本記事は下記の続きです。
GPT 1.0
2018年6月、OpenAIは自然言語処理タスクに対する新規のAIモデルとしてGPT(Generative Pre-Training)に関する論文(Improving Language Understanding by Generative Pre-Training)を発表した。TransformerのSelf-Attention機構により単語間の文脈的関係をキャプチャでき、RNN系のAIモデルに比べて文脈的に正確なテキスト生成が可能になった1。
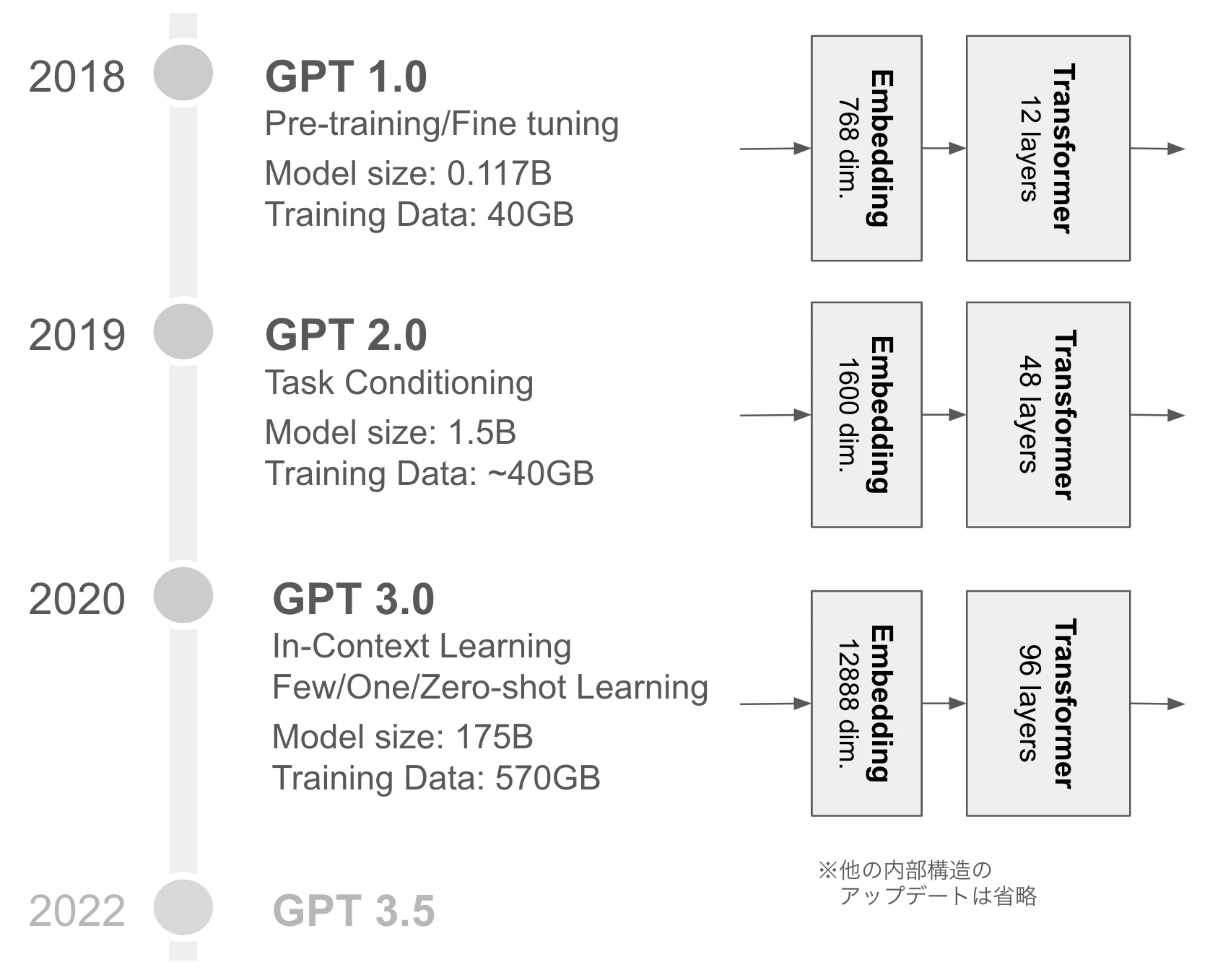
GPT1.0以前は、ほとんどのモデルは教師あり学習が行われており、特定のタスクごと(感情分類、質問回答、テキスト含意など)にラベル付きデータが必要だった(ラベルをつける作業が人力で行われているため大量データの用意にコストがかかる)。GPT1.0では、大量のラベルなしテキストデータを用いて教師なし学習が行われ(事前学習)、タスク固有の自然言語処理アプリケーション向けに微調整する(ファインチューニング)という形式をとり、ラベル付きデータを最小限に抑えてさまざまな自然言語処理タスクを一般化できることを実証したことで、チャットボットやコンテンツ生成の可能性を示した。扱える文章の長さや生成されるテキストの精度が実用レベルまでには至らなかったが、GLUE (General Language Understanding Evaluation、一般言語理解評価) ベンチマークの12タスクのうち9つで他の教師ありモデルを上回るなど、大きなインパクトを残した。GPTはこの後もアップデートを続けるため、この時点でのバージョンはGPT1.0と呼ばれる。
事前学習(大量データによる教師なし学習)、ファインチューニング(タスクごとの微調整)による言語処理AIモデルの高度化

GPT 2.0
財政上の課題に対処するため、OpenAIは2019年3月に営利法人OpenAI LPを設立した2。投資家の利益に上限を設けて超過分を非営利団体のOpenAIに譲渡すること、Sam Altman氏がOpenAI LPの株式を取得しないことなど異例な事態がいくつかあり物議を醸したが3、これにより2019年7月にMicrosoftから10億ドルを調達し4、AIモデルを追求するために必要な資本を調達できるようにした。
またOpenAIは強化学習に関する研究も中止していたわけではなく、2019年10月にOpenAI FiveとADR(Automatic Domain Randomization)と呼ばれる徐々に難易度の高いシミュレーション環境を作り出す技術を組み合わせて、ロボットが片手でルービックキューブを解くタスクを達成した(ロボットハンドでルービックキューブを解くタスクには2017年から取り組まれていた)56。

そんな中、2019年11月、GPT2.0がリリースされた7。GPT2.0では、モデルへの入力にどんなタスクが期待されているか(例:翻訳、要約など)を含ませることで、コンピューティングコストのかかるファインチューニングなしで様々なタスクへの対応を目指しており8、GPT1.0のモデル構造をほぼ変えずに、パラメータ数(モデルサイズ)と学習のためのデータセット量を大幅に増やして精度を向上させた9。これにより、より大規模なモデルサイズ・データセット量が精度を向上させることを示され、さらなる大規模化が期待された10。
GPT2.0はその高いパフォーマンスを有する一方で、ディープフェイクや回答の倫理性の問題など、規制されていない展開に伴う潜在的なリスクが懸念され、当初OpenAIはモデルサイズ124Mの小規模バージョンのみの公開にとどめ、人間によるフィルタリングされたWebページのみ利用する等のデータキュレーションや、過激派グループによる利用リスク評価を行うなど、フィルタリング・モデレーションシステムの実装を経て段階的に公開をしていく運びとなった11。
プロンプトの工夫(Task Conditioning、Zero shot learning等)によるファインチューニングなしでのタスク対応
GPT 3.0
OpenAIは2020年1月に、TransformerベースのAIモデルのパフォーマンスは、モデルサイズ・学習データ量・コンピューティングリソースを変数としたべき乗法則に従う(スケーリング則)といった論文を発表し(Scaling Laws for Neural Language Models)、これらを増加することでのモデルの高度化が注目されることになる。また同月、Image GPTと呼ばれる、GPT2.0の構造に画像のピクセルデータをシーケンス化して利用することで画像生成を行うモデルを発表し、画像生成AIの可能性を示した1213。
そして2020年5月、GPT3.0が発表された(Language Models are Few-Shot Learners)。GPT3.0は、計算量削減のためSparse Transformerが用いられるなどの変更はあったが、基本的な構造はGPT2.0と変わらず、GPT2.0よりもさらに大規模なモデルサイズ(175B)・データセットが用いて学習が行われた14。さまざまなカテゴリの数十の自然言語処理ベンチマークで評価され、多くの場合、パフォーマンスは最先端に近いかそれ以上を叩き出した15。そして、GPT3.0では、GPT1.0の様なファインチューニングなしでかつGPT2.0よりも入力プロンプト自体に埋め込まれた指示や例に基づいてタスクを実行するようにするIn-Context Learningを導入し、学習フェーズでは未知だったタスクへの対応も目指した8。それもあり、LLMに対するFew-shot/One-shot/Zero-shot learningのコンセプトがさらに注目を浴びることになった。
- Few-shot Learning:いくつかのタスク例をLLMに提供して応答を導く
- One-shot Learning:1つのタスク例をLLMに提供して応答を導く
- Zero-shot Learning:例を使用せずにタスクの指示のみで応答させる
プロンプトの工夫(Few-shot/One-shot/Zero-shot learning等)によるファインチューニングなしでの未学習タスク対応の拡大
翌月の6月に、研究用にGPT3.0にアクセスできるOpenAI GPT-3 APIを用意し、出力の精度は開発者から高い評価を受けている1617。ただし、長文の生成や一般常識に欠ける部分や15、フェイクニュースへの危惧などが問題として挙げられた18。そして2021年11月には、十分な安全対策が実装され、APIへのアクセスが制限されなくなると発表され19、さらにアプリケーション化への期待が高まったとみられる。
一方、2020年10月に、Roboticsチームの解散が発表された。当初OpenAIでは、自己生成データと強化学習を使用して大幅な進歩を遂げることができると考えていたが、予想以上に困難であることが判明したため、AGIの実現にはデータ不足としてこの決定がなされた20。
次の記事はこちら
-
The Evolution of the GPT Series: A Deep Dive into Technical Insights and Performance Metrics From GPT-1 to GPT-4o ↩
-
Microsoft invests in and partners with OpenAI to support us building beneficial AGI ↩
-
Release Strategies and the Social Impacts of Language Models ↩
-
OpenAI Announces GPT-3 AI Language Model with 175 Billion Parameters ↩ ↩2