近況
飲んで帰ってきて、気づいたらこんなの書いていました。
ちょっと具体性に乏しいので、もう少し後でパッチを書きます。
(でも、明日は会社の歓迎会で飲んでくるのだ)
前回のあらましと今回見るところ
前回、仮想アドレスと物理アドレスの紐付けをする処理とそのデータ構造のページテーブルを見ました。
そして、今回はユーザ空間へのアドレス空間マップを行うmmap()を見ることで、仮想アドレス空間の扱いの一端をかいま見てみましょう。
mmapの実装
mmapは以下の実装である。
(厳密に言うと、システムコールのベクタではないので「システムコールの開始地点」ではない)
asmlinkage long sys32_mmap(struct mmap_arg_struct32 __user *arg)
{
struct mmap_arg_struct32 a;
if (copy_from_user(&a, arg, sizeof(a)))
return -EFAULT;
if (a.offset & ~PAGE_MASK)
return -EINVAL;
return sys_mmap_pgoff(a.addr, a.len, a.prot, a.flags, a.fd,
a.offset>>PAGE_SHIFT);
}
実際の処理はsys_mmap_pgoff()のようなので、これを見る。
SYSCALL_DEFINE6(mmap_pgoff, unsigned long, addr, unsigned long, len,
unsigned long, prot, unsigned long, flags,
unsigned long, fd, unsigned long, pgoff)
{
struct file *file = NULL;
unsigned long retval = -EBADF;
if (!(flags & MAP_ANONYMOUS)) {
/*
* ここは要するに、file構造体を取得したりとバッキングストア
* となるファイルを扱うためのデータを準備するのが主
* よって、略
*/
} else if (flags & MAP_HUGETLB) {
/* 本当は面白そうなところだけれど、概要をつかむことを優先するため略 */
}
flags &= ~(MAP_EXECUTABLE | MAP_DENYWRITE);
retval = vm_mmap_pgoff(file, addr, len, prot, flags, pgoff);
out_fput:
if (file)
fput(file);
out:
return retval;
}
見たとおり、vm_mmap_pgoff()を呼んでいる。
vm_mmap_pgoff()は事実上、do_mmap_pgoff()を呼ぶだけなのでそちらを見る。
unsigned long do_mmap_pgoff(struct file *file, unsigned long addr,
unsigned long len, unsigned long prot,
unsigned long flags, unsigned long pgoff,
unsigned long *populate)
{
struct mm_struct * mm = current->mm;
vm_flags_t vm_flags;
/* 略 */
/*
* Does the application expect PROT_READ to imply PROT_EXEC?
*
* (the exception is when the underlying filesystem is noexec
* mounted, in which case we dont add PROT_EXEC.)
*/
if ((prot & PROT_READ) && (current->personality & READ_IMPLIES_EXEC))
if (!(file && (file->f_path.mnt->mnt_flags & MNT_NOEXEC)))
prot |= PROT_EXEC;
/* 略 */
うむむ。この実装は想像していなかった。なんじゃ、このREAD_IMPLIES_EXECというのは?
気になるが、先に進む。(疑問点)
/* パラメータチェックなど。略。*/
/* Obtain the address to map to. we verify (or select) it and ensure
* that it represents a valid section of the address space.
*/
addr = get_unmapped_area(file, addr, len, pgoff, flags);
if (addr & ~PAGE_MASK)
return addr;
get_unmapped_area()では、マップ可能なアドレス空間の先頭仮想アドレスが返ってくるのだろうと想定する。おそらくは仮想アドレス空間を検索して空き領域を探すのだろうと思われるのでget_unmapped_area()についてはこれ以上は調査せず、先に進む。
/* 略 */
/*
* バッキングストアが指定されている場合、(mmap()での引数fdが
* 何かファイルを指定している場合
*/
if (file) {
struct inode *inode = file_inode(file);
/* 基本的にやることはパラメータ調整。なので略 */
/* Annonymous memoryをマップする場合 */
} else {
/* 基本的にやることはパラメータ調整。なので略 */
}
/* mmapにこんなオプションがあったとは...気になるけど先に進む */
/*
* Set 'VM_NORESERVE' if we should not account for the
* memory use of this mapping.
*/
if (flags & MAP_NORESERVE) {
/* We honor MAP_NORESERVE if allowed to overcommit */
if (sysctl_overcommit_memory != OVERCOMMIT_NEVER)
vm_flags |= VM_NORESERVE;
/* hugetlb applies strict overcommit unless MAP_NORESERVE */
if (file && is_file_hugepages(file))
vm_flags |= VM_NORESERVE;
}
/*
* ここがメインの処理っぽい。空いている仮想アドレス空間はさきに押さえている
* ので、あとはマップの属性を設定するのが主な作業になるだろう
*/
addr = mmap_region(file, addr, len, vm_flags, pgoff);
if (!IS_ERR_VALUE(addr) &&
((vm_flags & VM_LOCKED) ||
(flags & (MAP_POPULATE | MAP_NONBLOCK)) == MAP_POPULATE))
*populate = len;
return addr;
}
mmap_region()を見る
さて、いよいよmmap_region()を見ることにします。
unsigned long mmap_region(struct file *file, unsigned long addr,
unsigned long len, vm_flags_t vm_flags, unsigned long pgoff)
{
/* 略 */
/* プロセスのメモリ空間をこれ以上増やせるかチェック */
/* Check against address space limit. */
if (!may_expand_vm(mm, len >> PAGE_SHIFT)) {
/* 略 */
}
次が少しイメージしにくいかもしれません。
/* Clear old maps */
error = -ENOMEM;
munmap_back:
/* 今回マップしようとしているアドレス空間の一つ前のstruct vmaを取得 */
if (find_vma_links(mm, addr, addr + len, &prev, &rb_link, &rb_parent)) {
if (do_munmap(mm, addr, len))
return -ENOMEM;
goto munmap_back;
}
find_vma_linksは追加でコメントを記載した通りの働きで、第四引数のprevに格納される値は以下の図の通りとなります。
なお、addrには前述したmmap_region()で、挿入する見込みの仮想アドレス空間の先頭仮想アドレスが格納されています。
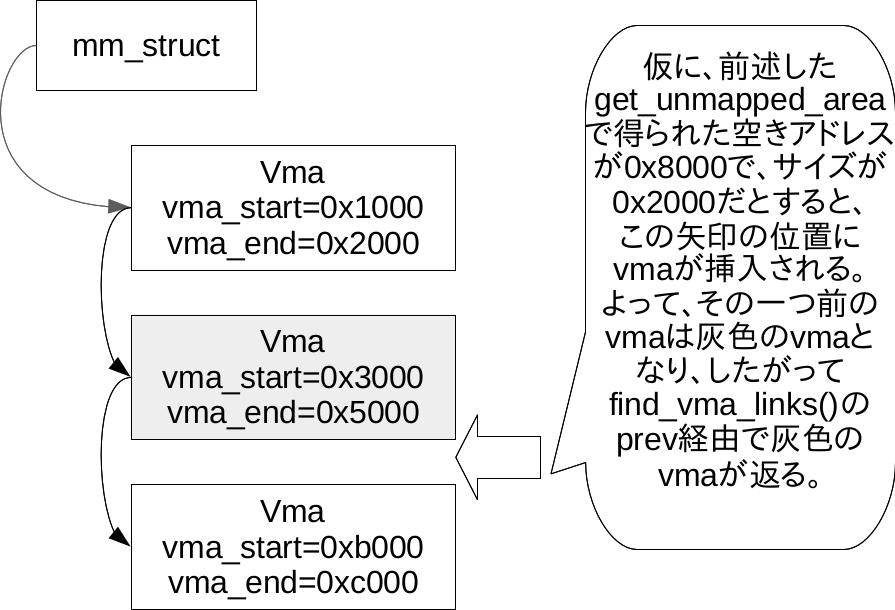
先に進みましょう。
次に、アドレス空間内に領域を割り当てるわけですが、すでにあるstruct vmaの範囲拡張で問題ないか調べます。
/* 略 */
/* struct vm_area_structの範囲を拡張するだけで済ませられないか? */
/*
* Can we just expand an old mapping?
*/
vma = vma_merge(mm, prev, addr, addr + len, vm_flags, NULL, file, pgoff, NULL);
/* 拡張で済ませられたら、終わり */
if (vma)
goto out;
これもイメージしにくいと思うので説明します。
要するに、「vmaを挿入して新たなアドレス空間をマップした結果、隣り合ったvmaが併合できるケースがあるか判定し、併合できるのなら併合して、併合後のvmaを返す」という処理です。
本来であれば、以下の図のグレーアウトした箇所のようにvmaが2つになるはずですが、連続している同属性の領域に2つのvmaを使うのは無駄なのでこのような処理があります。
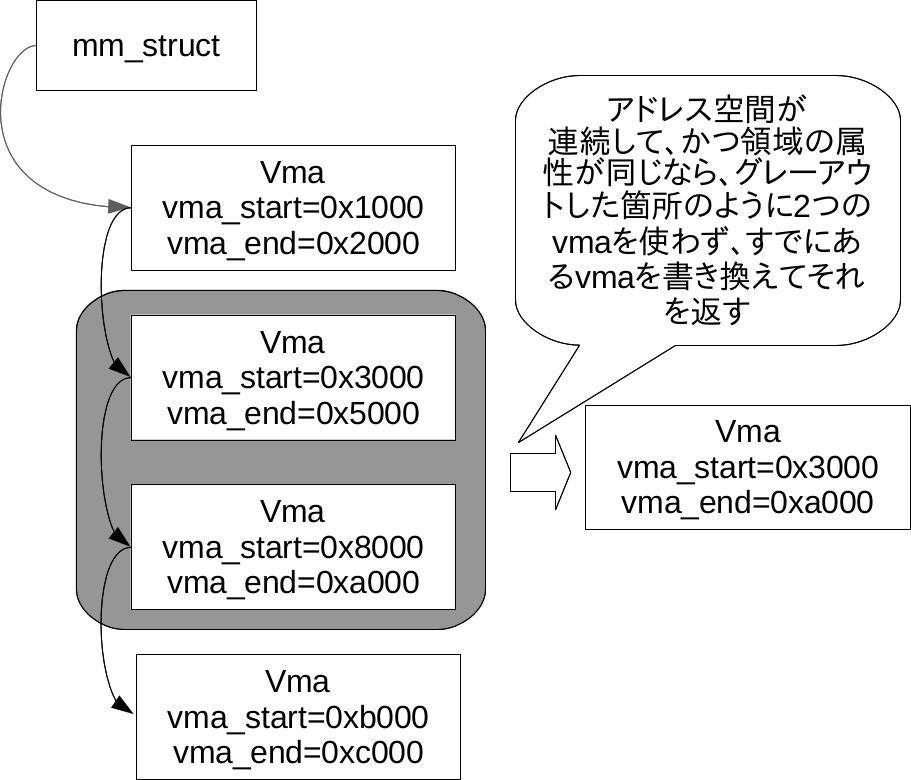
併合できなかった場合は、新たにvmaを割り当てて、それをvmaのリスト中に挿入します。
/*
* Determine the object being mapped and call the appropriate
* specific mapper. the address has already been validated, but
* not unmapped, but the maps are removed from the list.
*/
vma = kmem_cache_zalloc(vm_area_cachep, GFP_KERNEL);
if (!vma) {
error = -ENOMEM;
goto unacct_error;
}
/* 新しくstruct vmaを作って、初期化する。 */
vma->vm_mm = mm;
vma->vm_start = addr;
vma->vm_end = addr + len;
vma->vm_flags = vm_flags;
vma->vm_page_prot = vm_get_page_prot(vm_flags);
vma->vm_pgoff = pgoff;
INIT_LIST_HEAD(&vma->anon_vma_chain);
そして、次にバッキングストアを仕込みます。
/* で、ファイル、すなわちバッキングストアがあるケース */
if (file) {
if (vm_flags & VM_DENYWRITE) {
error = deny_write_access(file);
if (error)
goto free_vma;
}
vma->vm_file = get_file(file);
/*
* 該当ファイル(デバイスファイルなど)で独自のmmapルーチンがあれば、
* それを実行する
*/
error = file->f_op->mmap(file, vma);
if (error)
goto unmap_and_free_vma;
/* Can addr have changed??
*
* Answer: Yes, several device drivers can do it in their
* f_op->mmap method. -DaveM
* Bug: If addr is changed, prev, rb_link, rb_parent should
* be updated for vma_link()
*/
WARN_ON_ONCE(addr != vma->vm_start);
addr = vma->vm_start;
vm_flags = vma->vm_flags;
次にAnnnymousだが少し特殊なケース。他プロセスと内容を共有するケースです。
このケースだと、書き込み時に書き込んだ内容が他のプロセスから見えないとならないのでCOW(Copy On Write)はしません。
/*
* Annonymous属性だが、他のプロセスと変更内容を共有したいケース
* この場合はCOWの対象外となる
*/
} else if (vm_flags & VM_SHARED) {
error = shmem_zero_setup(vma);
if (error)
goto free_vma;
}
shmem_zero_setup()は以下の実装です。
int shmem_zero_setup(struct vm_area_struct *vma)
{
struct file *file;
loff_t size = vma->vm_end - vma->vm_start;
file = shmem_file_setup("dev/zero", size, vma->vm_flags);
if (IS_ERR(file))
return PTR_ERR(file);
if (vma->vm_file)
fput(vma->vm_file);
vma->vm_file = file;
vma->vm_ops = &shmem_vm_ops;
return 0;
}
ちょっと驚きました。/dev/zeroをバッキングストアにするのですね。初めてのアクセス時にはゼロパティングされたページを得られるのでしょう。
そして、ページャ(vm_ops)はその名前から共有メモリ向けのものになります。
ページャとは、バッキングストアに対する操作群(ざっくり言うと関数ポインタの集まり)を格納した構造体です。
いよいよ、プロセスのアドレス空間にstruct vmaを挿入してアドレス空間を割り当てます。
/* 略 */
/* 最終的に、struct vmaをプロセスのアドレス空間に押しこむ! */
vma_link(mm, vma, prev, rb_link, rb_parent);
/* Once vma denies write, undo our temporary denial count */
if (vm_flags & VM_DENYWRITE)
allow_write_access(file);
file = vma->vm_file;
out:
/* 以後は統計情報などをとる処理で本質的な箇所でないので略 */
return addr;
/* 以後はエラー時の処理。gotoで飛んでくる */
/* 略 */
}
ここまで見たとおり、アドレス空間のマップと同時に物理ページを割り当てている様子はありません。
ユーザ空間であればそれはごく普通のことです。それは、デマンドページングというやつでしょう。
この場合、実際に物理メモリを割り当てるのは、ページフォルトハンドラとなるはずです。
次回の予定
ということで、次回はページフォルトに手を出してみたいと思います。
ページフォルトハンドラは例外ハンドラの一つですので、普通はCPUアーキテクチャ依存のコードから始まることになります。アーキテクチャはx86で行きます。(ARMとかMIPSとかは割と一般的ですが、x86ほどではないので・・・)