はじめに
みなさんはゲームの総プレイ時間などを気にしたことがあるでしょうか?
自分はSteamの「総プレイ時間」などを見るとニヤニヤしてしまう性分であり、Youtubeの総合視聴時間も調べたいと思いました。
しかしながらYoutubeの総視聴時間は、実は確認する方法がありません。
(Mobileでは直近7日間の視聴時間は確認できるが、総視聴時間は教えてくれない)
今回、どうにかしてYoutubeの総視聴時間を推定できないかと思い、以下の方法でプログラムを実装し、推定しました。
後半にコード、Githubのリンクを載せているので、自分のデータも推定してみては如何でしょうか。
動作環境・使用するツールや言語
- Python 3.9.x
- ライブラリ
- BeautifulSoup, matplotlib , lxml
やったこと
- Youtubeの視聴データ(watch-history.html)をエクスポートする
- 視聴データ(watch-history.html)から視聴日時のみを抽出
- 視聴日時の差を総和
1.Youtubeの視聴データ(watch-history.html)をエクスポートする
GoogleTakeoutにアクセス
Googleのアカウント関連のデータは、このサービスを使ってダウンロードできます。全てのデータをダウンロードすると膨大なデータ量になってしまうので、ここではYoutube->履歴のみを選択しました。
形式はhtmlで指定し、10分ほど待機してからダウンロード。
ダウンロードファイル内のwatch-hitory.htmlのみを今回扱います。
2.視聴データ(watch-history.html)から視聴日時のみを抽出
watch-history.htmlは一見するとごちゃごちゃしていて、複雑そうな構造をしていますが、実は
<div class="content-cell mdl-cell mdl-cell--6-col mdl-typography--body-1">
<a href="https://www.youtube.com/watch?v=abcdefg">動画のタイトル</a><br>
2025/07/15 10:35:38 JST
</div>
のようなフォーマットに従っています。そのため、
with open(path, encoding='utf-8') as f:
soup = BeautifulSoup(f, 'lxml')
entries = soup.find_all("div", class_="content-cell mdl-cell mdl-cell--6-col mdl-typography--body-1")
とすれば簡単に抽出できます。
BeautifulSoup(f, 'lxml') ではlxmlというパーサーを利用してhtmlを解析しています。標準のパーサーはhtml.parserですが、速度が断然違います。
3.視聴日時の差を総和
しかしながら、watch-history.htmlは、視聴開始時刻は保持しているものの視聴時間は保持していません。つまり、視聴時間は次の動画の視聴開始時刻 - 視聴開始時刻の総和で推定するほか方法がありません。
ここで問題になってくるのが、
- 次の動画を視聴するまで長時間空いていた場合(夜->朝など)
- 再生を途中で辞めていた場合
の状況において偽の視聴時間が加算されてしまいます。そのため一定時間以上間隔が空いた場合は「連続した視聴ではない」とみなし、視聴時間に含めないという対処が必要です。この「一定時間」が重要な変数になります。
これらを踏まえて実装しました。
from bs4 import BeautifulSoup
from datetime import datetime, timedelta
n_input = input("読み取る動画数は?(空で全件): ")
N = int(n_input) if n_input.strip() else None
D = 0.7 #一定時間(この例ならば、「0.7h以上動画を見ることはない」と仮定している)
path = 'watch-history.html'
with open(path, encoding='utf-8') as f:
soup = BeautifulSoup(f, 'lxml')
entries = soup.find_all("div", class_="content-cell mdl-cell mdl-cell--6-col mdl-typography--body-1")
watch_data = []
for i, entry in enumerate(entries):
a_tags = entry.find_all("a")
if a_tags:
title = a_tags[0].text.strip()
else:
title = "(タイトルなし)"
lines = list(entry.stripped_strings)
if lines:
watched_time = lines[-1]
else:
watched_time = "(日時不明)"
time_str1 = watched_time.replace(" JST", "")
fmt = "%Y/%m/%d %H:%M:%S"
try:
dt1 = datetime.strptime(time_str1, fmt)
except ValueError:
continue
watch_data.append([title, dt1, a_tags[0]['href'] if a_tags else None])
if N is not None and i == N:
break
total_duration = timedelta(0)
for i in range(len(watch_data) - 1):
curwatch = watch_data[i][1]
nextwatch = watch_data[i + 1][1]
delta = curwatch - nextwatch
if delta <= timedelta(hours=D) and delta > timedelta(0):
total_duration += delta
if len(watch_data) >= 2:
print(f"{watch_data[-1][1]}から{watch_data[1][1]}の視聴時間を推定します。")
else:
print("視聴日時が十分にありません。")
print(f"総視聴時間 (動画数:{N} ): {total_duration}")
show_links = int(input("視聴履歴を表示する?(0: No , 1: Yes): "))
if show_links == 1:
print("\n--- YouTubeリンク一覧 ---")
count = int(input("表示する件数を入力(空なら全件): ") or len(watch_data))
for i, (title, dt, url) in enumerate(watch_data[:count]):
print(f"{i+1}. {title} ({dt})\n {url if url else 'URLなし'}")
print("end!")
from collections import defaultdict
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
# 月ごとの視聴時間を格納
monthly_duration = defaultdict(timedelta)
for i in range(len(watch_data) - 1):
curwatch = watch_data[i][1]
nextwatch = watch_data[i + 1][1]
delta = curwatch - nextwatch
if timedelta(0) < delta <= timedelta(hours=D):
month = curwatch.strftime("%Y-%m") # 例: "2025-07"
monthly_duration[month] += delta
# 月ごとのデータをソート
months = sorted(monthly_duration.keys())
durations = [monthly_duration[month].total_seconds() / 3600 for month in months] # 時間に変換
# グラフ描画
plt.figure(figsize=(10, 6))
plt.bar(months, durations, color='mediumseagreen', edgecolor='black')
plt.xticks(rotation=45)
plt.xlabel("Year-Month")
plt.ylabel("WatchTime (h)")
plt.title("WatchTime Per Month")
plt.tight_layout()
plt.grid(axis='y')
plt.show()
- はじめに何件の動画データを扱うか問う
- 日時はdatetime型に変換してから引き算
- 「一定時間」は0.7時間(42分)として扱う(つまり、自分は42分以上動画を見ないという解釈)
- 最後に視聴履歴&月毎の総視聴時間を出力
といった感じです。
「一定時間」を0.7hとして扱うと、当然ながら42分以上動画を見ていた際の時間を無視してしまいます。(この値は必要に応じて変えてください。)
そのため、この総視聴時間は実際の値の「下限値」を示すものになります。
個人的には、ゲームのプレイ時間は「XX時間以下です」よりか「XX時間以上です」の方がデータとしては安心する
出力例
自分のwatch-history.htmlを解析した出力例を示します。
読み取る動画数は?(空で全件):
2024-12-16 23:57:57から2025-07-15 10:35:38の視聴時間を推定します。
総再生時間 : 39 days, 14:20:15
と約7ヶ月で950時間でした。自分は本格的にYoutubeを見始めた年は2018年頃であると記憶しているので、総視聴時間は11000時間(以上)くらいでしょうか。だいぶ見ている方ですね。
総視聴時間グラフは以下の通り
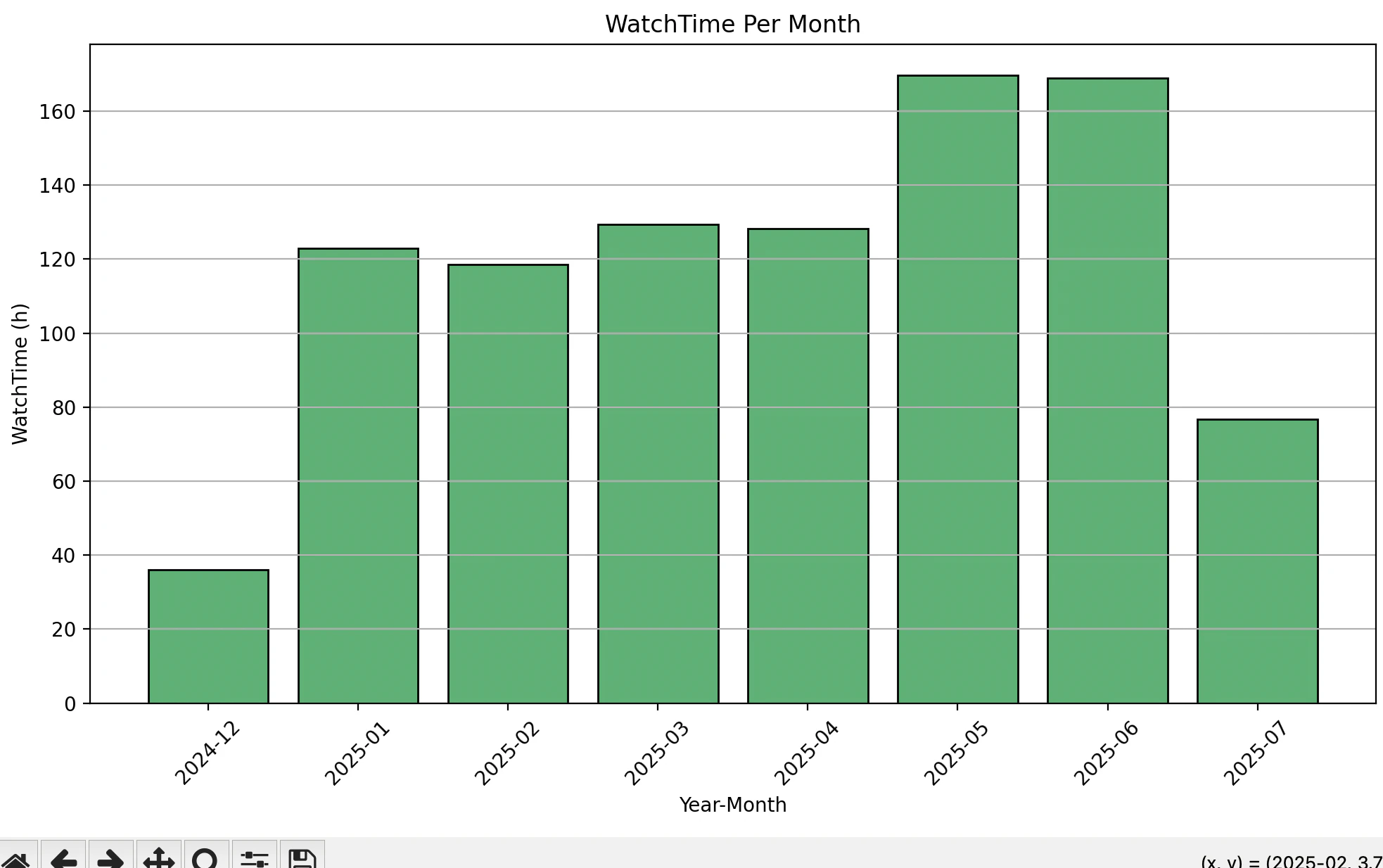
2024-12,2025-07の途中からのデータなので、両端は欠けています。
最後に、このデータの整合性を分析します。
4.Geminiを用いて整合性分析
100件のデータを読み込ませたときのこのプログラムの出力例は
読み取る動画数は?(空で全件): 100
2025-07-14 19:56:51から2025-07-15 10:35:38の視聴時間を推定します。
総再生時間 (動画数:100 ): 3:55:25
です。ここで100件の動画のリンク全てをGeminiに読み込ませ、動画時間の総和を計算したところ
合計: 4時間08分28秒
となりました。Geminiの値は上限値を与えるとはいえ、半日あたり約10分の誤差が生まれ、1月では5時間ほどの誤差範囲が存在することになります。
おわりに
誤差範囲が多くなる点については以下の対処法が挙げられます。
- 1.YoutubeAPIを用いて全ての動画の動画時間を総和し、上限値と下限値を用いての推定
- 2.「一時間耐久」など全視聴していないであろう動画をフィルタリングして除外
- 3.異常に長い or 短い時間間隔の動画に対しての手動確認
1.の方法に関しては莫大なお金がかかるので無理ですが、2,3については気が向いたらやろうかな。
にしても1万時間もYoutubeを見ているとは思わなかった。SNS恐るべし
最後に、Githubのリンクも載せておきます。みなさんもぜひ推定してみてください。
watch-history.htmlは、test.py(本プログラム)と同じディレクトリに配置してください。