概要
Google Cloud Data Catalog で何ができるのか、Cloud Next'19 のセッションを視聴し、少し触ってみてわかったことをまとめる。
Google Cloud Data Catalog とは
フルマネージドでスケーラブルなメタデータ管理サービス。
機能
- UI や API でメタデータを検索・管理できる
- 対象のデータソースは BigQuery / Pub/Sub / GCS
- テクニカル メタデータ (後述) を自動で収集してくれる
- データソース (BigQuery のみ ?1) が作成されてから 3 秒で収集完了
- UI や API で ビジネス メタデータ (後述) を登録できる
- メタデータへのアクセス制御ができる
- Cloud DLP2 を使えば PII3 を自動検出してタグ付けできる
メタデータ
メタデータとは、以下の 2 つのことを指す。
いずれのメタデータも内部的には Spanner に保存される。
テクニカル メタデータ
すでに GCP サービスに存在しているメタデータ。
自動で収集される。
例
- テーブルやカラムの名前、説明、型
- 作成日、最終更新日
ビジネス メタデータ
ユーザにとって有益なビジネス上の背景情報を持つ追加メタデータ。
ユーザが タグ として登録する。 (PII かどうかの判定は、DLP2 で自動的に付与することもできる。)
例
- テーブルが PII3 を含むか
- データのオーナーは誰か
- いつまで保持されるか (いつ削除されるか)
- ビジネスロジック
- データのクオリティ
インターフェース
GUI と API が用意されている。
GUI の節で各機能の詳細を説明する。
GUI
トップページ (?)
主に検索とビジネス メタデータを管理するメニューが並んでいる。
特に検索のためのサジェストが多く並んでいる。
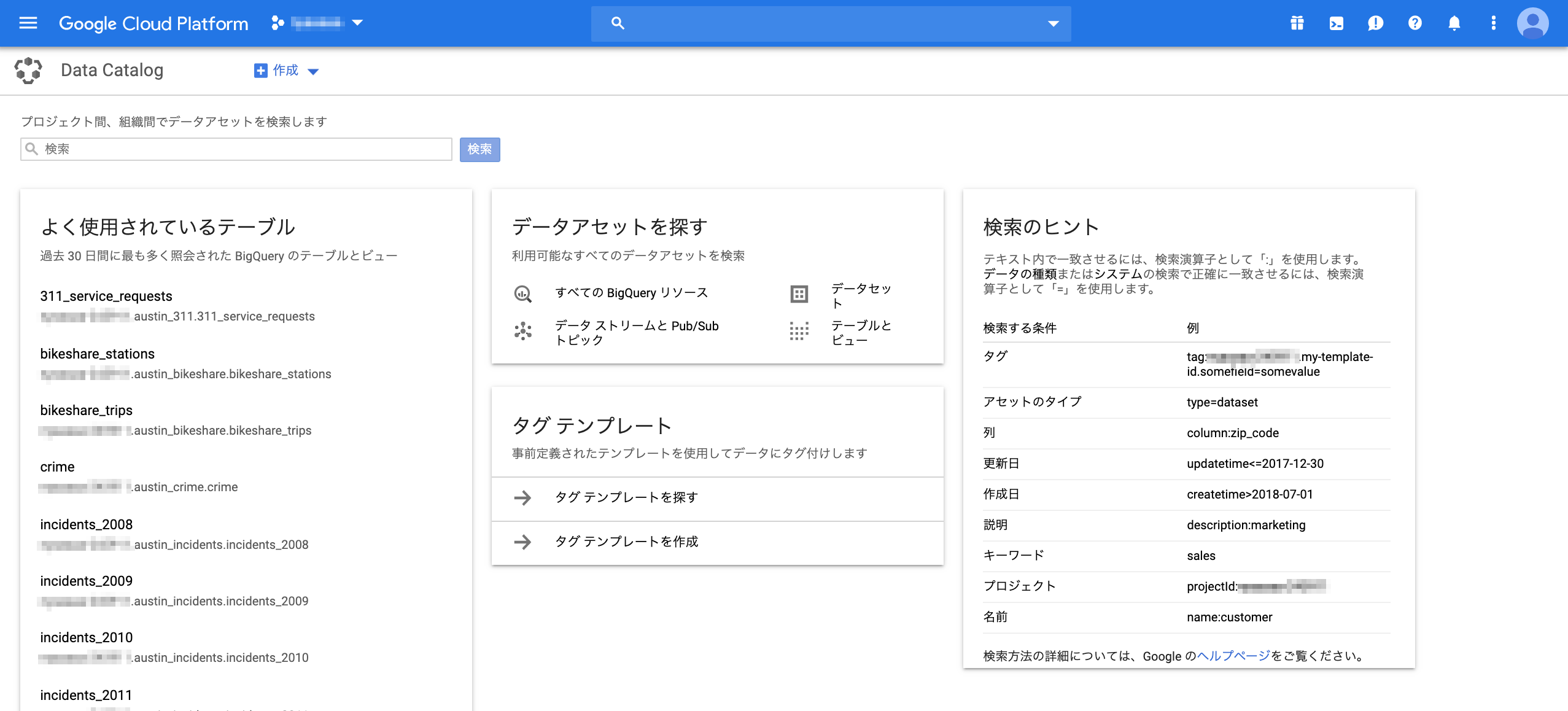
検索結果
最終更新日時やカラム名での検索結果には、データセットやテーブル、タグが一覧で表示される。
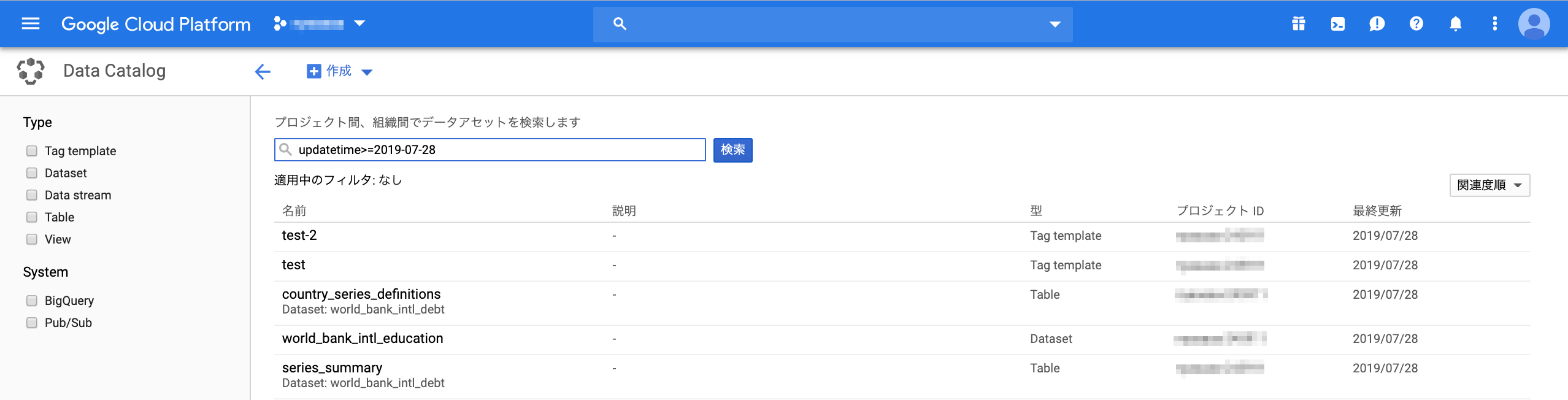
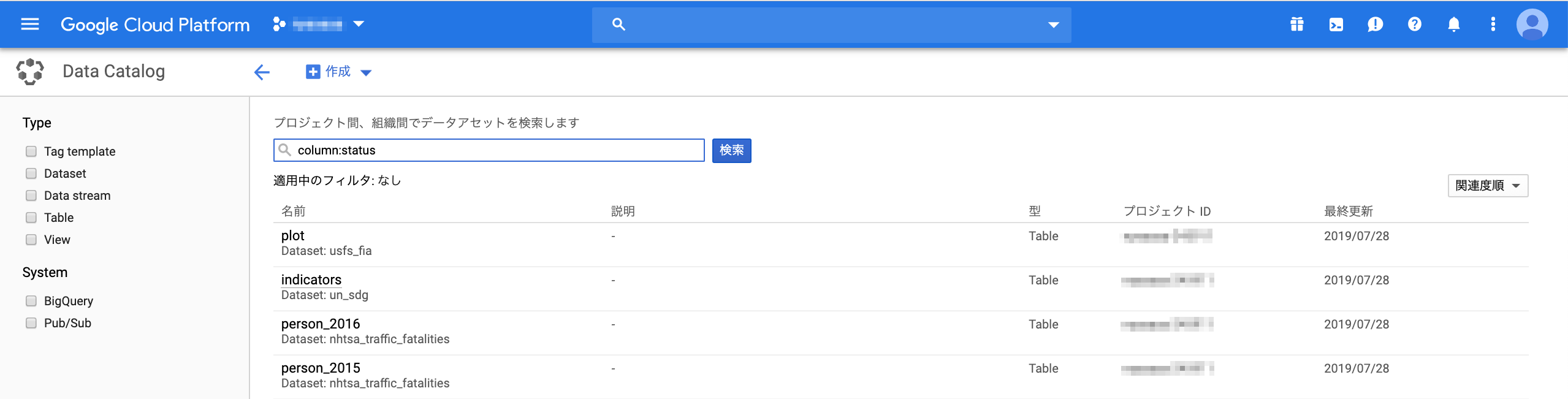
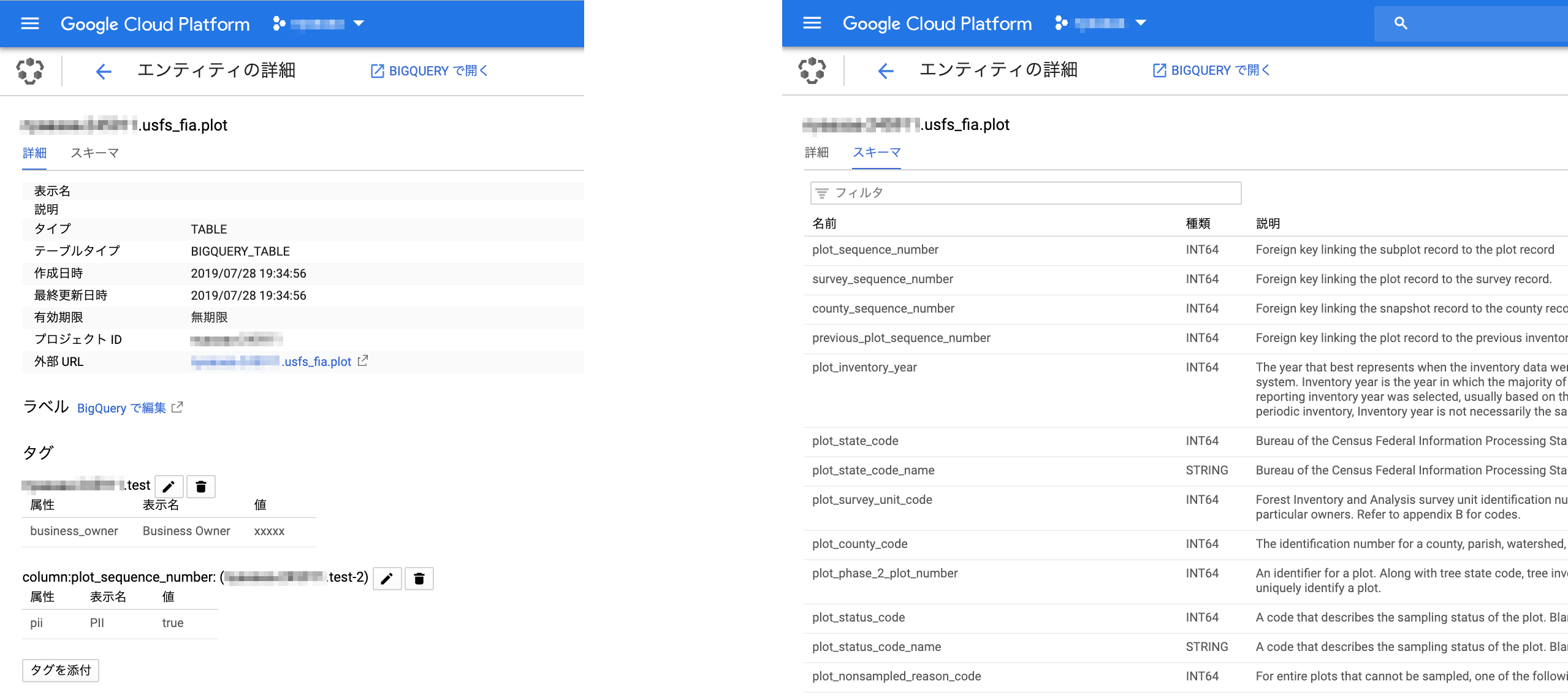
エンティティの詳細
詳細タブ (左) には、ID やタイプ、最終更新日時などのテクニカル メタデータと、タグとして付与したビジネス メタデータが表示される。
タグはデータセットやテーブル、カラムなど様々な単位に付与できる。
スキーマタブ (右) では、テーブルのカラム一覧が表示される。
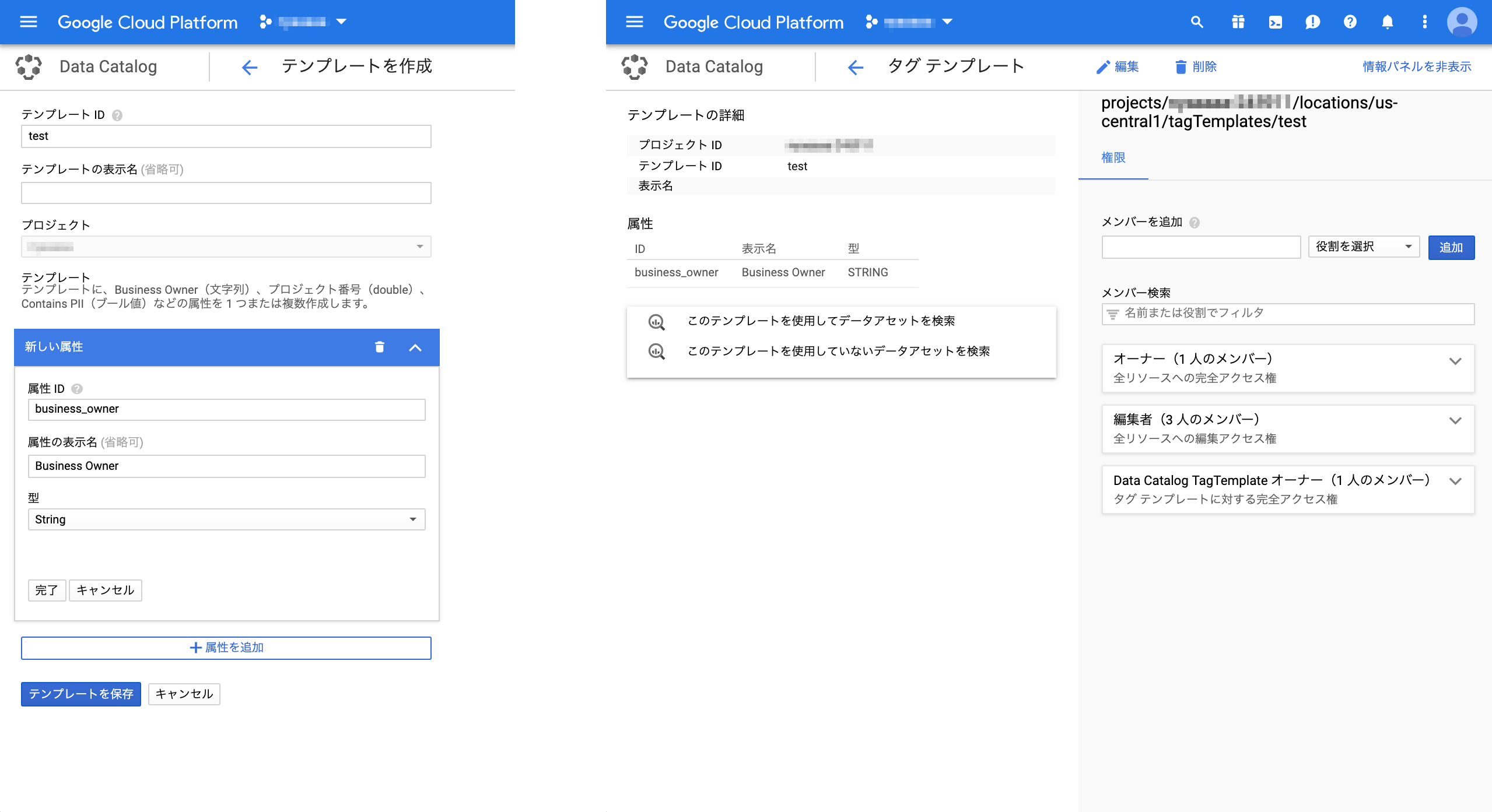
タグテンプレート
タグは予め登録しておいたタグテンプレートを用いて登録する。
タグテンプレートの登録と表示は以下のような画面。
タグへのアクセス権限も表示されており、またここでも検索のサジェストが表示される。
API
GUI と同じことができる。現時点では以下を利用可能。
- クライアントライブラリ (Python / Java / Node.js)
- REST
- RPC
- Cloud SDK (gcloud コマンド)
gcloud コマンドで検索とデータセットの参照をしたサンプル。
他にもエンティティやタグ、タグテンプレートの参照・変更が可能。
$ gcloud beta data-catalog search 'test' --include-project-ids=xxxxx
---
linkedResource: //datacatalog.googleapis.com/projects/xxxxx/locations/us-central1/tagTemplates/test
relativeResourceName: projects/xxxxx/locations/us-central1/tagTemplates/test
searchResultSubtype: tag_template
searchResultType: TAG_TEMPLATE
---
linkedResource: //bigquery.googleapis.com/projects/xxxxx/datasets/test
relativeResourceName: projects/xxxxx/locations/US/entryGroups/@bigquery/entries/yyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy
searchResultSubtype: entry.dataset
searchResultType: ENTRY
---
$ gcloud beta data-catalog entries lookup //bigquery.googleapis.com/projects/xxxxx/datasets/test
linkedResource: //bigquery.googleapis.com/projects/xxxxx/datasets/test
name: projects/xxxxx/locations/US/entryGroups/@bigquery/entries/yyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy
sourceSystemTimestamps:
createTime: '2019-07-25T13:46:02.440Z'
updateTime: '2019-07-25T13:46:02.440Z'
補足 - API 利用時のアカウント
gcloud コマンドでは Google アカウント (自分のメールアドレスで認証) でもできた操作が、クライアントライブラリではサービスアカウントを使用しないとできないようだった。
具体的には、 Google アカウントの credentials を利用した場合、 gcloud コマンドでは検索の実行 (上記サンプルの 1 つ目) もデータセットの参照 (2 つ目) もできたが、クライアントライブラリではデータセットの参照ができず、以下のようなエラーが発生した。
from google.cloud import datacatalog_v1beta1
client = datacatalog_v1beta1.DataCatalogClient()
client.get_entry("//bigquery.googleapis.com/projects/nyaaaaa-245911/datasets/test")
google.api_core.exceptions.PermissionDenied: 403 Your application has authenticated using end user credentials from the Google Cloud SDK or Google Cloud Shell which are not supported by the datacatalog.googleapis.com. We recommend that most server applications use service accounts instead. For more information about service accounts and how to use them in your application, see https://cloud.google.com/docs/authentication/.
バージョンは以下。
- Google Cloud SDK 255.0.0 (gcloud コマンド)
- beta 2019.05.17 (gcloud コマンドの component)
- google-cloud-datacatalog 0.2.0 (Python ライブラリ)
アクセス制御
データソース (BigQuery / PubSub / GCS) で read 権限が設定されていれば詳細まで表示できるが、 Data Catalog で read 権限しかない場合は検索結果には表示されるが、詳細の表示はできない。
| データソースで read 権限が設定されている | Data Catalog で read 権限が設定されている | 検索結果に表示される | 詳細を表示できる |
|---|---|---|---|
| o | o | o | o |
| o | x | o | o |
| x | o | o | x |
| x | x | x | x |
タグ (タグテンプレート) にも権限を設定でき、データソースへのアクセス権限はあってもタグは表示されないようにすることもできそう。
料金体系
ビジネス メタデータの量と API のコール数によって課金される。
-
ビジネス メタデータの量
- 1 MB まで無料
- 超過分は 1 GB あたり月額 $100
- Data Catalog によって取り込まれたオンプレミスに保存されている (テクニカル) メタデータがある場合はそのデータ量も含まれる
-
Catalog API Calls pricing
- 1 か月あたり 100 万回まで無料
- 超過分は 10 万回あたり月額 $10
補足 - AWS Glue Data Catalog との比較
AWS にも Glue Data Catalog というものがあるようだが、これはあくまでも ETL4 のためのサービスであり、 Google Cloud Data Catalog とは別物のよう。
Glue Data Catalog ではビジネス メタデータは管理できないし、テクニカル メタデータの自動収集もしてくれない。 (自分で crawler をつくる必要がある)
まとめと感想
テクニカル メタデータは自動で収集され、プロジェクトやデータソースのタイプをまたいで柔軟に検索できる。
自動収集はもちろんだが、各データソースの API で同じ検索をするには、プロジェクト、データセット、テーブルとそれぞれ検索する手間を省けるので、横断して検索できるインターフェースが便利。
ビジネス メタデータも (ドキュメントではなく) タグとして GCP 上で管理できる。
ただし、基本的にユーザが登録する必要がある。
タグの検索も便利だが、データソースが BigQuery 上にある場合は特に、ドキュメントが散らばりがち問題の解決にもつながるかもしれない。
いずれのメタデータも、保存場所やインターフェースを自分で管理しなくてよい。
アクセス制御や料金、 Cloug DLP2 との連携についてはあまり詳しく見れていないので、もっと検証してみたい。