![]() この記事は2019年のラクスアドベントカレンダーの14日目になります!
この記事は2019年のラクスアドベントカレンダーの14日目になります!![]()
昨年から連続しての参加となります。![]()
よろしくお願いします。![]()
![]()
昨日は@rs_tukki氏のAndroidアプリで謎の接続エラーが発生した話 でした。
記事の内容は開発のこと、私はインフラエンジニア、ですが、エラーが発生した際の対応方法/確認すべきことなどの基本は職種によらず大変参考になります。(ことデフォルト値が絡む問題は厄介なことが多いので怖いですね・・・![]() )
)
さて、今日は少し毛色を変えてインフラの話をしましょう。
はじめに
改めまして、某インフラエンジニアです。
開発系のエンジニアが大勢を占めるこのQiita。やはりインフラエンジニアとしては意地でも開発に媚びないひねくれた内容を投稿したいと考えつつ、昨年は通信についてちょっと詳しく(物理寄り)という投稿をしました。
物理ケーブルは少しやりすぎたか、と思いつつも、2年目のアドベントカレンダーはさらに希少なところをせめてみます。
Ethernet Fabricについて。
Qiitaで検索するとなんと0件![]() 。(多分)私が初めて書きます。詳細を理解するにはネットワークの前提知識が結構必要でここでは書ききれないため、今回は軽く概念にふれる感じにしたいと思います。こんなのあるんだーって感じで興味を持ってもらえると幸いです。
。(多分)私が初めて書きます。詳細を理解するにはネットワークの前提知識が結構必要でここでは書ききれないため、今回は軽く概念にふれる感じにしたいと思います。こんなのあるんだーって感じで興味を持ってもらえると幸いです。
EthernetFabricとは
簡単に言うと、**「従来のコアネットワークにおける性能や運用面の課題を解決する新しい形のネットワーク技術」**になります。
しかしこれだけだとさすがに抽象的すぎるので、もう少し詳細を見ていきましょう。
まずはネットワークのループと回避方法について理解
EthernetFabricを語るにあたっては、まずネットワークにループが発生する状況を理解しないと概念すらも語れないため、その説明からします。少々退屈ですがお付き合いくださいm(_ _)m
ブロードキャストストーム
ネットワークの勉強をしたことがある人にとっては基本というか、まず最上級に気を付けるべきこととして有名ですが、以下のようにスイッチングハブ(L2の通信をするスイッチとかハブ)2台を2本のLANケーブルで接続したら、ネットワークは死にます。
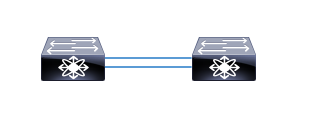
なぜか?
それは通信のループが発生するからです。
Ethernetの通信には特定の機器を宛先とした「ユニキャスト」という通信のほかに、接続されているPCやルータすべてを対象にした「ブロードキャスト」という通信方法があります。EthernetとTCP/IPを組み合わせたLANでは、IPアドレスに対応したMACアドレスを見つけるため、このブロードキャストが必ず使われます。
つまり、全ポートにぷっぱなす通信が必ず発生するため、2つのスイッチの間で往復できるような経路を作ってしまうと無限に行き来することになります。そしてそれは無限に増幅していく。
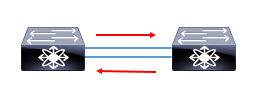
ネットワーク界隈ではこれを嵐に例えて**「ブロードキャストストーム」**と呼びます。ブロードキャストストームが発生したら最後、リソースを使い果たして通信などまともにできなくなります。こんな簡単なことでネットワークは死にます。個人的に所持しているもので試すのは構いませんが、会社等では絶対にやらないでくださいねw
ブロードキャストストームの回避方法
ではどうやってそれを回避するかですが、まず最も簡単な話をすると、ループする構成をつくらなきゃいいじゃん、2本でつなぐとループするなら1本で良くね?ということ。

![]() <これでええやんけ
<これでええやんけ
確かにそれだと物理的にループは発生しませんが・・・しかしケーブルが1本死んだら通信は不可能になります。ポートが壊れても然りです。ケーブルが壊れることなんてあるの?と思うかもしれませんが全然あります。材質などいろいろ違いますが例えばイヤホンなど長く使ってると音が聞こえなくなったりすることありますよね?ケーブルなんてそんなもんです。所詮。
これを2本つないで片方が死んでももう片方のケーブルで通信出来たら、とてつもなく不運でない限り通信が途切れることはありません。24時間365日サービスが提供されるのが当たり前のこの時代、単一障害で長時間ビジネスが止まることは絶対に避けねばなりません。ゆえに、2本以上で接続するのは絶対条件となります。
さて、言ってることが矛盾してきました。2本でつないだらループする。しかし冗長構成上2本でつなぐ必要がある。ということで、この状況を打破するためにネットワーク通信をプロトコルなどを使ってスイッチの中で制御する機能が存在します。有名どころでいうとSTP(スパニングツリー)やLAG(リンクアグリゲーション)などでしょう。ここではSTPを例に簡単に説明します。
STP(spanning tree protocol)
詳細を語ると中々にして手ごわいプロトコルなので、雑にイメージだけ説明します。
以下のような三角形で接続されているとします。
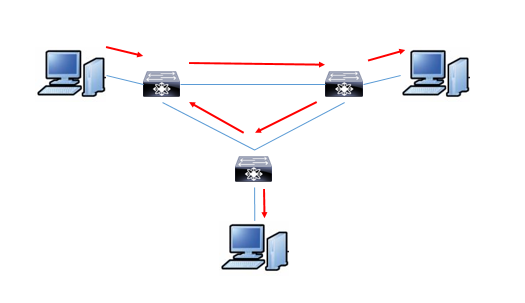
何の対策もしなけば図の赤矢印のように、真ん中が輪になっているため通信がループします。
そこにSTPを使いそれぞれのスイッチのプライオリティを設定すると、特定のポートがブロックされループしないようになります。
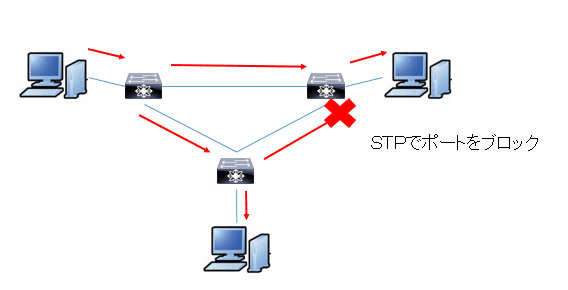
ここでどこかのケーブルが壊れたとします。そうすると、STPで経路の再計算を行い、ブロックしていたポートが解放されます。基本的には上記の図でどのケーブルが壊れても、スイッチ同士の通信が全断することはありません。(手で線を隠してみて経路が存在するか見てみてください)
こうやってネットワークは冗長化を維持しつつ経路変更を行いながら通信をしています。
実は複雑で非効率なネットワーク運用
さて、ループとSTPの説明をしましたが、今までの図はあくまで説明をわかりやすくするために非常に簡易化したものであり、実際データセンターや企業で使われるネットワークはもっと複雑なものとなります。
例えば以下は一般的なコア/ディストリビュータ/アクセスの三階層に分かれたネットワーク構造。
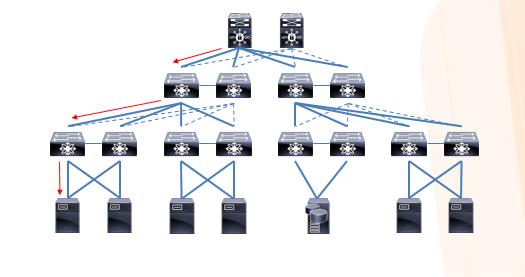
各スイッチがいろんな線で接続されていますが、(設定にもよりますが)STPで経路として実際使えるのは実線の部分で、点線の部分はブロックされます。一番左のサーバへの通信は赤線の経路になります。これだけ豪勢なネットワークを構成してケーブルがいっぱいつながってるのに、1サーバとの通信は1経路と、従来のネットワークは帯域的な面でも実は非常に効率が悪いです。
さらに、これらのネットワークの中には複数のVLAN(仮想的なネットワーク)が設定されていることが一般的で、そうなると、どこが切断された場合にどうSTPの経路が変わって、どのサーバとどのサーバの通信に使われているVLANがどうで・・・・と非常に複雑になります。
さらにさらに、ここで新たなビジネス要件が発生して、新たなVLAN追加/スイッチ追加が発生するとしましょう。いろいろ構造が変わります。当然サービスの停止時間は極力少なくメンテするとします。

ということで、とにかく既存のネットワークは複雑で非効率です。
Ethernet Fabricの登場
ここでようやくEthernetFabricが登場します。冒頭で述べたように、従来の複雑性や非効率といった課題を解決しようという概念がEthrtnetFabricです。これをどうやって実現しているかの実装自体は実はスイッチベンダー各社によって違っていたりしますが、おおむね特徴としては以下を備えます。
- 高スループット/広帯域である
- インテリジェントである(ファブリックを構成するスイッチ群にコントロールブレーンがいて、設定やMAC学習などを統合管理できる)
- 高可用性(スイッチが停止しても通信が止まらない。メンバーのスイッチが加わっても止まらない。)
- 互換性(当然既存のネットワークとハイブリッドも可能)
有名どころで言えば以下のようなベンダーがこれを実装しています。
- Avaya : Virtual Enterprise Network Architecture
- Brocade : Virtual Cluster Switching
- Cisco : FabricPath
- Juniper : QFabric
など・・
Ciscoの例で見てみましょう。

CiscoのFabricPathという機能を使うと、STPで使えなかった点線部分が全部通信できるようになります。
もう経路選択とかそういう概念捨てて、全経路どこを通ってもOKにしちゃえば、帯域実質4倍界王拳じゃん、って話です。なぜループしないかはスイッチにIDをふってルーティングのようなものをしているようですが、どうやってこんなことやるの?と考えるより、これができるプロトコルを無理やり作った、と考えた方がいいでしょう。
さらにどの経路を通ってもいいなら、どのケーブルが壊れてもどのスイッチが壊れても通信断は発生しません。
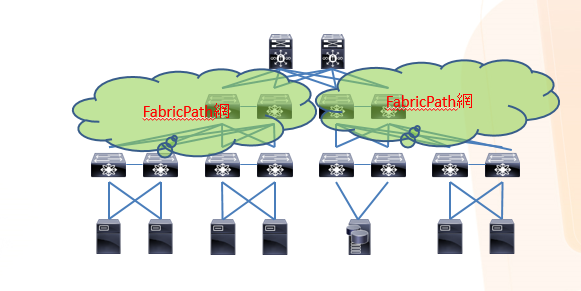
状態としてはこんな感じにとらえることができますね。まさにネットワークの仮想化です。
なぜEthernetFabricが必要なのか
ということで、EthernetFabricの概念というかイメージをお伝えしましたが、
なぜそもそもEthernet Fabricの概念が必要なのか、必要になったのか、生まれたのか。
あくまで個人の見解ですが、仮想化による物理サーバの集約、ハイパーコンバージドインフラのリソース統合など、従来の物理サーバを並べるだけのスタイルからシステム構成が色々と変わってきた昨今、ネットワークも従来の在り方そのままではついていけなくなってきてるためだと考えられます。
一極集中でサーバが集約されれば、当然そこに通信は集中するわけであって、ディスクが高速でサーバリソースが潤沢でもネットワークが詰まったら意味がありません。VM?コンテナ?効率いいサーバ運用してるみたいだけどネットワークは大丈夫!?みたいな。
サーバ技術ばかりが注目されていますが、ネットワークももっと効率よくなる必要があったわけです。
こういうネットワークのラインまでちゃんと全体構成を考えられるのがインフラエンジニア固有の強み![]() ではあるので、AWSなどのグローバルクラウドが猛威を振るってる昨今ネットワークなど触ったこと無いよってインフラエンジニアも、一度は勉強しておくことをお勧めします。
ではあるので、AWSなどのグローバルクラウドが猛威を振るってる昨今ネットワークなど触ったこと無いよってインフラエンジニアも、一度は勉強しておくことをお勧めします。
おまけ:時代はもっと先へ?
Ethernet Fabricからはずれた話になってしまいますが余談を。
先日Public keyで以下のような記事がありました。
https://www.publickey1.jp/blog/19/awsaws_reinvent_2019.html
AWS re:Invent 2019でAWSがTCPの通信を捨てて独自プロトコルでの高速化を実現しているとの話がありました。ハンドシェイクが通信上ネックになりうる点はよく言われていましたが、ほんとに捨てちゃったのね。世界はもっともっと先にいっているようですね。