最近、jumpstart触ったので備忘録です。
やったこと
- 学習済モデルを利用して、準備された画像の識別を行う
- 学習済モデルを利用して、準備された画像以外の識別を行う
- 学習済モデルを利用して、準備された画像以外の訓練、識別を行う
上記の通り、用意されているソリューションの利用は今回はありません。
あくまで、jumpstartの学習済モデルについて利用してみます。
結果まとめ
- 学習済モデルを利用して、準備された画像の識別を行う
- 問題なし
- 学習済モデルを利用して、準備された画像以外の識別を行う
- 問題なし
- 学習済モデルを利用して、準備された画像以外の訓練、識別を行う
- まだまだ精度は悪い。
準備された画像の識別
今回はよくあるRes18を利用します。
とりあえずは準備された画像の識別なので、そのままDeployします。
そこで準備されたノートブックの順番に実施します
- 例画像とクラスマッピングデータをダウンロード(Download example images and class_id_to_label_mapping)
- ダウンロードしたものをメモリに読み込む。ここで、自分の指定した画像も開けます。(Open the downloaded images and load in memory. You can upload any image from your local computer in the directory and open them here.)
- エンドポイントを作成し、画像を認識させる。(Query endpoint that you have created with the opened images)
最後の項目で、最初に出力した猫と犬の画像が識別されたことがわかります。

ここまでは何もしなくてもできるのであまり面白くないです。
準備された画像以外の識別
ここから、学習済モデルを使った遊んでいきます。
まず、ダウンロードされた「ImageNetLabels.txt」を開いてみると、いろいろラベルがあることがわかります。
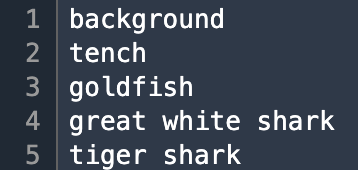
中を見てみるといろいろあるのですが、今回はクマ(bear)、しまうま(zebra)、ヒトデ(starfish)を対象にしてみます。
適当な写真をダウンロードしてきて、Sagemaker経由でアップロードします。
その上で、表示させてみます。
cat_jpg, dog_jpg,bear_jpg, starfish_jpg, zebra_jpg, ImageNetLabels = "cat.jpg", "dog.jpg", "bear.jpg", "starfish.jpg", "zebra.jpg" ,"ImageNetLabels.txt"
download_from_s3(key_filenames=[cat_jpg, dog_jpg, ImageNetLabels])
HTML('<table><tr><td> <img src="cat.jpg" alt="cat" style="height: 250px;"/> <figcaption>cat.jpg</figcaption>'
'</td><td> <img src="dog.jpg" alt="dog" style="height: 250px;"/> <figcaption>dog.jpg</figcaption>'
'</td><td> <img src="bear.jpg" alt="bear" style="height: 250px;"/> <figcaption>bear.jpg</figcaption>'
'</td><td> <img src="starfish.jpg" alt="starfish" style="height: 250px;"/> <figcaption>starfish.jpg</figcaption>'
'</td><td> <img src="zebra.jpg" alt="zebra" style="height: 250px;"/> <figcaption>zebra.jpg</figcaption>'
'</td></tr></table>')

表示できたら以下でメモリへ読み込みします。
images = {}
with open(cat_jpg, 'rb') as file: images[cat_jpg] = file.read()
with open(dog_jpg, 'rb') as file: images[dog_jpg] = file.read()
with open(bear_jpg, 'rb') as file: images[bear_jpg] = file.read()
with open(starfish_jpg, 'rb') as file: images[starfish_jpg] = file.read()
with open(zebra_jpg, 'rb') as file: images[zebra_jpg] = file.read()
with open(ImageNetLabels, 'r') as file: class_id_to_label = file.read().splitlines()
その上で、最後の項目を実施すると、以下の通り判定できていることがわかります。

もともとのラベルに記載があるものは判定が上手にされていることがわかりました。
準備された画像以外の訓練、識別を行う
今まではもともと登録されていたものをやっただけなので、精度がある程度出るのは想定通りです。
続いて、準備された以外の画像の訓練、識別を行って行きます。
そのままDeployするのではなく、下のFine-Tuningを選択していきます。
ここでいうFine-Tuningは、いわゆるファインチューニングではなく、どちらかというとファインチューニングとなります。
つまり、少量の画像を追加で学習することで、もともとあった画像に追加して自分の画像も認識できるようになります。
今回は私の好きなRaspberryPiを学習させてみます。
画像収集
面倒なんで、そのままSagemakerでクローリングしてS3へアップロードします。
# icrawlerインストール
!pip install icrawler
# クローリング(https://aiacademy.jp/media/?p=352)
from icrawler.builtin import BingImageCrawler
crawler = BingImageCrawler(storage={"root_dir": "rp100"})
crawler.crawl(keyword="RaspberryPi", max_num=100)
# S3 upload(https://dev.classmethod.jp/articles/sagemaker-python-sdk-s3/)
import sagemaker
# ダウンロードできたファイル分だけループ
for i in range(100):
fn = str(i).format(6)
# df.to_csv(f'rp100/{fn}.csv', index=False)
csv_dir_s3_uri = '<S3 Bucket>/rp/rp500/raspberrypi/'
sagemaker.s3.S3Uploader.upload(
local_path='./rp500/',
desired_s3_uri=csv_dir_s3_uri
)
sagemaker.s3.S3Downloader.list(csv_dir_s3_uri)
上記のコードでは100枚の画像をダウンロードしていますが、私の環境では枚数による違いがあるのか確認するために10枚、100枚、300枚で試してみることにします。
また、画像の配置については、以下の説明書き(deployの下にあります)をみると、ディレクトリの配下に、ラベル名のついたディレクトリを作成し、その下にファイルを配置するとありますので、ディレクトリ構造に気をつけます。
(これで何回か失敗しました。)

ファイルを配置したらfine-tuningのメニューからバケット等を指定します。
学習は10, 100, 300のいずれも5分以内に終わりました。
学習が完了したら、同じ画面からデプロイ実行します。
デプロイ完了したらOpenNotebookを開き、少し修正して実行します。
推論したい画像を、SageMakerへアップロードします。(今回はrp.jpegをアップロードしました)
# 項番1抜粋(rp.jpegを追記)
cat_jpg, dog_jpg, rp_jpeg, ImageNetLabels = "cat.jpg", "dog.jpg", "rp.jpeg", "ImageNetLabels.txt"
download_from_s3(key_filenames=[cat_jpg, dog_jpg, ImageNetLabels])
HTML('<table><tr><td> <img src="cat.jpg" alt="cat" style="height: 250px;"/> <figcaption>cat.jpg</figcaption>'
'</td><td> <img src="dog.jpg" alt="dog" style="height: 250px;"/> <figcaption>dog.jpg</figcaption>'
'</td><td> <img src="rp.jpeg" alt="rp" style="height: 250px;"/> <figcaption>rp.jpg</figcaption>'
'</td></tr></table>')
# 項番2抜粋(rp.jpegを追記)
images = {}
with open(cat_jpg, 'rb') as file: images[cat_jpg] = file.read()
with open(dog_jpg, 'rb') as file: images[dog_jpg] = file.read()
with open(rp_jpeg, 'rb') as file: images[rp_jpeg] = file.read()
# 項番3はそのまま
出力したところ、tenchで出力されてしまいましたのでNGですね。。。
また、猫や犬についてもtenchになってしまっているので、モデル自体が壊れてしまっているようにも見えます。。。

私は10, 100, 300枚でやりましたが、全て同じ結果(tenchになる)でした。
fine-tuningについてはまだ厳しいのかなぁという感触ですね(個人で画像を用意するなら300枚が限界かなぁと)
おわりに
jumpstartは全体的に便利だなと思いつつも、まだまだ私レベルでは使いこなしきれないなと思いました。。。