この記事はSnowflake Advent Calendar 2023の1日目です。
今年も来年もみんなでSnowflakeを盛り上げよう!
PyGWalkerとは
PyGWalkerはPandasのDataFrameをTableau風のGUIで探索・可視化できるPythonライブラリです。
オープンソースソフトウェアとして開発されていてソースコードはGitHubで公開されています。
なお、READMEによると、
"Pig Walker"のように発音
…だそうです。
PyGWalkerを起動させると以下のようなWebアプリが立ち上がります!
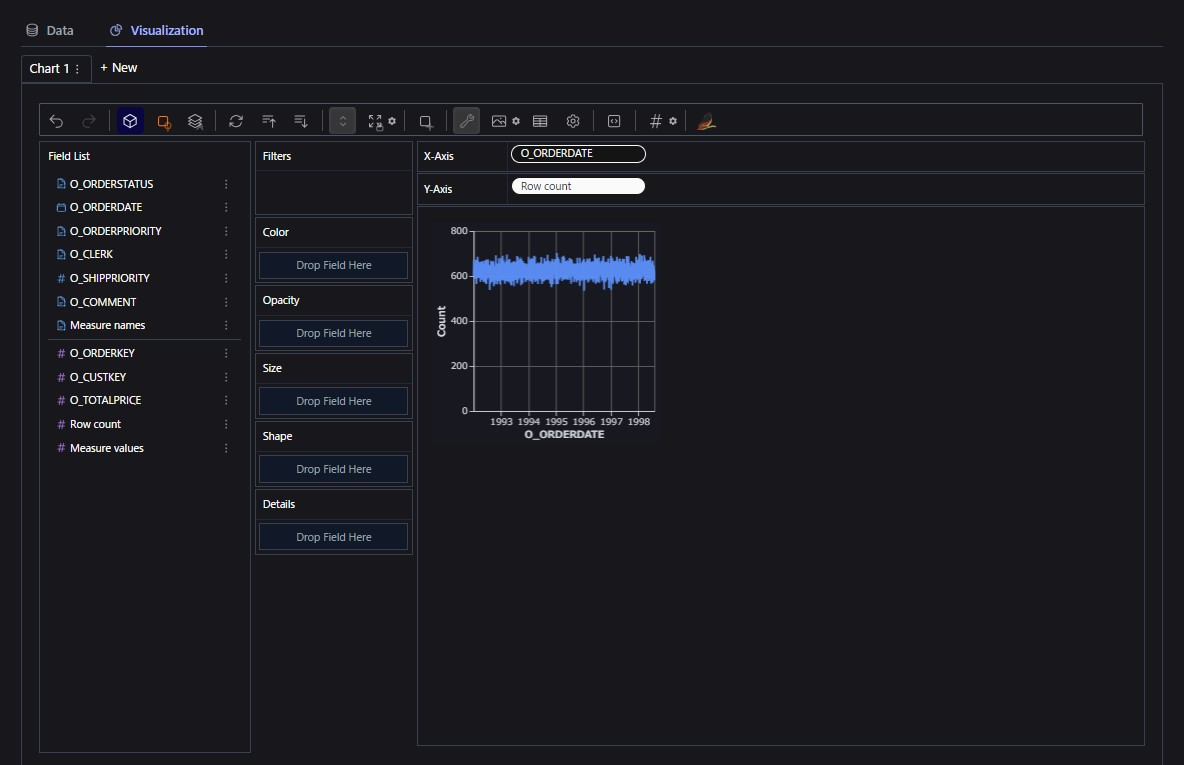
PyGWalkerをSnowflakeと組み合わせると何がいいのか
この記事に記載したプログラムは、ローカルPCなどで動作しているStreamlitからSnowflakeに接続しています。
Streamlit in Snowflakeでは動作しないのでご注意ください。
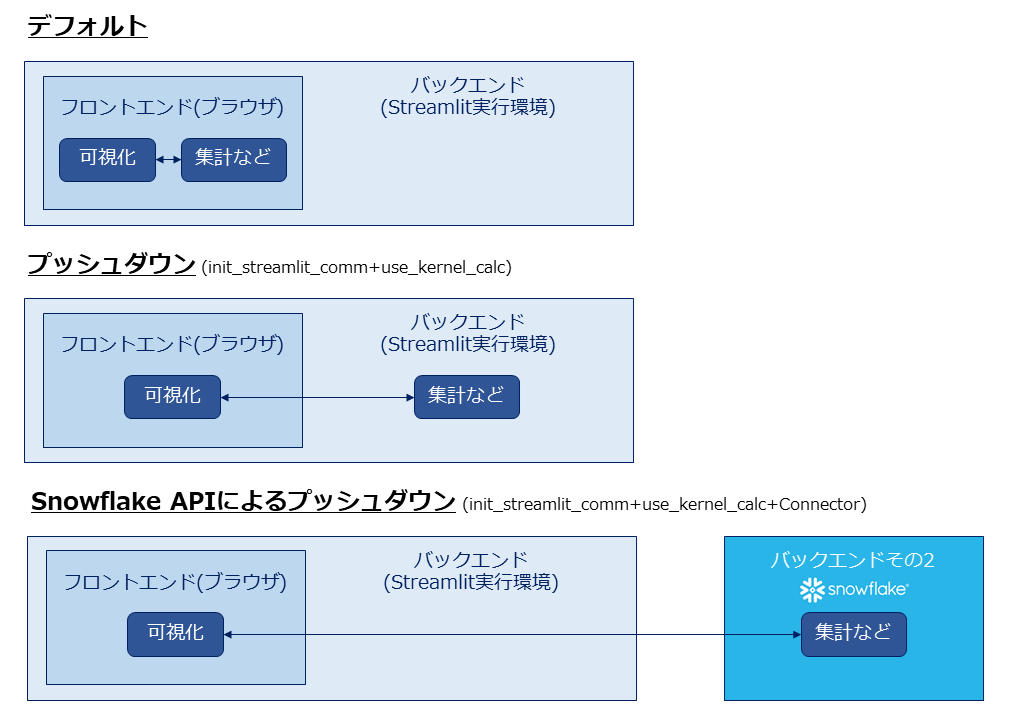
PyGWalkerはデフォルトではすべての処理をフロントエンド(つまりブラウザ上)でやろうとします。そのため、データが大きくなるとブラウザで処理しきれなくなってしまいます。
これを解決するため、PyGWalkerにはバックエンドに集計やフィルターなどの処理を任せる(プッシュダウン)ことができます。
さらに、バックエンドとしてSnowflakeやBigQueryを選択することで、クラウドならではの膨大なリソースを活用することができます!大規模なデータを探索・可視化するのにピッタリですね。
以下がイメージ図です。
環境準備
公式ドキュメントを参考にしながらインストールしていきます。
まずは必要なパッケージをインストールします。
自分はAnaconda環境で構築したため、ところどころにcondaコマンドが混じっています。
conda create -n pygwalker python=3.10
conda activate pygwalker
pip install pygwalker
pip install streamlit
pip install snowflake-sqlalchemy
また、今回の接続方法だとSnowflakeはデフォルトウェアハウスでクエリを実行しようとします。
そのため、あらかじめユーザに対してデフォルトウェアハウスを設定しておきましょう。
参考文献1:ユーザーのデフォルトウェアハウス
参考文献2:Snowflakeのデフォルトウェアハウスは自分のものしか変更できない
ALTER USER PYGUSER SET DEFAULT_WAREHOUSE='COMPUTE_WH';
ソースコードと解説
実際のソースコードは以下のようになります!
import streamlit as st
import streamlit.components.v1 as components
from pygwalker.api.streamlit import init_streamlit_comm, get_streamlit_html
from pygwalker.data_parsers.database_parser import Connector
import pandas as pd
# Streamlitのページ設定。タイトルとレイアウトを設定する
st.set_page_config(
page_title="Snowflake X Streamlit X PyGWalker",
layout="wide"
)
# 1.PyGWalkerの通信機能を初期化
init_streamlit_comm()
# 2.Snowflakeと接続するコネクタを取得
# 各パラメータをsecrets.tomlから取得する
username = st.secrets["snowflake_username"]
password = st.secrets["snowflake_password"]
account_identifier = st.secrets["snowflake_account_identifier"]
database = 'SNOWFLAKE_SAMPLE_DATA'
schema = 'TPCH_SF1'
# Connectorを作成する。SQLAlchemy形式のURLを指定する
url = f'snowflake://{username}:{password}@{account_identifier}/{database}/{schema}'
# このSQLの実行結果がPyGWalkerで探索できるようになる
sql = """
SELECT
*
FROM
SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.ORDERS
"""
conn = Connector(url, sql)
# 3.PyGWalkerのフロントエンドのHTMLを取得する
# `use_kernel_calc=True`を指定するときは、PyGWalkerのHTMLをキャッシュすることが推奨
# そのため、`@st.cache_resource`を使用してキャッシュするが、このときハッシュできない引数 Connector の変数名には`_`をつけている
@st.cache_resource
def get_html(_conn: Connector) -> str:
# Streamlitのコンポーネントに埋め込むHTMLを取得するときはwalk()の代わりにget_streamlit_html()を使用する
# Snowflakeをバックエンドとして使用するときはDataFrameではなくConnectorを渡す
# PyGWalkerの通信機能を使用するため、`use_kernel_calc=True`を指定する
html = get_streamlit_html(_conn, use_kernel_calc=True, debug=False)
return html
# 4.PyGWalkerのフロントエンドのHTMLをStreamlitのコンポーネントに埋め込む
html = get_html(conn)
components.html(html, width=1300, height=1000, scrolling=True)
以下、解説です。
PyGWalkerでバックエンドに集計やフィルターなどの処理を任せるときは、まずinit_streamlit_comm()で通信機能を初期化する必要があります。
init_streamlit_comm()
そしてHTMLを取得するときにuse_kernel_calc=Trueを指定しましょう。
このとき、使用するメモリが肥大化しないように、Streamlitのキャッシュを使うことが推奨とのことです。
@st.cache_resource
def get_html(_conn: Connector) -> str:
html = get_streamlit_html(_conn, use_kernel_calc=True, debug=False)
return html
Streamlitのキャッシュは関数を呼び出すときの引数のハッシュ値を用いて制御されるのですが、ハッシュできない引数があるとエラーが発生します。
このような引数には_で始まる変数名を付けてあげましょう。
参考:st.cache_resource
Any parameter whose name begins with _ will not be hashed.
PyGWalkerでHTMLを取得する関数、walk()あるいはget_streamlit_html()には通常はPandasのDataFrameを渡すのですが、ここにはConnectorを渡すこともできます。
ConnectorにはSQLAlchemy形式のURLと、実行するSQLを指定します。
これにより、DataFrameの代わりに、URLで指定されたデータベースでSQLを実行した結果を探索できます。
url = f'snowflake://{username}:{password}@{account_identifier}/{database}/{schema}'
sql = """
SELECT
*
FROM
SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.ORDERS
"""
conn = Connector(url, sql)
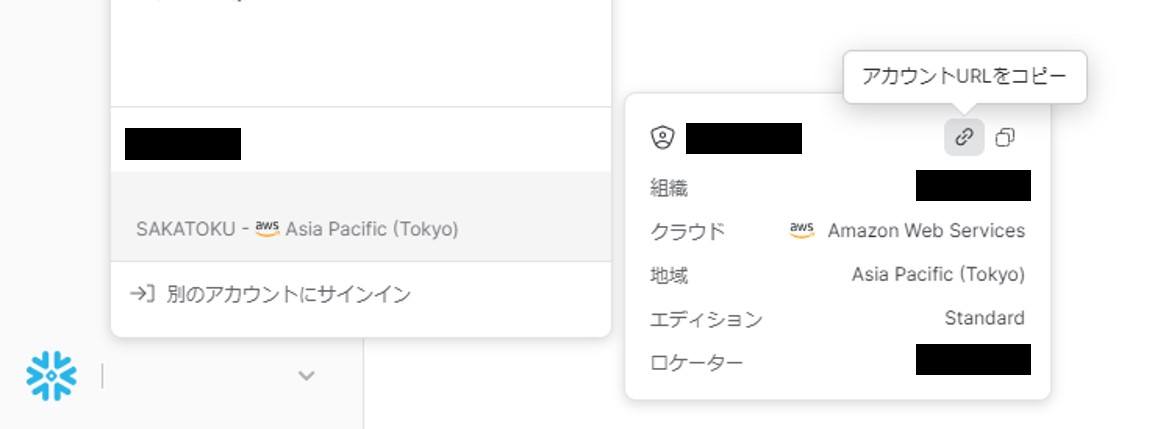
Connectorに設定するURLのホスト名(前述のソースコードでaccount_identifierという変数にした部分)には、SnowflakeのアカウントURLの一部分を設定します。
具体的には、SnowsightでアカウントURLをコピーしたとき、https://xx12345.ap-northeast-1.aws.snowflakecomputing.comのようなURLがクリップボードにコピーされるので、ここからxx12345.ap-northeast-1.awsの部分だけを抜き出したものを設定します。
詳細はSnowflake SQLAlchemyに関するドキュメントを参照してください。
また、st.secretsについては、Streamlitのドキュメントを参照してください。
ユーザ名やパスワードのようなハードコーディングしたくない情報を外部のファイル(secrets.toml)から読み込むための機能です。
実行
ソースコードが完成したら実行しましょう。
今回はStreamlitでホストするので、streamlit runします。
streamlit run sample_with_snowflake.py
デフォルトの設定のままであれば、Webアプリはlocalhost:8501で立ち上がります。
ブラウザでアクセスしてみましょう。
Snowflakeは何をしてくれているのか
前述の通り、PyGWalkerはSnowflakeに集計やフィルターなどの処理を任せることができます。
このときSnowflakeが何をしてくれているのか確認してみましょう。
まず、PyGWalkerで、日付範囲でフィルターして/日単位で行数を集計した結果をグラフ表示してみます。
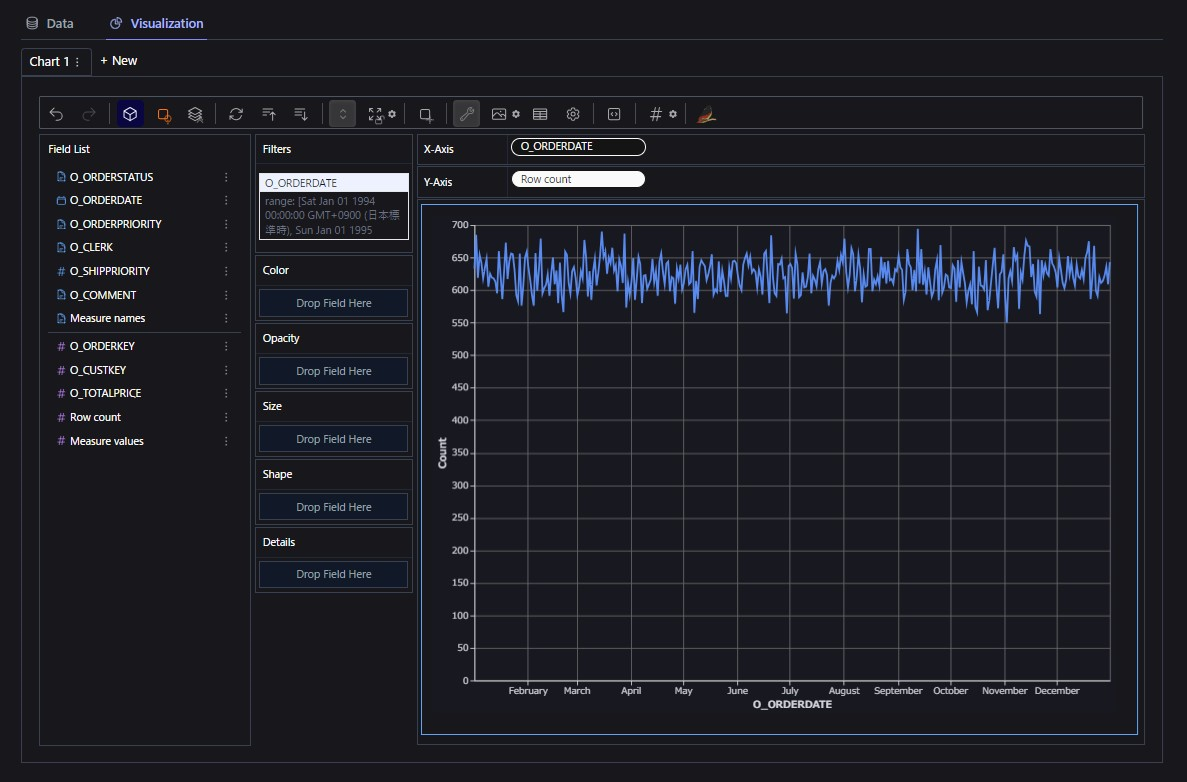
続いて、Snowsightで「アクティビティ」領域にある「クエリ履歴」を見てみましょう。
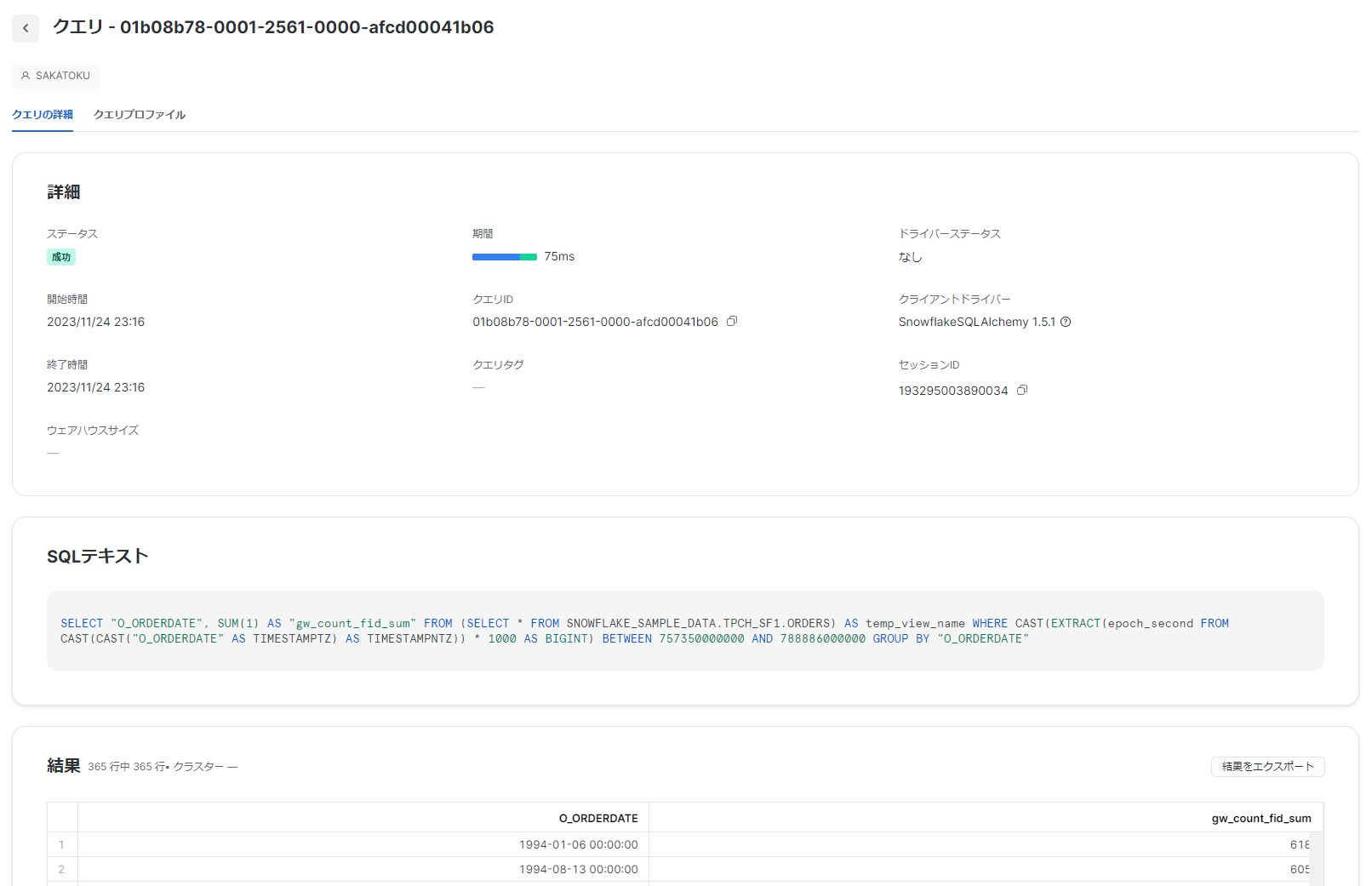
次のようなクエリが実行されていることが確認できました!
SELECT "O_ORDERDATE", SUM(1) AS "gw_count_fid_sum"
FROM (SELECT * FROM SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.ORDERS) AS temp_view_name
WHERE CAST(EXTRACT(epoch_second FROM CAST(CAST("O_ORDERDATE" AS TIMESTAMPTZ) AS TIMESTAMPNTZ)) * 1000 AS BIGINT) BETWEEN 757350000000 AND 788886000000
GROUP BY "O_ORDERDATE"
癖がありますが、WHERE句で日付範囲をフィルターして、GROUP BYとSUM(1)で行数を集計していることが確認できますね!
クエリの効率は少し怪しいですが、ともあれこれなら大規模なデータでもサクサク探索することができそうです。