以下の公式ドキュメントを試してみた、という記事です。Snowflakeにある程度慣れていれば公式ドキュメントを読むか、雰囲気で操作した方が早いです。
ウェブインターフェイスを使用したデータのロード
やりたいこと
ローカルにあるCSVファイルをSnowflakeにさっとアップロードしてデータ分析したい…というシチュエーションがあるかと思います。
以前はSnowSQLというCLIクライアントが必須でしたが、2023年4月からSnowflakeのWebインタフェースであるSnowsightからアップロードしてデータロードできるようになりました。(2023年8月時点でPublic Preview)
前提条件
以下の権限が必要です。より正確な情報は公式ドキュメントを確認してください。
| 対象 | 権限 |
|---|---|
| データベース | USAGE |
| スキーマ | USAGE |
| テーブル | OWNERSHIP |
試してみる:下準備
今回は構造化データ(CSVのような表形式のデータ)で試してみましょう。
権限を確認しておきたいのでお試し用のデータベースやユーザを作っておきます。
-- ウェアハウスを選択
USE WAREHOUSE COMPUTE_WH;
-- データベースを作成
CREATE OR REPLACE DATABASE UPLOAD_TEST;
-- スキーマを作成
CREATE OR REPLACE SCHEMA UPLOAD_TEST.UPLOAD_TEST;
-- テーブルを作成。今回は最初からデータ型が分かっている想定
-- やることは変わらないはずだが念のためにファイル形式別にテーブルを作る
CREATE OR REPLACE TABLE UPLOAD_TEST.UPLOAD_TEST.WORK_CSV (
id int primary key,
name varchar(16),
value1 int,
value2 int,
dt date
);
CREATE OR REPLACE TABLE UPLOAD_TEST.UPLOAD_TEST.WORK_TSV (
id int primary key,
name varchar(16),
value1 int,
value2 int,
dt date
);
CREATE OR REPLACE TABLE UPLOAD_TEST.UPLOAD_TEST.WORK_PARQUET (
id int primary key,
name varchar(16),
value1 int,
value2 int,
dt date
);
-- ロールを作成してユーザに割り当て
CREATE ROLE UPLOAD_TEST;
GRANT ROLE UPLOAD_TEST TO USER SAKATOKU;
-- データベースとスキーマの権限を作成したロールに付与
GRANT USAGE ON DATABASE UPLOAD_TEST TO ROLE UPLOAD_TEST;
GRANT USAGE ON SCHEMA UPLOAD_TEST.UPLOAD_TEST TO ROLE UPLOAD_TEST;
GRANT MODIFY ON SCHEMA UPLOAD_TEST.UPLOAD_TEST TO ROLE UPLOAD_TEST;
GRANT OWNERSHIP ON TABLE UPLOAD_TEST.UPLOAD_TEST.WORK_CSV TO ROLE UPLOAD_TEST;
GRANT OWNERSHIP ON TABLE UPLOAD_TEST.UPLOAD_TEST.WORK_TSV TO ROLE UPLOAD_TEST;
GRANT OWNERSHIP ON TABLE UPLOAD_TEST.UPLOAD_TEST.WORK_PARQUET TO ROLE UPLOAD_TEST;
-- データロードにはウェアハウスが必須
GRANT USAGE ON WAREHOUSE COMPUTE_WH TO ROLE UPLOAD_TEST;
-- 作成したユーザに切り替え
USE ROLE UPLOAD_TEST;
USE DATABASE UPLOAD_TEST;
USE SCHEMA UPLOAD_TEST;
今回は構造化データとしてランダム値を数万行並べたCSVファイル、TSVファイル、Parquetファイルを用意しました。
試してみる:Snowsightからデータロードする
ここからはGUIをポチポチしていきます。
なお、データロードするときはコンピューティングリソースを使うのでウェアハウスを選択しておく必要があります。
1. データロード先のテーブルを選択して「データをロード」

2. (日本語設定だと表示がズレていますが…)「閲覧」をクリック
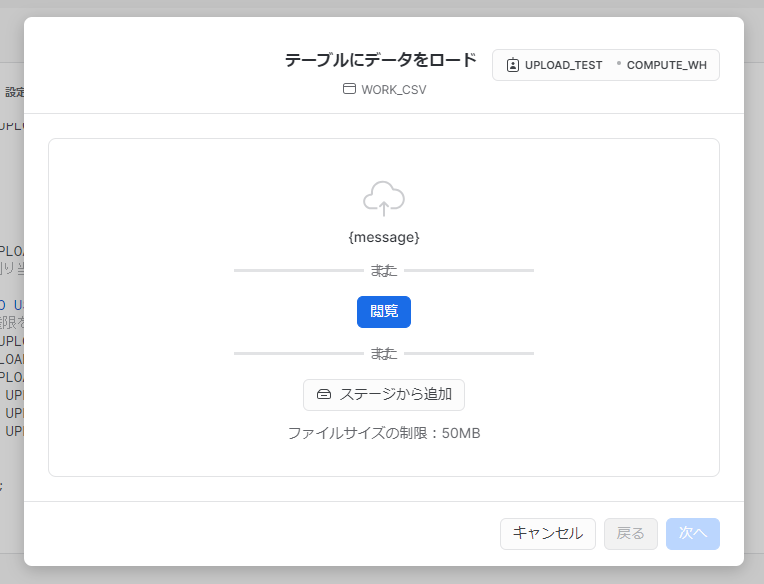
3. ファイルダイアログでファイルを選択
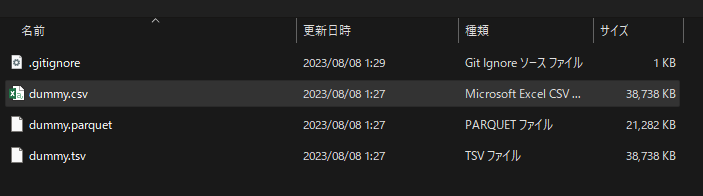
4. 選択したファイルのファイル名とファイルサイズが表示されるので確認したら「次へ」をクリック

プログレスバーが表示されてアップロードが始まるのでしばらく待ちましょう。
なお、Snowsightからデータロードするとき、最大50MBのファイルに対応しているそうです。

5. ファイル形式とエラーが発生したときの挙動を指定します。

対応しているファイル形式は以下の通りだそうです。
- CSV or TSV
- JSON
- Avro
- ORC
- Parquet
- XML
また、エラーが発生したときの挙動はABORT_STATEMENTとCONTINUEが選択可能でした。
これらのオプションについての詳細はCOPY INTOのON_ERRORオプションを参照してください。
参考:COPY INTO <テーブル> | Snowflake Documentation
6. データロード
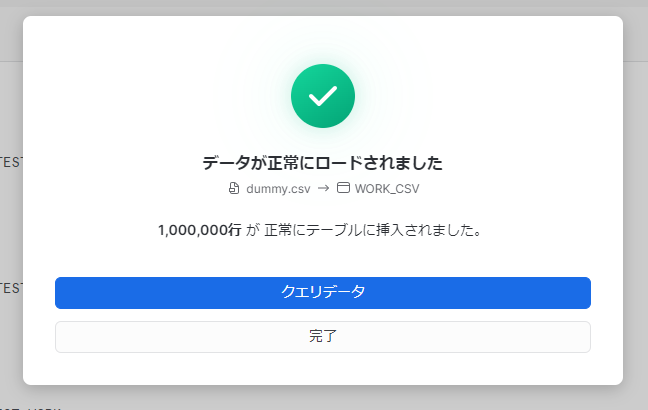
100万行、37MBのCSVファイルは最小のウェアハウスで10秒くらいでデータロードできました。
データロード先のテーブルに試しにクエリを実行してみると、問題なさそうです!

ファイル形式による差異
TSVファイルの場合はCSVファイルとほとんど差異はありません。
フィールド区切り文字を適切なものに変更するだけ。

Parquetファイルの場合はCSVファイルとはファイル固有のオプションが色々違います。こちらの方がシンプルですね。

ParquetファイルがGZIP圧縮されていても問題なくデータロードできます。オプションを指定する必要なし。
手元にgz.parquetのファイルがあることはあまりないかもしれませんが、GZIP圧縮するとたいてい4割くらいファイルサイズが小さくなるのでお得感ありますね。

その他
ファイル形式を指定するダイアログで「SQLを表示」というボタンを押してみると、以下のようなSQLを確認できました。
アップロードしたファイルはこういう場所に置かれているみたいです。
COPY INTO "UPLOAD_TEST"."UPLOAD_TEST"."WORK_CSV"
FROM '@"UPLOAD_TEST"."UPLOAD_TEST"."%WORK_CSV"'
FILES = ('__snowflake_temp_import_files__/dummy.csv')
FILE_FORMAT = (
TYPE=CSV,
SKIP_HEADER=1,
FIELD_DELIMITER=',',
TRIM_SPACE=FALSE,
FIELD_OPTIONALLY_ENCLOSED_BY=NONE,
DATE_FORMAT=AUTO,
TIME_FORMAT=AUTO,
TIMESTAMP_FORMAT=AUTO
)
ON_ERROR=ABORT_STATEMENT
PURGE=TRUE
