if let tag = tag, tags.contains(tag) {
let token = (text as NSString).substring(with: tokenRange)
extractedEntities.append(NamedEntity(token: token, tag: tas, range: tokenRange))
}
}
}
Whiskの中で重要なメソッドはこれです。テキストから固有名詞を抽出してくれます。tagger作成、nameTypeスキームの指定、オプションの指定を行います。NamedEntityインスタンスを作成し、トークン、タグ、範囲の情報を詰め込みます。固有表現抽出をするために必要なのはこれだけです。
なぜNLP APIを使うべきなのか
2つのアプリを通してNLP APIを知って、このAPIのメリットについてもっと知りたいと思ったでしょう。メリットの1つは「均一なテキスト処理」です。今これらのNLP APIは全てのAppleプラットフォームで使用可能になっています。全てのプラットフォームで一貫したテキスト処理と、一貫したユーザ体験を得られることになります。このAPIはファーストパーティのアプリで使うものと同じです。なのであなたのアプリユーザが他のAppleアプリと同じ体験を得られることになります。
メリットの2つめはプライバシーです。NLPにおける機械学習は全て端末内で行われており、ユーザのデータは端末から離れることはありません。これはあなたにとってもクラウドAPIを持つ必要がないので良いことだと思います。
それに加えNSLinguisticTaggerの根底の実装改良も今回のリリースで行われました。その結果、パフォーマンスが大幅に向上しました。全てのプラットームのデバイスで最適化されていますし、マルチスレッドに対応、スピードアップもされています。例えば中国語のトークナイズはiPhone 7で計測した時に30%も速く処理できました。固有表現抽出は80%速くなりました。過去NSLinguisticTaggerを使ったことがないあなたにとってはあまり意味がないように感じられるかもしれないので、生データを見てみましょう。
iOSデバイス上で1スレッドで品詞タグ付けをすると1秒間に50,000トークン処理できます。全てiOSデバイス上で機械学習を使っています。一方固有表現抽出では1秒間に40,000トークン処理できます。さて、あなたが普段読む記事の平均的な長さはどれくらいでしょうか。約400, 500語です。つまり何百もの記事を処理し、固有表現抽出をするのに1秒しかかかりません。これはとても素晴らしいことです。
NSLinguisticTaggerは多くの言語に対応しています。ローカライズされたアプリを開発する人にとって大変便利なものとなるでしょう。言語判定は29のスクリプトと52の言語でサポートされています。トークナイズは全てのiOS, macOSのシステム言語でサポートされています。レンマ化、品詞タグ付け、固有表現抽出は8つの言語(英語、フランス語、イタリア語、ドイツ語、スペイン語、ポルトガル語、ロシア語、トルコ語)に対応しています。今回のリリースでは英語以外の全ての語に対応しました。
英語のモデルも大幅に改良されたのでその正確さについて話します。簡潔に説明するために英語とスペイン語の結果だけを見せます。両言語とも正確さは90%以上です。ここではNSLinguisticTaggerでサポートされている約15のタグ(公式ドキュメントで確認できます)を用いています。固有表現抽出に関してその正確さは80%以上です。
デバッグ手法
話をまとめる前に、デバッグのヒントについて話そうと思います。
NSLinguisticTagOtherWordタグがついてしまった時
NLP APIを使っているといくつかの問題にぶつかると思います。NLP APIを実行した場合、品詞タグ付けや固有表現抽出のアウトプットが全てNSLinguisticTagOtherWordになったとします。つまり人名や地名などのタグが付与できないという状況です。これはデバイスにモデルがダウンロードできていない状況であることが考えられます。これは何を意味するかというと、品詞タグ付けや固有表現抽出モデルは無線を通じてダウンロードされます。これは機械学習モデルをより多くのデータを用いて改善するためです。何度もモデルを訓練させて改良し、正確さを向上させます。できるだけ速く最新版を無線でアップデートしようとします。最初から全てのモデルがディスク上に完全にインストールされているわけではなく、OTA(※無線ネットワークを利用したデータの受信・同期などのこと)で届けられます。
このモデルはどのようにインストールされるのでしょうか。iOSの場合は特定のキーボードを入手するとすぐにインストールされます。フランス語のキーボードをインストールすると全てのフランス語のセットがデバイスにインストールされます。他の言語についても同様です。
言語を明示して設定する
2つめのヒントはもし扱う言語がわかっているなら明示的に言語を設定してみてください。Helloという文字列を例にとって説明します。Helloという文字列を言語識別APIに渡すとどの言語として識別されると思いますか?Helloという単語は多くの異なる言語で使われています。NLP APIは自動で多くの情報を提供しますが、同時にあなたのアプリでどのように活用できるかということを考えなくてはなりません。もし言語が明確にわかっているなら言語を設定することができます。もし文字列が長いなら、NLP APIを使って言語を特定してください。アプリによってNLP APIをどのように使用するか選びましょう。
まとめ
NLP APIについて説明してきました。このAPIはNSLinguisticTaggerを通して使うことができます。
今回のリリースでは新しい単位がサポートされることを紹介しました。つまり文、段落、文書レベルで取得することができるということです。これらの種類は、このAPIにさらなる機能を追加するときに重要になってきます。それ以外にもコードが大幅に改善されたので、タグ付けが大幅に速くなりましたし、正確さの向上、より多くの言語への対応も行われました。この話の詳細はセッション208(※つまりこのセッション)を参考にしてください。Winnow, Whiskのサンプルプロジェクトもあります。他にも関連セッションがあります。昨日CoreML紹介のセッションに参加した人のために、CoreMLのより深部に迫ったセッションがあります。行列計算や低レベルのものを扱うAccelerateやSparse Solversのセッションもあります。
- What's New in Cocoa Touch
- Introducing Core ML
- Vision Framework: Building on Core ML
- Core ML in depth
- Accelerate and Sparse Solvers
NLPは非常に面白い分野です。私たちはこの分野に多くの時間と努力を費やしています。あなたにとって、ユーザにとって良い変化を生むこのAPIについて理解したいと思っています。私たちはあなた方の声が聞きたいです。テキスト分類などについてあなたが直面した問題をフィードバックしてほしいです。私達が開発する機能と公開できる機能の良い中間点を見つけることができたら良いと思っています。だからラボに来てあなたが抱えている問題や興味のあることについて教えてほしいし、聞きたいこと、やってほしいことを話してほしいです。私たちはその全てに耳を傾けます。