はじめに
・自己紹介
AI未経験のエンジニア。
AIが身近になってきたことと、その将来性に興味があり学習を決意。
AIの知識は、新聞や書籍などで活用事例を少し知っている程度で技術的な知識はほぼ無いレベル。
Pythonは初めて(その他言語はそれなりに経験があるがプログラミングにはあまり自信なし)
本記事の内容
初めてAI(主にプログラミングなど技術的な内容)を学んだ際の経緯を記載しています。
同じくAIの勉強を始めてみようと思っている人の参考になれば幸いです。
学習振り返り
約3か月間の学習期間について振り返りたいと思います。
オンラインスクールのアイデミーで学びつつ、その他書籍等で学習しています。
1か月目
Pythonの基礎を学ぶ
まず、AIを実装するにあたって利用するPythonと利用するライブラリについて学びました。
【Python】
基本的な文法の理解 オブジェクト指向
【Numpy】
主にndarrayの使い方 多次元配列や行列計算を理解
【Pandas】
DataFrameの使い方 表形式のデータ操作方法、EXCELや簡単なDB操作に近い
【Matplotilb】
グラフで可視化する方法 EXCELに表示するグラフのように散布図やヒストグラム、円グラフなどをプログラミングで簡単に実現
【Scikit-learn】
機械学習モジュールの使い方 決定木やクラスタ分析など。
【前準備】
Pythonやライブラリの機能を用いて、データのクレンジング(欠損値の補完など)やスクレイピング(Webサイトからのデータ収集)など。
色々なライブラリがあるので少し身構えていたのですが、実際に触れてみるとそこまで複雑なものではなく、やはり自分の手でプログラミングしてみるのが一番早く理解できるとあらためて思いました。
並行してAIの基礎を学ぶ
機械学習とは?から、教師あり、なし、強化学習など、AIについての基礎を学びました。
AIで何ができて、何が向いていないのかなどの理解も深めました。
画像認識、時系列予測、自然言語解析などの分野がありますが、個人的には売上予測などに活用されている予測やクラスタ分析などに興味を持ちました。
2か月目
実際に画像の分類や機械学習の実装に取り組む
Scikit-learnを使って、SVMやランダムフォレストなどをグリッドサーチ、ランダムサーチなどを使って、比較検証などを実施。
例題を用いてディープラーニングもJupyterNotebookで実際にプログラミング。
グラフで精度を可視化しながら過学習の様子をチェックしつつ、ハイパーパラメータを調整して、モデルが学習されていく様子を見でみる良い経験になりました。
その傍らで、より深く知りたい範囲については、気になる書籍やUdemyで手を広げました。
AIの実装方法やライブラリの使い方などは、書籍やその講師によって異なるので、1つの情報源に偏ることなく、見比べてより良い方法を自分に取り入れていくことが大切だと実感しました。
また、せっかく学習したので「Python 3 エンジニア認定データ分析試験」を受験しました。(無事合格)
この試験は、「Pythonによるあたらしいデータ分析の教科書」という書籍が教科書に指定されており、ここから出題されます。スクールなどの学習とは別に教科書について学ぶ必要がありますが、基礎を理解できていればそこまでハードルは高くないと思います。
3か月目
AIを使った簡易的なWebアプリを実装。
時系列分析など自分の興味がある内容について自己学習。
作成したもの
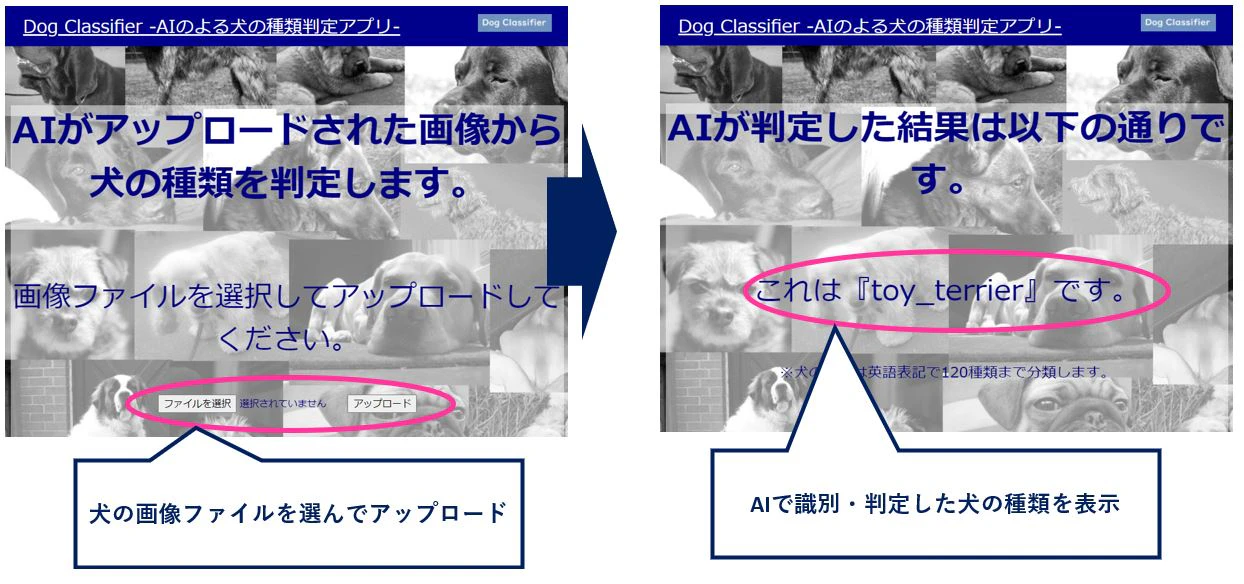
【概要】
アプリの仕様は以下のシンプルな機能のみ
1.写真をアップロードする
2.犬の種類をAIで判定(120種類まで分類)
3.結果を表示する
【環境】
・Windows10のPCでGoogle Colabで作成
・アプリの実行環境はHerokuの無料版を使用
・Pythonのバージョン:python-3.8.7
・主要なライブラリ
numpy==1.18.0
opencv-python==4.3.0.36
tensorflow-cpu==2.3.0
※Herokuのデプロイ時に500MBの制限がありました。
tensorflowを利用しているとサイズが大きすぎてエラーになるので、tensorflow-cpuを利用して解決しました(requirements.txtに記載)。これはGPU対応していないバージョンですが、CPUで動作する上では特に問題なく、サイズも半減できるのでサイズ制限をクリアしやすいです。
【モデル作成】
・犬の写真は「Stanford Dogs Dataset」を活用。
※収集&アノテーションから実施しようと思いましたが、時間の制約もあるため活用させてもらいました。その後、色々見ているとkaggleに同じデータが扱いやすいリストなどにまとまっていました。
・モデルはVGG16の転移学習で作成。
学習したモデルはHDF5形式で保存しアプリ側のPythonでLoadして使用。
■■■処理の流れ■■■
・ライブラリのインポート
・画像ファイル読み込み(GoogleドライブをGoogleColabにマウントして読み込み)
・正解ラベルをOne-Hotエンコーディング
・画像と正解ラベルの対応付け
これまでの学習ではきれいに準備されているDatasetばかり使っていたため少し悩みましたが、以下の手順でGoogleドライブの画像と正解ラベルを対応付けることができました。
im_size = 90 # 画像サイズ要調整
X_train_org = []
y_train_org = []
i = 0
for f, breed in tqdm(df_train.values):
img = cv2.imread('/content/drive/My Drive/dog-breed-identification/train/{}.jpg'.format(f))
label = one_hot_labels[i] # 前段でOne-hotエンコーディングした正解ラベル
X_train_org.append(cv2.resize(img, (im_size, im_size)))
y_train_org.append(label)
i += 1
・データの正則化と分割
・モデル作成(VGGの15層まで固定し、全結合層を追加してファインチューニング)
・モデルのコンパイル、学習
・アプリから呼び出すAIモデルの保存&ダウンロード(ここで完了)
GoogleColab等で勉強している時には特に意識していませんでしたが、アプリからAIモデルを呼び出すためにHDF5形式で保存しておくことができて便利でした。
import os
from google.colab import files
result_dir = 'results'
if not os.path.exists(result_dir):
os.mkdir(result_dir)
model.save(os.path.join(result_dir, 'param4dogclf.h5'))
files.download( '/content/results/param4dogclf.h5' )
【考察と反省】
精度は途中で断念したのでまだまだ改善の余地あり。(時間があったら改善予定)
約10000の画像データから学習、検証してモデルを作成しましたが、画像データの水増しをすることでより精度を上げられそうです。
ただ、ディープラーニングのモデルを作成するにはやはり時間が掛かることを身をもって経験したので(GPU搭載などマシンのスペックがあれば別だと思いますが)、もう少し分類する数を少ない数から(120ではなく10ぐらいから)試しても良かったかなと思いました。
ローカルのJupyterNotebookだとスペック的に学習の速度が遅く、GoogleColabだと画像のアップロードに時間が掛かったり、セッション切れで時間が無駄になったりと色々と苦労したので次回に活かしたいと思います。
その他には、今回はVGG16を使いましたが、今後はVGG19やInception V3など他のモデルを活用した転移学習についても比較検証したいと思います。
終わりに
実際に手を動かしてアウトプットを作るということで、何がきちんと理解できていて、何が理解できていないかがよく分かり、とても勉強になりました。
まだまだAI世界の入り口に入ったばかりですが、想像していたよりは「AI使う」ということはそこまでハードルが高くないのではと思いました。
AIと聞くと自分の世界とは遠い難しいものだと決めて付けていましたが、専門家や天才たちがいろいろな研究論文やライブラリをシェアしてくれているので、それらを使わせてもらうことで実際の生活や仕事に活用していきたいと思います。
ひとこと
プログラミングスクールを利用する場合は、専門実践教育訓練給付金を利用するとお得です。
プログラミングスクールは高額ですが、会社勤めで雇用保険を払っている人は、条件によっては半額以下に抑えることができるので確認されることをお勧めします。