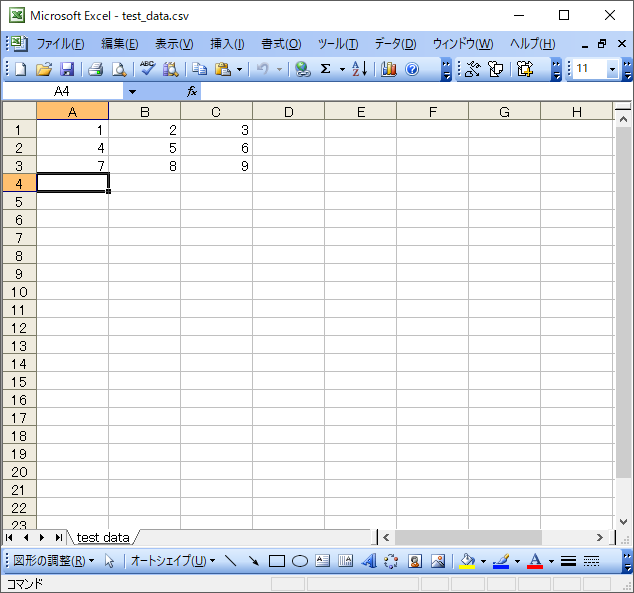
pandasとnumpyの組み合わせを試してみる。
すげえ・・・。強烈だ。マジすげえ。。。
実質数行でこんなことができてしまうのか。これをCで書こうと思うと気が遠くなる。
matrix_test.py
import numpy as np
import pandas as pd
import csv
'''CSVファイルの読み込み'''
csvdata = pd.read_csv("./test_data.csv", header=None)
csvdata2 = pd.read_csv("./test_data_2.csv", header=None)
'''CSVから読んだデータをnumpyの行列に入れる'''
myarray = np.array
myarray2 = np.array
myarray = csvdata.values
myarray2 = csvdata2.values
print(myarray)
print(myarray2)
'''行列の掛け算'''
result = myarray * myarray2
print(result)
'''結果の行列をCSVファイルに書き出し'''
with open("result_data.csv", "w") as f:
csv_w = csv.writer(f, lineterminator='\n')
csv_w.writerows(result)
ちなみに実行結果。各成分を2倍。
python .\vector_001.py
[[1 2 3]
[4 5 6]
[7 8 9]]
[[2 2 2]
[2 2 2]
[2 2 2]]
[[ 2 4 6]
[ 8 10 12]
[14 16 18]]
言わずもがなですが、CSVは普通のカンマ区切りデータ。エクセルで作った。